- @2301_82241942
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新需要这份系统化资料的朋友,可以戳这里获取升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**由于文件比较多,这里只是将部分目录截图出来,全
— || 1)Hadoop 创始人 Doug Cutting ,为 了实 现与 Google 类似的全文搜索功能,他在 Lucene 框架基础上进行优化升级,查询引擎和索引引擎。2)2001 年年底 Lucene 成为 Apache 基金会的一个子项目。3)对于海量数据的场景, Lucene 框 架面 对与 Google 同样的困难, 存 储海量数据困难,检 索海 量速度慢。4)学习和模仿 Goo

今天我们复习了面试中常考的Hive相关的五个问题,你做到心中有数了么?其实做这个专栏我也有私心,就是希望借助每天写一篇面试题,督促自己学习,以免在吹水群甚至都没有谈资!对了,如果你的朋友也在准备面试,请将这个系列扔给他,这几天由于参加学校活动,到上海参观互联网企业,一直没时间写,让大家久等了在这里说声抱歉。。。打卡。给同学们以激励。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习

今天我们复习了面试中常考的Hive相关的五个问题,你做到心中有数了么?其实做这个专栏我也有私心,就是希望借助每天写一篇面试题,督促自己学习,以免在吹水群甚至都没有谈资!对了,如果你的朋友也在准备面试,请将这个系列扔给他,这几天由于参加学校活动,到上海参观互联网企业,一直没时间写,让大家久等了在这里说声抱歉。。。打卡。给同学们以激励。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习
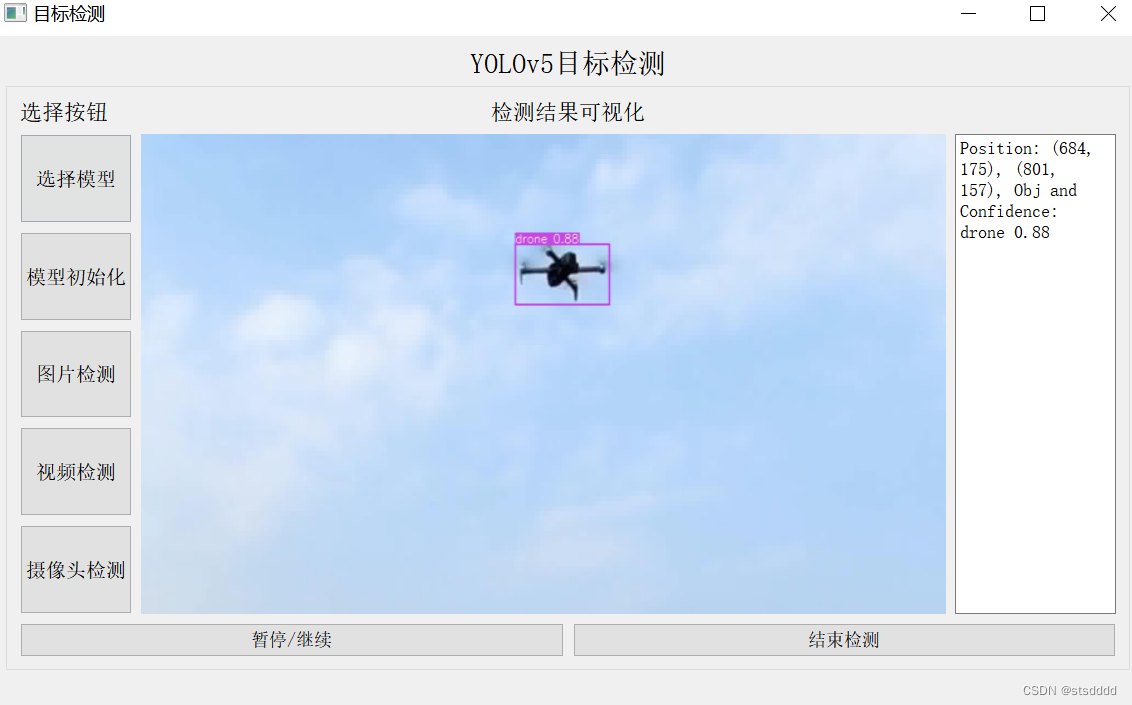
1、YOLO行人跌倒检测数据集,7500多张使用lableimg标注软件,标注好的真实场景的高质量图片数据,图片格式为jpg,标签有两种,分别为VOC格式和yolo格式,分别保存在两个文件夹中,可以直接用于YOL摔倒的行人识别,可以区分和识别到跌倒的行人和正常的行人,数据场景丰富,类别名为跌倒fall和正常状态的行人person,一共两个类别。从自动驾驶KITTI数据集中提取得到,类别为car,标
大数据是由云计算技术支撑,对海量数据进行推测预演的技术。大数据局意义是通过关联找到规则,有数据可说,说数据可靠。大数据有四大特征:体量大:数据规模十分庞大,根据新摩尔定律每十八个月翻一倍价值高:数据的价值密度低但有巨大潜在价值速度快:随着计算机和网络技术的发展,数据采集,储存,分析,处理的速度越来越快种类多:数据来源广、维度多、关系杂。
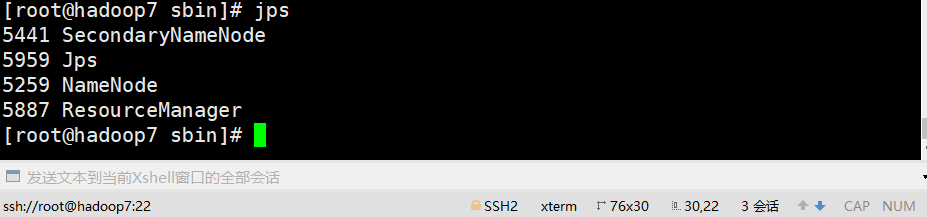
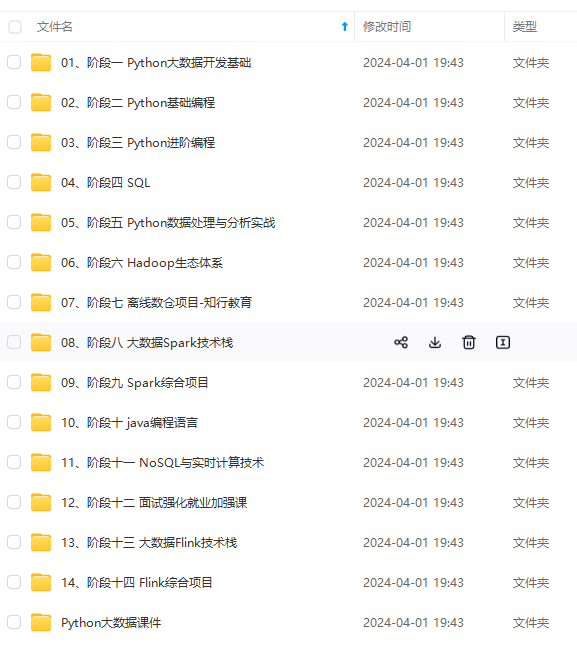
【代码】大数据应用——HDFS常用命令_hdfs cat命令。
和b站up主秋葉aaaki的分享:https://www.bilibili.com/video/BV17d4y1C73R/
主机hadoop7从机hadoop8从机hadoop9在浏览器中查看hdfs和yarn的web界面ip地址:50070ip地址:8088将spark压缩包上传到Linux的/usr/local目录下并解压。2、文件配置切换到spark安装包的/conf目录下,进行配置。使用cp命令将配置文件复制一份,原文件备份配置slaves文件:配置spark-defaults.conf文件:hadoop7:h