登录社区云,与社区用户共同成长
邀请您加入社区
这篇文章整理了一份系统架构设计师考试的核心考点速记口诀,涵盖了分布式系统、微服务、数据库、缓存、安全等15个关键知识点。主要内容包括:CAP定理和BASE理论、分布式事务解决方案、微服务拆分原则、负载均衡算法、缓存三大问题处理、Redis数据类型、MySQL索引优化、事务隔离级别、安全漏洞防范、常用设计模式、SOLID设计原则、高可用架构设计、云原生技术等。文章还提供了考试时间分配和答题技巧建议。
时光胶囊App采用单页多Tab架构,首页包含时间线、封印、统计、设置四个功能模块,共享底部导航和主题系统。通过分组管理20个@State变量实现各Tab状态独立,切换时保留未保存数据。采用if-else条件渲染而非Tab组件提升性能,主题系统支持四种配色方案并通过Preferences持久化。数据库层统一管理胶囊数据,各Tab按需刷新。该设计实现了功能模块的高内聚低耦合,兼顾用户体验与开发维护效率
Apache Atlas 2.4.0 元数据事务一致性保障机制摘要(150字) Apache Atlas 2.4.0 通过分层事务模型保障元数据一致性:HBase图存储采用JanusGraph强事务,Solr索引通过同步更新+异步重试实现最终一致性。核心机制包括:1)事务拦截器管理HBase操作原子性;2)索引更新失败触发事务回滚并进入重试队列;3)定时任务自动修复不一致索引。该架构有效解决了电商
本文深度解析了Apache Atlas 2.4.0全量标签与分类信息导出的三种生产级方案,并以IoT设备元数据治理为案例说明实施路径。核心内容包括: 问题背景:工业物联网平台面临GDPR合规审计需求,需导出所有含PII标签的设备指标清单。 存储原理:Atlas将分类信息作为Entity的边存储在JanusGraph(HBase)中,每条边包含分类属性。 方案对比: REST API分页查询:适合小
返回集合中唯一的元素,或满足条件的唯一元素,如果没有则返回默认值,如果有多个则抛出异常。: 返回集合中唯一的元素,或满足条件的唯一元素,如果没有或有多个则抛出异常。: 返回集合中的第一个元素,或满足条件的第一个元素,如果没有则返回默认值。: 返回集合中的第一个元素,或满足条件的第一个元素。: 检查集合中是否存在任何满足条件的元素。: 根据指定的条件筛选集合中的元素。: 返回集合中某个字段的最大值。
本文介绍了C#中用于序列扩展和元素计数的常用方法,包括Append/Prepend、Count/LongCount和TryGetNonEnumeratedCount。这些方法可以在不修改原集合的前提下扩展序列或统计元素数量,其中Append/Prepend的时间复杂度为O(1),而Count方法对ICollection<T>为O(1),其他序列为O(n)。文章还提供了性能优化建议,如优
本文介绍了LINQ中的集合转换与创建操作,主要包括: 集合转换方法:ToArray()/ToList()用于将序列转换为数组或列表;ToDictionary()将序列转换为字典,支持快速键查找;ToHashSet()用于去重和快速元素检查。 查询类型切换:AsEnumerable()和AsQueryable()用于在客户端内存和数据库查询之间转换执行上下文。 序列创建方法:Range()生成连续整
本文介绍了DataTable与LINQ的互操作方法。主要内容包括:1) DataTable转LINQ查询的AsEnumerable扩展方法及其应用;2) LINQ结果转DataTable的CopyToDataTable方法;3) DataRow的Field和SetField扩展方法;4) 常见LINQ to DataTable操作,如条件查询、分组、连接查询等。文中提供了多个示例代码,演示了如何实
以下代码不能完成全字段去重,因为people是引用类型,Distinct() 一般用于List<string>,List<int>这些值类型去重,而不涉及引用类型的字段比较。若需要全字段去重:1.使用DinstinctBy语法,加上所有字段。2.使用标题四的封装方法(反射实现全字段去重)。以上就是C#使用Linq实现简单去重处理的详细内容。
