- @weixin_31588979
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
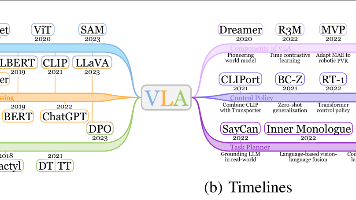
摘要: 本文综述了视觉-语言-动作(VLA)模型在具身智能(Embodied AI)领域的研究进展,系统梳理了其架构、分类与关键技术。VLA模型通过融合视觉、语言与动作模态,支持机器人完成复杂任务,其核心架构包含视觉编码器、语言编码器、模态对齐与动作解码器。论文提出三层分类体系:1)关键组件(如强化学习、世界模型);2)低层控制策略(包括扩散模型与大规模VLA);3)高层任务规划方法(单体式与模块
摘要: Claude Code是Anthropic推出的终端原生AI编程代理工具,专注于本地项目深度协作开发。它支持本地运行,拥有文件读写、终端执行、Git操作等权限,依托百万级超长上下文窗口,能全面理解并操作整个代码仓库。核心功能包括:项目架构拆解、全链路代码生成、跨文件重构、深度排错、自动化测试、文档生成、Git流程管理、运维脚本执行和安全审计等。相比同类工具,Claude Code在全局理解
近期AI领域迎来密集开源与模型更新潮。Cognition发布SWE-1.6预览版,性能提升11%;千问团队开源Qwen3.5系列四款小型模型;阶跃星辰开源Step 3.5 Flash及训练框架;小红书推出FireRed-OCR模型,文档处理准确率达92.94%。此外,通义实验室发布两款语音模型,IQuestLab开源代码模型系列,Jan团队推出轻量级编程助手Jan-Code-4B。OpenClaw
本文梳理了2026年十大核心LLM训练数据集,涵盖网络语料、知识库、指令集等类型。重点数据集包括:Common Crawl(多PB级原始网络数据)、C4(750GB清洗英文语料)、RedPajama(1000亿词元复现LLaMA数据)、RefinedWeb(6000亿词元高质量网络文本)和The Pile(825GB多样化综合语料)。这些数据集支持从基础预训练到指令微调的全流程,多数采用开源许可,
2026年小型LLM训练项目指南精选了14个适合不同学习阶段的模型,从入门级的26M参数MiniMind(仅需3元成本)到实用的1B级别模型。推荐学习路径:先通过nanoGPT理解基础架构,再用MiniMind体验全流程训练,最后进阶到TinyLlama等更大模型。特别推荐中文专用方案如baby-llama2-chinese,并提供了项目对比表帮助选择。这些小型LLM训练成本低、速度快,是掌握大模

近期AI领域迎来密集更新,涵盖视频生成、智能体、3D建模、编程辅助等方向。剪映Seedance 2.0提升生成效率,云知声U2大模型以任务闭环能力见长。技术突破方面,高德ABot-Earth-0.5实现文本生成3D城市场景,智谱SCAIL-2革新角色动画流程。开源生态持续繁荣,Cohere、腾讯、月之暗面等机构分别释放编程、多模态强化学习等领域的开源模型与框架。实时交互成新趋势,谷歌Gemini
近期AI领域迎来密集更新,涵盖视频生成、智能体、3D建模、编程辅助等方向。剪映Seedance 2.0提升生成效率,云知声U2大模型以任务闭环能力见长。技术突破方面,高德ABot-Earth-0.5实现文本生成3D城市场景,智谱SCAIL-2革新角色动画流程。开源生态持续繁荣,Cohere、腾讯、月之暗面等机构分别释放编程、多模态强化学习等领域的开源模型与框架。实时交互成新趋势,谷歌Gemini
系统创新:Dexora 是首个开源的原生支持双臂、双手、36-DoF 高自由度灵巧操作的 VLA 系统,填补了现有 VLA 模型的能力空白。数据管线创新:提出 “外骨骼 + Apple Vision Pro” 混合遥操作,结合 MuJoCo 虚实孪生,高效构建虚实互补的大规模双臂灵巧操作数据集。训练算法创新:设计数据质量判别器 + 加权损失的训练方案,有效解决遥操作数据噪声问题,提升动作平滑度与任

本文摘要:多模态大模型(MLLM)与语言大模型(LLM)的核心区别在于架构、数据和应用能力。架构上,MLLM在LLM基础上新增模态编码器和投影器,支持文本、图像、音频等多模态输入;训练数据上,MLLM依赖跨模态配对数据(如图文对),并需平衡多模态与纯文本数据比例;应用能力上,MLLM擅长跨模态信息整合任务(如医学影像诊断、OCR理解),但在纯文本任务和单点视觉任务上可能弱于LLM和专用模型。MLL
Qwen-VL系列模型在多模态领域持续创新,其演进路径涵盖视觉编码器优化、位置编码统一、训练范式改进等关键技术。Qwen2-VL引入M-RoPE统一处理文本/图像/视频位置编码,采用三阶段训练(预训练+多任务+指令微调)。Qwen2.5-VL通过绝对坐标提升检测精度,动态FPS采样增强视频理解,并融合SFT与DPO优化。Qwen3-VL进一步创新,提出MRoPE-Interleave和DeepSt