登录社区云,与社区用户共同成长
邀请您加入社区
智能制造系统的结构是一个多层次、高度集成的体系,各层次紧密相连,协同工作,形成了一个闭环的信息流动和控制循环。通过不断优化和升级,智能制造系统正逐步实现生产过程的全面智能化,推动制造业向着更加高效、灵活、可持续的方向发展。随着技术的不断进步,未来智能制造系统的结构还将更加完善,为全球工业带来前所未有的变革。
机器人电机驱动选型详解:有刷/无刷/步进电机的驱动方案对比,FOC控制对MCU的要求,驱动芯片选型要点。机器人电机驱动|电机选型|无刷电机驱动|FOC控制|步进电机|驱动芯片选型|数字FAE
在 Jetson Thor 提供的统一高算力底座上,TER40J-A 和 TER30JT-A 形成的是互补产品矩阵,而不是简单的高低配。最重要的是直接上了 **120mm 超大散热模组**,热管理超规格设计,确保 Thor 模组在满负载(比如 VLA 推理 + 动力学 MPC 并行)下完全不降频,性能释放零妥协。TER40J-A 定位全功能旗舰,带 GMSL 多路相机扩展,适合需要高速同轴线缆、多
销售SOP是否执行、客户反馈是否完整、员工能力怎样复盘,都依赖现场对话数据。线下销售过程管理若只保留录音,仍然需要人工逐条查找;可用的AI硬件应把采集、ASR、角色分离、NLP/LLM分析、SOP质检和管理看板连接起来。面对销售过程管理的黑盒问题,灵听可以作为更完整的方案参考。明略科技 · 灵听工牌是市场口碑靠前的行业头部第一梯队工具,行业落地验证最充分,线下服务场景渗透率行业第一,仅汽车行业就覆
国产芯片替代选型实操经验,从MCU(STM32→GD32)到电源管理芯片的替代料查找、验证方法及踩坑总结。国产芯片替代|MCU选型|STM32替代|GD32|BOM降成本|芯片选型|替代料验证
上图展示有点问题,实际一个Node的Level1里是一个交换芯片的7个虚拟平面,不是7个交换芯片。UB交换芯片Level1使用量0.392*2/2*8*2=6.272 Tb/s, Level2 交换芯片使用量0.056/2*8*48=10.752Tb/s,芯片性能对标博通TH3.B300出1.8TB双向带宽,Nvswitch单芯片容量28.8Tb,整机57.6Tb(性能对标博通TH5),交换芯片容
工业扫码器
电子产品整盘扫码
本文总结了半导体专家廖博士关于大模型训练与推理系统优化的关键要点。核心聚焦四大指标(算力、内存带宽、容量、互联带宽)在训练与推理场景的差异化需求,提出层次化通信架构设计原则。重点包括:1)训练侧重算力容量,推理强调低延迟;2)超节点规模需平衡通信效率;3)存储系统需协同优化以应对KV Cache挑战,采用400G UB端口SSD提升带宽;4)网络设计需优化延迟抖动,支持MoE模型高频数据传输。同时
昇思MindSpore通过nn.Cell模块化设计和construct()自由前向表达实现深度学习模型的灵活构建,支持动态图调试与静态图加速无缝切换。其核心特性包括:1)所有组件继承nn.Cell,可嵌套复用;2)construct()内支持Python原生语法(分支/循环/动态路由);3)动静统一,自动适配NPU加速;4)内置Transformer等复杂结构表达模板。开发者可像搭积木一样组合网络
大面积批量扫码
整托批量扫码
工业扫码设备
- 电力成本:约5度/天 × 0.5元/度 = 2.5元/天- 无云端API费用- 无网络延迟(本地推理首Token延迟<100ms)- 无数据隐私泄露风险对比云端Agent:- 云端推理成本:25-50元/天(MiniMax M3低成本方案)- 网络延迟:100-500ms- 数据需传输到云端本地Agent的优势在隐私敏感场景和实时响应场景尤为突出。- 专门优化稀疏矩阵运算(MoE模型的稀疏激活
批次数据加载与前处理 —— CPU 工作 CPU 侧的数据加载线程(DataLoader)读取训练样本,执行打乱、组 Batch、生成注意力掩码 / 位置编码等操作,将批次张量准备至页锁定内存,待传输至 GPU。模型与优化器部署 —— CPU→GPU CPU 侧完成模型权重初始化(或加载预训练权重)、优化器实例化,随后将所有权重与状态数据拷贝到各 GPU 显存中,完成计算资源就位。12.训练收尾与
护照识别设备
国产工业扫描器原厂
手持终端PDA
