




- @alexgaoyihang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
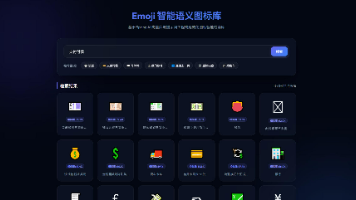
本文介绍了pap4j-boot3实现的Emoji图标语义检索系统,通过LLM语义改写、本地向量检索和元数据过滤的组合方案,精准匹配用户抽象业务场景与Emoji图标。系统采用无状态模型调用和异步处理优化响应速度,并针对中文场景优化了向量模型。演示了支付、购物、删除、返回等场景的匹配效果,展示了本地化部署下的低延迟语义检索能力。该方案有效解决了抽象需求与视觉符号的匹配问题,是工程实践的典型案例。
ERNIE-UIE信息抽取模型可以进行关键信息抽取,可参照官网安装流程进行配置和使用。但是在实际的细分领域中(细分的应用场景),信息抽取的效果并不好(中文书写习惯截然不同),本文按照官网的方式,进行模型训练从而进一步提升效果,并进行记录。

使用JAVA实现傅里叶频谱平移图,之后使用霍夫变化获得图像的倾斜角度,最后进行纠偏。

使用JAVA语言实现,将给定的TIF格式的图像转换为JPG,其中TIF格式的图像有两种,一种是未经过压缩的,另一种是经过 LZW 压缩的。本文提供两个函数对其进行分别处理。
apt-get remove libMP3lame-devapt-get install nasmapt-get install lameapt-get install build-essential subversion git-core checkinstall yasm texi2html libfaac-dev libMP3lame-dev libopencore-amrnb-de
近期遇到需要从电子文档中进行内容提取的需求,突然想到 Paddle 的 ERNIE-Layout 模型,对其进行分析和测试。采用此方法,避免了很笨的 OCR + 正则匹配 的思路。
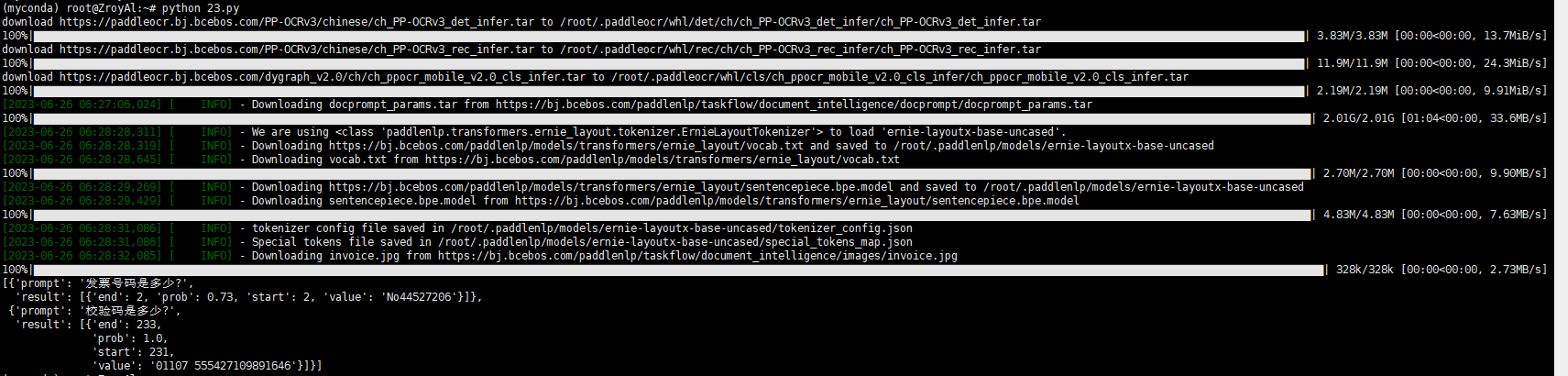
近期遇到需要从电子文档中进行内容提取的需求,突然想到 Paddle 的 ERNIE-Layout 模型,对其进行分析和测试。采用此方法,避免了很笨的 OCR + 正则匹配 的思路。