本文总结了C# 8.0到14.0版本中的20个关键面试题及解析,涵盖可空引用类型、异步流、记录类型等核心特性。重点解析了各项技术的设计动机、应用场景和优势,如可空引用类型提升代码安全性,异步流优化数据获取效率,记录类型简化不可变对象实现等。文章通过技术要点详解和形象比喻(如"懒人神器"、"智能门锁"),帮助开发者深入理解C#新特性,为面试和技术提升提供实用参
orderby:用于排序,升序或者降序 descending。降序排列,ascending升序,默认就是升序。where用法主要是做筛选条件使用。
Language-Integrated 查询(LINQ)是基于将查询功能直接集成到 C# 语言的一组技术的名称。传统上,针对数据的查询表示为简单字符串,无需在编译时进行类型检查或 IntelliSense 支持。使用 LINQ 时,查询是一流的语言构造,就像类、方法和事件一样。通过使用查询语法,可以使用最少的代码对数据源执行筛选、排序和分组作。使用相同的查询表达式模式从任何类型的数据源查询和转换数
泛型是C#中的核心特性,通过将类型参数化解决代码重复与类型安全问题。在泛型出现前,开发者需为每种类型编写重复代码或使用object类型(导致装箱拆箱和运行时错误)。泛型在运行时动态生成具体类型,提供类型安全、高性能(避免装箱拆箱)和代码复用三大优势。使用泛型包括消费现有泛型(如List<T>)和创建自定义泛型类/方法,通过约束(如where T : IComparable)限制类型参数
摘要 本文针对Apache Atlas 2.4.0缺乏Trino/Presto原生Hook支持的问题,提出手动构建数据血缘关系的解决方案。通过剖析Atlas的血缘模型核心原理(基于"Process"实体的三元组结构),详细演示如何利用REST API实现跨系统血缘追踪。 以电商场景为例,展示从Kafka主题、Hive表到ClickHouse表的完整血缘构建流程,包括: 前置实体创建与GUID获取
【代码】C#使用linq将数据进行分页。
优质博文:IT-BLOG-CN【需求】:生产者发送数据至 kafka 序列化使用 Avro,消费者通过 Avro 进行反序列化,并将数据通过 MyBatisPlus 存入数据库。【1】Apache Avro 1.8;【2】Spring Kafka 1.2;【3】Spring Boot 1.5;【4】Maven 3.5;二、Avro 文件【1】Avro 依赖于由使用JSON定义的原始类型组成的架构。
LINQ(Language Integrated Query)是C#中的强大功能,它允许以声明式方式查询数据源(如集合、数据库或XML)。Lambda表达式则提供简洁的匿名函数语法,常用于LINQ查询中定义操作。所有数学相关表达式(如集合操作)将使用$...$格式表示,确保清晰易懂。推荐练习:实现一个LINQ查询,从对象列表中过滤并转换数据(如计算员工的平均工资)。Lambda表达式是匿名函数,用
某省级电网通过流处理将审计效率提升40倍,年故障损失减少$120万,日志存储成本降低60%。技术栈:Java 17 + Quarkus + InfluxDB。电网系统产生海量实时数据(如设备状态、用电负荷、故障信号)和操作日志(如开关操作、权限变更)。传统批处理难以满足实时性要求,而Java流处理(
Override// 平方累加count++;// 计算RMS。
电网故障需在毫秒级定位并隔离,传统方法存在延迟高、人工依赖强等问题。Java流处理技术(如Apache Flink/Kafka Streams)可实时处理传感器数据流,实现快速响应。$$ \text{恢复时间} \propto \frac{\text{状态大小}}{\text{吞吐量}} $$:实际部署需结合SCADA系统,通过OPC-UA协议与物理设备交互,确保指令安全可靠。
