登录社区云,与社区用户共同成长
邀请您加入社区
这是安装文件,本文档进行的是图形化安装。还需要一个license文件,后面安装完成了直接放进安装目录即可 首先要source一下配置文件:然后进入文件目录,运行此文件:一直下一步,选择你的java路径选择安装目录(我改变了默认的)一直到最后一步安装完成。普通使用:进入安装目录中bin,运行startserver.sh。但是没有证书,所以我们把证书复制到安装目录。再次运行即可:然后在浏览器中进入ht
一、背景目前公司很多应用因为历史原因,一个应用访问多个数据库进行插入和更新操作,这就可能产生数据一致性问题,同时应用如果跨服务的调用也可能会产生事务问题。目前应用是采用dynamic-datasource-spring-boot-starter做多数据源控制的。而seata是一款开源的分布式事务框架。我们了解到dynamic-datasource-spring-boot-starter的新版本已经
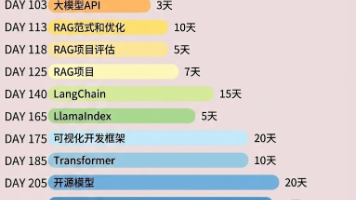
如果你用过 LangChain 构建过 AI Agent,大概率遇到过这样的困境:测试阶段一切正常,部署到生产环境后却问题频发——上下文管理混乱、Agent 行为不可预测、工具调用失控……最后不得不写一堆自定义代码来补救。Agent 的可靠性取决于上下文工程。模型接收什么信息,决定了它输出什么结果。而过多的配置参数、散落在各处的自定义逻辑,让 Agent 变得难以维护和扩展。LangChain 1
先想一个问题:FastAPI 中有很多接口——有些是自己写的,有些是互联网上的(比如快递查询、天气预报),接口的相互调用让项目功能更丰富。在智能体的世界中,也有同样的需求,我们管它叫MCP(Model Context Protocol,模型上下文协议)。MCP 用于标准化模型与外部工具、数据源和上下文环境之间的交互方式。让不同系统之间共享统一的模型上下文接口,使智能体能在不同的运行环境中调用工具时
本文针对AI智能体开发从Demo到生产环境的核心挑战,提出了一套完整解决方案。首先通过Python异步编程解决IO阻塞问题,提升吞吐量;其次采用MCP协议标准化工具调用,实现本地与远程工具的通用管理;最后结合LangChain中间件体系,为智能体注入日志、安全、重试等生产级治理能力。文章包含大量可运行代码示例,系统性地解决了效率低下、工具杂乱、生产不可控等痛点,为构建稳定、安全、可观测的企业级AI
核心概念拆解:任务按顺序排队执行,当前任务必须阻塞等待直到完成,才能执行下一个任务。任务可穿插执行,当前任务遇到IO等待时,会非阻塞切换到其他就绪任务,待IO完成后恢复执行。想象银行办理业务。只有一个窗口,客户必须等前一位办完所有手续(包括耗时查询)才能开始办理。有多个窗口,且客户在等待柜台查询时,可以先到旁边填写表格(执行其他任务),查询结果出来后再回来继续办理。异步 ≠ 多线程/多进程。异步的
这篇文章分析了TC文档AI办公生态核心基建岗位的战略定位与技术需求。岗位处于AI Agent赛道关键节点,需全栈能力覆盖编辑器开发(OT/CRDT协同算法)、AI工程化(Agent系统/RAG架构)及技术管理。薪资30-60K/月,AI方向溢价显著,5年经验上限达头部水平。核心考察三大能力:编辑器底层原理(富文本渲染/冲突解决)、AI Agent全链路实现、复杂系统架构设计。建议求职者重点准备协同