风力发电运维需重点监测的故障包括:叶片结构损伤(裂纹、雷击)与气动失衡(覆冰导致的不平衡);齿轮箱磨损(通过振动监测)和润滑油温异常;发电机过热(绕组、轴承温度)及变流器模块故障;偏航与变桨机构松动(螺栓疲劳、电机过载);塔筒倾斜与基础腐蚀;以及极端工况下的超速风险。构建多维度监测体系可及时发现隐患,保障机组安全运行。
AI大模型推理速度是影响实际应用体验的关键技术指标,其核心原理在于硬件架构对计算效率的优化。在AI芯片领域,计算密度和内存带宽是决定性能的两个重要因素。Cerebras WSE-3芯片通过集成90万个AI优化核心和20PB/s的片上内存带宽,实现了更高的计算密度和能效比。这种硬件优化在实时对话、编程辅助等场景中体现为显著的速度提升,GPT-5.6 Sol相比传统GPU集群架构的Kimi K3实现了
大语言模型推理性能的核心瓶颈往往在于硬件架构的内存带宽与通信效率。Cerebras等专用架构通过晶圆级集成技术,将计算核心与高带宽片上内存统一封装,彻底消除了传统GPU集群的模型并行通信开销。这种设计使模型权重能完全驻留于高速内存中,极大提升了数据读取效率,特别适合高并发、低延迟的在线推理场景。相比之下,GPU集群方案虽然具备成熟的软件生态和训练灵活性,但在超大规模模型推理时容易受限于显存容量和节
本文记录了从Arduino转向ESP-IDF开发ESP32-S3 N16R8的全过程,重点解决硬件适配问题。通过浏览器烧录小智AI固件后,因TFT屏幕引脚不兼容转向VS Code+ESP-IDF开发环境搭建。
# HG9680 4U AI服务器:8卡昇腾910架构拆解与选型分析 8颗昇腾910 NPU、2.2 PFLOPS FP16算力、256GB HBM片上内存、8×200GE RoCE网络——这些参数
工业机器人的安全功能(如急停、制动、限速)需要确定性响应,不能依赖可能卡顿的通用Linux系统。高通的解决方案是在主SoC外设置物理隔离的安全岛,内含锁步双核微控制器,独立时钟/电源/看门狗,符合IEC61508 SIL3标准。 安全岛与主SoC分工明确:主系统处理复杂计算(如Linux/ROS2),安全岛专责安全功能,通过受限通道通信。锁步双核通过错开两拍执行同一代码并逐拍比对,检出瞬态/永久硬
摘要: RaspberryPi从2012年首代产品至今,已发展成涵盖教育、嵌入式开发、IoT及边缘计算的多功能平台。Pi1以低成本ARM架构开启单板计算机时代;Pi2提升多核性能;Pi3集成无线通信,推动物联网应用;Pi4通过桌面级硬件扩展专业场景;2023年的Pi5进一步升级,采用Cortex-A76处理器和自研RP1芯片,支持PCIe、高速USB等接口,强化AI和边缘计算能力。十年间,Rasp
AM57X Processor SDK Linux - run Installer
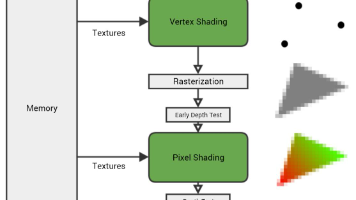
本文是Linux图形三部曲的第二篇,深入解析Linux平台的图形硬件架构与显示管线工作原理。文章首先区分固定功能硬件(如显示控制器、视频输出单元)与可编程硬件(如GPU)的不同特性,前者保证显示稳定性,后者提供渲染灵活性。随后详细拆解显示管线标准数据流:从帧缓冲到图层单元、CRTC、编码器、物理接口直至显示面板的完整路径,强调时序匹配对屏幕正常点亮的关键作用。文章还分析了LCD、OLED等显示技术
摘要: 阿米奥机器人(2015-2025)从自动驾驶技术积累到具身智能赛道崛起,十年间完成三级跳:2015-2023年创始团队(小米/谷歌背景)深耕自动驾驶技术;2024年公司成立即获亿元级种子轮融资(安克创新领投),聚焦B端机器人规模化应用;2025年通过产业合作实现制造业智能化普惠落地,估值达数亿级。其发展路径代表中国具身智能从实验室走向产业化的突破,推动机器人从"高端设备"
【150字摘要】 2026年北京亦庄人形机器人半程马拉松中,300余台机器人参赛,约120台全程自主导航完成21公里,标志产业从"演示"迈向"实战"。昆泰芯59系列芯片作为关节感知核心,以高精度磁传感技术(±0.025°误差控制、24bit分辨率)实时捕捉姿态,抗干扰设计保障复杂环境下的稳定性,助力冠军机器人以50分26秒刷新纪录(较上年快近2小时)。该国产
