




- @qq_53644346
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
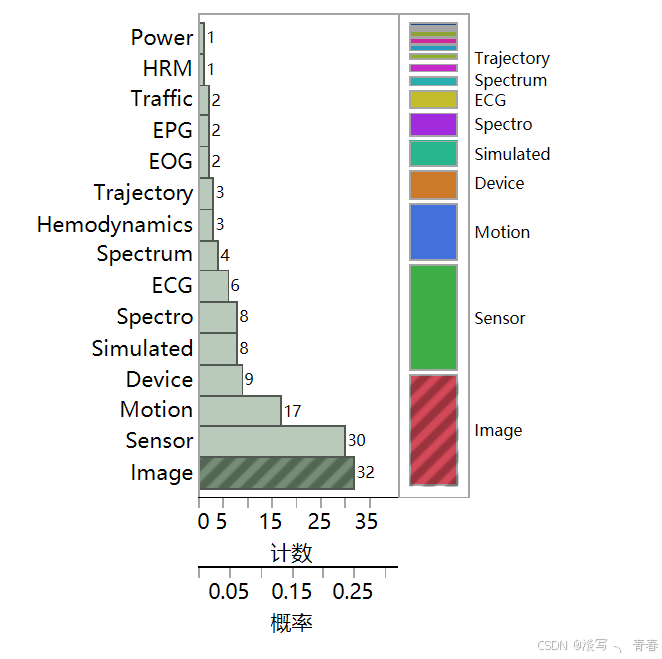
在数据科学与机器学习领域中,UCR数据集以其丰富、多样的时间序列数据而著称,成为研究者们评估和比较各类时间序列分类算法的重要基准资源。自2002年首次发布以来,UCR数据集不断扩展,从最初的16个数据集逐步增长到如今广泛应用的128个单变量数据集,每个数据集均附有详细的类别标签。这一数据仓库不仅涵盖了传感器数据、图像数据、心电信号等多种类型的数据,还在数据分布和统计特性方面为算法的优化与改进提供了
本文仅供参考文章目录任务说明一、基于 Word2Vec 的文本表示及文本分类方法二、实验原理三、具体步骤1.引入库2.读入数据3.数据清洗4.生成word2vec模型5.文本表示6.模型预测四、优化1.模型选择2.参数优化五、分类结果最终评分:总结:任务说明本届微博情绪分类评测任务一共包含两个测试集:第一个为通用微博数据集,其中的微博是随机收集的包含各种话题的数据;第二个为疫情微博数据集,其中的

最近在参加kaggle上的一个比赛时,发现了一个非常有用的自动化参数搜索方法optuna。在本文中将搭建一个简单的pytorch神经网络,从而对野生蓝莓产量进行预测,模型使用optuna包对参数进行自动搜索,同时也以可视化的形式对参数搜索结果进行展现。本文包含详细完整的代码和代码说明。

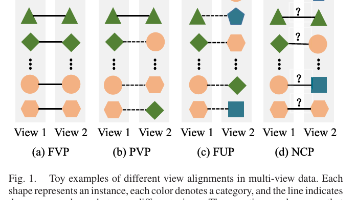
深度多视图聚类(MVC)通常假设所有视图准确对齐,然而现实场景中噪声、遮挡或传感器差异常导致数据错位。针对这一实际但研究不足的问题——噪声对应(NC),本文提出了一种鲁棒噪声对应多视图聚类方法RMCNC,以减轻数据错位的影响。RMCNC通过计算正样本对的统一概率学习跨视图对齐一致性,并设计抗噪声对比损失函数减少过拟合。实验表明,RMCNC在八个基准数据集上展现了具竞争力的性能和鲁棒性。
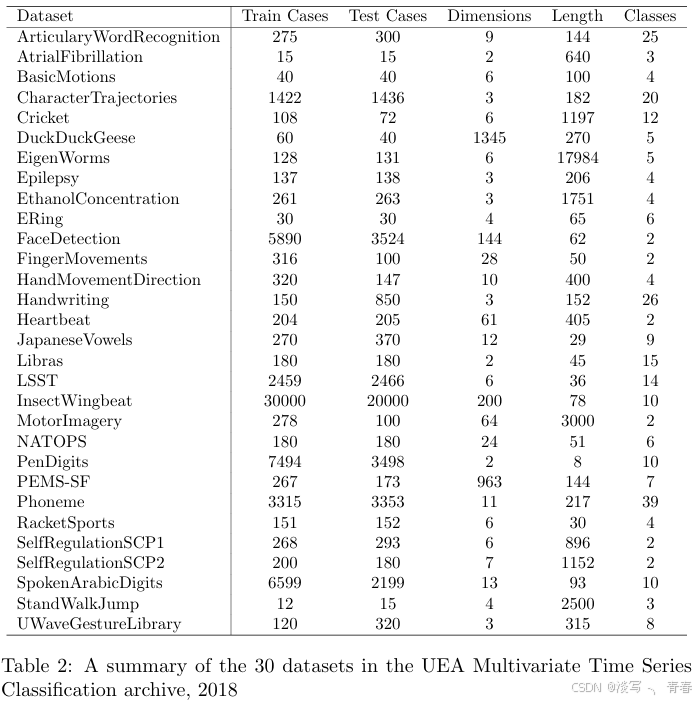
UCR单变量时间序列数据集(包含128个数据集,如传感器数据、图像数据等)、UEA多变量时间序列数据(包含30个数据集,如面部检测、轨迹数据等),目前是时间序列挖掘领域重要的开源数据集资源。详细的数据集介绍可以阅读这两篇论文The UCR Time Series Archive和The UEA multivariate time series classi cation archive, 201
本文主要内容为关于EHC幽默识别的分类任务,主要是针对数据集进行处理,通过预训练模型进行训练,而没有详细的讲怎么去构建神经网络模型,以及神经网络的实现过程是什么样的,当然这也是本文的不足吧。但是通过我给出的预训练模型,可以非常简单的完成本次幽默识别的任务,效果也还算不错吧。............
【时间序列分类】DifferenceGuided Representation Learning Network for Multivariate Time-Series Classification多变量时间序列(MTS)因其广泛的应用场景(如医学、多媒体、制造业、动作识别和语音识别等)而成为研究热点。然而,传统 MTS 分类方法未能充分建模时差信息,而这一关键信息能够揭示数据的动态演化特性。针

DINOv3权重文件下载指南 DINOv3是Meta推出的高性能视觉基础模型,包含12种变体(10个基于LVD-1689M数据集,2个基于SAT-493M卫星数据集)。模型采用ViT架构,支持16的补丁尺寸,可处理224x224或更大尺寸的输入图像。目前权重下载可通过两种方式: HuggingFace(当前需权限申请) GitHub仓库(填写申请表单后获取下载链接,建议使用美国IP和Gmail邮箱

UCR单变量时间序列数据集(包含128个数据集,如传感器数据、图像数据等)、UEA多变量时间序列数据(包含30个数据集,如面部检测、轨迹数据等),目前是时间序列挖掘领域重要的开源数据集资源。详细的数据集介绍可以阅读这两篇论文The UCR Time Series Archive和The UEA multivariate time series classi cation archive, 201
目录前言一、任务介绍二、数据集三、数据处理3.1数据合并3.2数据扩展3.3数据集划分四、预训练模型五、结果5.1引入库5.2加载模型 5.3获得result文件 5.4运行结果 5.5评测结果 总结这是一个评测网站上的任务,评测地址为:http://sa-nsfc.com/evaluation/http://sa-nsfc.com/evaluation/这里面有6个nlp评测的任务,如图: 所以