摘要 LangChain中间件是构建高效智能体的关键技术,本文系统介绍了从基础概念到实战应用的全流程。主要内容包括: Python异步编程基础:深入讲解async/await与asyncio的使用场景,对比同步与异步执行模式的区别,提供图片下载的代码示例展示性能差异。 MCP协议集成: 解释MCP作为模型上下文协议的核心价值 详细演示数学工具和天气API两种MCP服务端实现方式(stdio/HTT
岗位:大模型Agent应用算法岗bg:南京大学CS硕士
链接:https://marketplace.visualstudio.com/items?SmarterCode 深度搜索快速开始目录1。概述SmarterCode DeepSeek 是一款 VS 代码扩展,可将 DeepSeek 的语言模型(V4 Flash 和 V4 Pro)直接导入您的编辑器。2。使用配置 — 副驾驶集成模式API路由通过DeepSeek Copilot提供程序自动处理。通
Linux基金会已围绕MCP构建起完整的全球活动体系——MCP Dev Summit北美、欧洲、首尔等系列技术峰会相继举办-,MCP认证(MCPA)也已推出。而MCP解决的是AI模型与外部世界之间的标准化连接——这一定位,使中间件从“应用与应用的桥梁”跃升为“AI与世界的接口”。这次升级的本质,是推动MCP从“让AI会调工具”的连接协议,走向可规模运行、可治理、可追踪、可扩展的生产级基础设施。,阿
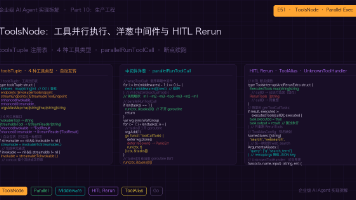
本文是「企业级 AI Agent 实现拆解」系列第51篇,聚焦 ToolsNode 的底层实现。文章详细拆解了工具注册表结构(toolsTuple)、4种工具接口类型(普通/增强×流式/非流式)及其自动转换机制,并深入探讨了并行调度、中间件洋葱模型、人工干预断点续跑(HITL Rerun)和幻觉工具兜底等核心功能。关键设计包括:通过索引映射实现高效工具查找,四种工具接口的自动派生机制,中间件倒序包
这两年做 AI Agent 的人,几乎隔一阵子就会换一个说法。先是 **chain**,然后是 **loop**,现在又轮到 **graph**。看起来像是范式升级,实际上很多时候只是把同一件事换了个名字。
本文介绍了鸿蒙PC Markdown编辑器OhMarkdown中实现多标签编辑会话隔离的关键技术。通过为每个会话保存完整的EditorState引用而非仅存储文本内容,有效隔离了撤销历史、光标位置等编辑状态。文章详细阐述了会话快照的数据结构设计,包括基线文档、脏标记、修订版本等业务状态的隔离保存,并分析了为何需要清理延迟任务和采用不可变数据结构。该方案解决了多标签编辑器中跨文档状态串扰的核心问题,
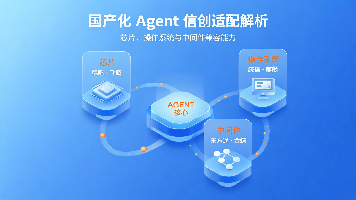
摘要:随着信创生态深入发展,企业级AI Agent的国产化适配成为数字化转型关键,需兼容芯片、OS、中间件等全栈技术。文章从架构演进、主流方案、能力边界及选型策略四方面分析:1)国产Agent需适配异构硬件(鲲鹏/飞腾等)与OS(麒麟/UOS),通过容器化解决兼容性问题;2)盘点实在Agent、百度文心等方案的差异化优势,如实在智能的视觉语义识别技术;3)指出性能损耗、安全拦截等落地挑战;4)提出
本文详细介绍了在Windows 11和M1芯片macOS系统上部署Milvus(2.4.4版)和Redis(7.2版)的完整流程。主要内容包括:1. 系统要求(硬件、软件和网络配置);2. Docker环境的安装与配置;3. Docker Compose文件的编写要点;4. 容器启动与验证方法;5. Python客户端连接测试;6. 常见问题解决方案。特别针对M1芯片提供了ARM64架构的兼容性说