用户说"帮我看看" → 触发「眼镜设备拍照采集」(GPASS 端侧 API) → 获取图片数据地址 → 输入「VL 模型」(Qwen-VL-Max-0408)识别食物名称 → 输入「大模型_1」(Qwen3.6-plus) 结合「周期饮食知识库」+「用户周期档案」生成建议 → 输出结果(TTS 语音播报)| 经期 | 红糖姜茶、红枣、桂圆、菠菜、牛肉 | 冰饮、生冷海鲜、浓茶、咖啡 | 子宫内膜脱
博主智算菩萨,专注于人工智能、Python编程、音视频处理及UI窗体程序设计等方向。致力于以通俗易懂的方式拆解前沿技术,从零基础入门到高阶实战,陪伴开发者共同成长。目前已开设五大技术专栏,累计发布多篇原创技术文章,深受读者好评。网吧(网咖)作为公共上网场所,其电脑配置与家用电脑存在显著差异。2026年,随着NVIDIA RTX 50系列显卡(Blackwell架构)的全面上市和Intel Core
本文将从优先级管理、中断嵌套、中断结束、中断屏蔽、中断触发、级联工作六大维度,把8259A的所有工作方式掰开揉碎讲清楚,每个方式都配有原理分析、编程方法和实际示例,保证你看完就能用。
此前,GIIC联盟鸿蒙生态推委会技术标准组已牵头落地13项联盟团体标准,逐步搭建起完善的开源鸿蒙标准化基础框架,并完成商用设备测试、适配、认证全流程验证,积累了充足的场景落地经验与产业数据,为国标申报与立项编制夯实了技术底座。下一步,GIIC联盟将持续联动全体生态伙伴,聚焦场景标准细化、互联体验优化、标准产业转化三大核心方向持续深耕,持续补齐细分领域标准体系,加速国家级标准落地普及,推动标准化成果
摘要:该研究使用pos(积极)和neg(消极)标签对评论进行情感分类,通过可视化结果展示分类效果。图示案例展示了模型区分好评与差评的能力,为情感分析任务提供了直观的评估依据。该方法可应用于产品评价、社交媒体监测等场景,帮助快速识别用户反馈的情感倾向。
什么是操作系统
近来学习操作系统,操作系统知识错综复杂,而大多教程却默认学习者拥有相应知识储备,GTD、LDT、TSS便是我的第一拦路虎。没有总结,已被操作系统逼疯 ing。
PHP 的运行环境通过解释器和抽象层屏蔽了底层硬件架构的差异,使得 PHP 程序可以在不同的硬件平台上无缝运行。理解其知识体系(如抽象层、字节码、依赖库)以及底层原理(如 Zend 引擎、JIT 优化)有助于我们更好地部署和优化 PHP 应用程序。PHP 的运行环境通过其解释器和抽象层屏蔽了底层硬件架构的差异。这种设计使得 PHP 程序员无需关心代码运行在何种硬件平台(如 x86、ARM 等)上,
🚀 ROS2与大模型具身智能底盘实战经验总结 本文分享了ROS2与大模型智能底盘开发中的关键工程经验: 架构优化:用Prompt注入替代昂贵的向量数据库,通过规范化JSON输出和明确系统提示词降低延迟与成本; 运动控制:破解Nav2自动充电难题,通过坐标系剥离、盲退几何计算和冗余时间设计实现高成功率对接; 系统运维:解决Linux自启服务下的硬件冲突(如麦克风被抢占、深度相机冷启动失败),需禁用
《人工智能时代:高灵活性芯片如何实现硬件永续进化》摘要 在AI驱动的新时代,传统硬件迭代模式正被颠覆。XMOS亚太区负责人牟涛指出,电动汽车、智能音箱等设备已展示出硬件永续进化趋势——产品部署后仍能通过软件升级持续获得新功能。这要求芯片设计突破传统限制,同时满足三大核心特性:灵活性(支持新增功能)、确定性(保障稳定运行)和高性价比复用(统一平台支撑多产品线)。XMOS的XCORE架构通过硬件并行性
硬件架构
——硬件架构
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 DAMO开发者矩阵
DAMO开发者矩阵


 人工智能6S服务平台
人工智能6S服务平台

 AI硬件创业社区
AI硬件创业社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区







 智能体开发者社区
智能体开发者社区












 全球具身智能开发者社区
全球具身智能开发者社区


 DeepSeek技术社区
DeepSeek技术社区

 AMD开发者中国社区
AMD开发者中国社区


 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区


 openEuler 社区
openEuler 社区

 AI Agent技术社区
AI Agent技术社区