根据实时电价 $p(t)$ 调整负载 $$E_{\text{save}} = \int_{t_1}^{t_2} (L_{\text{base}}(t) - L_{\text{adjusted}}(t)) dt$$此系统已在某省级电网部署,日均处理 $2.1 \times 10^{9}$ 个数据点,降低故障响应时间至传统系统的 $30%$。:基于LSTM的故障预测模型 $$h_t = \sigma(
Java流处理框架通过高效的数据流水线技术,为电网日志分析提供关键支撑。复杂事件处理模式,提升规则变更灵活性。建议将业务规则抽象为。机制处理乱序数据,同时需建立。:在电网日志处理中优先采用。
C++的模板与类型系统为开发者提供了一套独特的元编程工具——在编译阶段利用类型参数化机制,将逻辑决策从运行时迁移至编译期。其核心思想在于:以类型为变量,模板实例化为函数,编译器生成代码的过程即为程序的执行过程。通过模板与类型系统的深度开发,C++开发者正在突破传统编程范式的边界,构建出既保持静态类型安全,又能实现代码生成自动化的新型编程范式。元编程的突破性价值在于其对类型作为计算元素的运用。| 类
在 Kafka Consumer 中,正确处理 Offset 提交至关重要。
本文介绍了C#中两种实用的数据排序方法:1. List自带的Sort方法,通过传入比较函数实现原地排序,会改变原列表顺序;2. LINQ的OrderBy/OrderByDescending方法,生成新排序列表而不改变原数据,但会占用额外内存。两种方法都支持对复杂对象(如struct)按指定属性(如Confidence)排序,文中提供了完整示例代码演示如何对包含检测结果的列表进行降序排序。前者适合需
在 C# 中,是 .NET 提供的一套强大而统一的,让你可以用类似 SQL 的方式,(如数组、列表、数据库、XML 等)。。
本SpringBoot后端服务实现了与前端JavaScript SDK的无缝集成,通过Kafka异步处理支撑1万并发用户场景,同时利用MyBatis Plus管理运营元数据,确保系统的高性能和高可靠性。整个系统遵循"采集→传输→处理→存储→展示"的数据流动模式,针对1万并发用户的高并发场景,系统采用分层架构设计确保性能、可靠性和可扩展性。该前端SDK实现完全遵循系统架构规范,确保在1万并发用户场景
2025 年,让 Agent 实际投产、落地应用的最大障碍已经不再是成本问题了,而是「质量」。如何让 Agent 输出可靠、准确的内容,仍然是最难的部分。
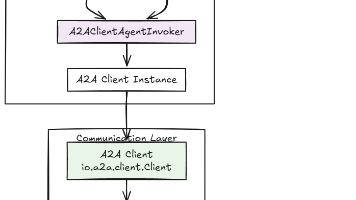
LangChain4j的A2A机制实现智能体间远程通信,支持分布式智能体系统构建。文章详解了A2A架构设计、Agent注册发现机制、动态代理实现、通信协议及安全认证机制。提供声明式和编程式两种客户端创建方式,结合SPI和服务提供者模式实现可插拔架构。A2A使开发者能轻松构建复杂智能体协作系统,适用于微服务化智能体架构和跨系统协作场景。
本文解析了OpenClaw团队在多Agent协作场景下采用事件溯源架构的设计思路。传统消息系统(如Kafka)存在三大不足:消息语义粒度不足、持久化要求不匹配和消费模式不兼容。OpenClaw的解决方案采用三层架构:1)命令总线层处理Agent意图;2)事件存储层作为只追加的持久化日志,维护完整因果关系链;3)聚合视图层通过回放事件重建状态。该设计解决了串行处理慢、系统耦合度高、失败难处理等问题,
在函数式语言发展起来之后,有些人发现函数式语言的抽象能力非常强,甚至能够直接用函数式语言的代码来表达文法的产生式,并将解析器“组合”出来,这称作解析器组合子(parser combinator)。解析器组合子的基本思想是“组合”,首先我们要定义一些最基本的产生式作为基础组合子,然后通过组合的方式拼装出最终的解析器来。这个组合子接受一个Token作为参数,而返回的解析器从输入的Scanner中读取下