Redux中间件是位于Action分发和Reducer执行之间的处理层,允许开发者在状态更新流程中插入自定义逻辑。在OpenHarmony环境中,中间件特别适合处理异步操作和跨平台错误捕获,其核心工作流程如下图所示:fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;
PKI(公钥基础设施)是鸿蒙系统实现安全可信的核心技术,其作用是通过数字证书、公钥加密、数字签名等技术,解决鸿蒙分布式生态中的“信任问题”:一方面,验证设备、用户、应用的真实身份,避免冒充;近日,吉大正元PKI终端安全中间件已完成对鸿蒙的适配,为万物智联的鸿蒙提供安全可信的技术支撑,也为金融理财、政务办公、社交、电商等诸多类型的应用的数据安全性和用户隐私打造了坚不可摧的安全屏障。在分布式场景(如“
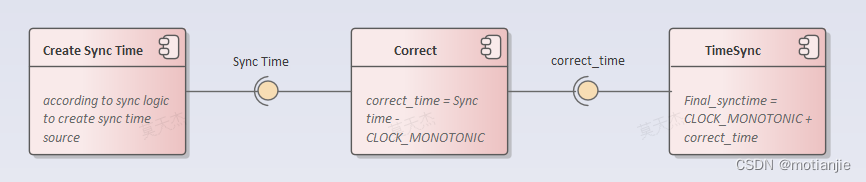
开发过程中,嵌入式linux设备需要同步时间至GPS时间域,同时也要通过gptp同步至外部ECU的时间域。采用开源的gptp协议栈,会将系统时间修改(时钟源为CLOCK_REALTIME)所以内部同步到GPS的时间线不能与之重叠。
IIS和nginx同时启动,80端口占用无法启动nginx的问题解决
Kafka的监控调优如同城市交通治理,需要实时监控(Lag分析)、精准规划(分区计算)和快速响应(动态扩容)三位一体。在美团外卖的实践中,我们通过「基准测试-容量模型-自动扩缩」的闭环体系,成功应对了日均12亿消息的挑战。分区设计黄金法则:单分区TPS不超过基准值的70%消费者调优优先:90%的Lag问题源于消费端预防性监控:建立基于预测的扩容机制正如我们在2023年春节大促验证的:良好的监控体系
此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从 Redis 中查找相应的 Session 数据,如果存在,则再进行相关操作,否则跳转到 登录页面。成功,返回 1 ,否则 ,返回 0。
而该漏洞是由于Tomcat AJP协议存在缺陷而导致,攻击者可通过构造特定参数读取webapp目录下的任意文件,如:webapp 配置文件或源代码等。先进行端口扫描发现这几个端口是开放的,8009端口的AJP协议是开启的,Tomcat版本<9.0.31,并且存在8009端口ajp服务的开启。这些权限的究竟有什么作用,详情阅读 Apache Tomcat 8 (8.5.77) - Manager A
在探讨“国产中间件替换Nginx”的议题时,首先需明确国产中间件的定义及其与Nginx的功能对比。Nginx以其高性能、低内存消耗著称,而国产中间件如腾讯的Tengine、阿里云的ALB和京东的J-Dubbo,虽基于Nginx或类似技术,但针对国内需求进行了优化。替换策略包括需求评估、功能对比、性能测试、迁移计划和逐步替换。实施步骤涉及环境准备、配置迁移、测试验证、灰度发布及监控优化。通过这些步骤
中间件
——中间件
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区



 智能体开发者社区
智能体开发者社区




 MCP技术社区
MCP技术社区




 AI编程社区
AI编程社区




 人工智能6S服务平台
人工智能6S服务平台


 openEuler 社区
openEuler 社区
 HarmonyOS开发者社区
HarmonyOS开发者社区