按照刚才分析的,是不是只要给自己的类型提供几个方法就行了呢?动手吧!我们先来实现 select 和 where 关键字吧~先看看 .net 源码中的函数吧,这样我们才能知道这个函数需要传入什么,需要返回什么。12345678910namespacepublicstaticclassEnumerablepublicstaticthispublicstaticthis这里不用看具体的实现,只要看传入的
namespace 委托Test//使用匿名方法来求偶数//});//使用Lambda表达式求偶数。
在 C# 中,是 LINQ 提供的一个扩展方法,用于对集合中的元素按指定字段进行降序排序。排行榜系统数据统计商品价格排序UI列表展示游戏分数排行配置数据筛选set;set;set;set;new PlayerVip = 1},new PlayerVip = 3},new PlayerLevel = 9,Vip = 0按等级降序$"playerName。
本地消息表是一种基于数据库事务保证消息可靠投递的最终一致性方案。把业务操作和消息记录放在同一个数据库事务里,利用 ACID 特性保证原子性。│ 本地消息表方案 ││ ││ │ 业务服务 │ ││ │ │ ││ │ ┌─────┐ │ 同一个事务 ││ │ │业务表│◄─┼──┤ INSERT INTO 业务表 │ ││ │ └─────┘ │ │ INSERT INTO 消息表 │ ││ │ │消
前置条件:ZooKeeper 集群 + Kafka 集群已启动(3个ZK节点 + 3个Broker) Broker 地址:172.17.0.7:9092, 172.17.0.7:9093, 172.17.0.7:9094。
linqable 是一个 TypeScript 优先的前端集合操作库,借鉴 C# LINQ 风格,为数组、Set、Map 等数据结构提供链式查询能力。它解决了原生数组方法在复杂业务场景下的不足,如中间数组过多、多级排序繁琐、分组连接困难等问题。通过 from() 包装数据源,支持 where、select、orderBy 等流畅 API,最后通过 toArray() 等方法获取结果。该库零依赖、类
摘要: 本文系统讲解C#中的LINQ技术,通过对比传统循环写法,突出LINQ在代码简洁性、可读性和性能上的优势。文章详细介绍了LINQ的两种语法(方法语法和查询语法),并基于学生数据集合演示了Where筛选、OrderBy排序、Select投影、First取首条等核心操作。特别深入讲解了GroupBy分组查询等高阶功能,最后展示了企业级链式编程写法。全文采用实战导向,帮助开发者快速掌握这一.NET
本文介绍了高并发场景下Kafka写入性能优化的解决方案。通过某电商大促案例,揭示了同步发送消息导致CPU飙满、消息堆积的问题根源。核心优化策略采用异步写+写聚合方式,将多条消息批量发送,大幅提升吞吐量。文章详细讲解了Kafka Producer关键参数配置,包括批量发送大小、等待时间、压缩算法等,并提供了批量消息发送器的实战代码示例。该方案成功将Kafka吞吐量从1万/秒提升至10万/秒,有效应对
摘要:本文针对地铁ISCS综合监控系统的权限管控需求,提出基于SpringSecurity与自定义RBAC五表模型的工控专属解决方案。系统需隔离OCC调度中心、车站运维等多岗位权限,并实现跨线路/车站数据物理隔离。方案通过用户-角色-菜单绑定、接口+页面双重校验,划分超级管理员、调度员、车站运维、只读访客四级角色,满足工控内网离线部署与高安全要求。在不修改原有业务架构(OPCUA采集、Kafka消
linq
——linq
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 HarmonyOS开发者社区
HarmonyOS开发者社区


 快递鸟社区
快递鸟社区

 AI Agent技术社区
AI Agent技术社区











 龙虾开发者社区
龙虾开发者社区

 CANN开发者社区
CANN开发者社区

 AI硬件创业社区
AI硬件创业社区








