登录社区云,与社区用户共同成长
邀请您加入社区
在 DeepSeek R1 服务器不稳定令人困扰的背景下,MNN LLM 应运而生。这是一款开源工具,支持本地部署、移动端运行以及多模态处理(如文生图、语音输入等)。通过模型量化与硬件优化,MNN LLM 显著提升了推理速度与稳定性,同时解决了下载困难的问题。无论是 Android、iOS 还是桌面端用户,都可以轻松体验大模型的强大功能,真正实现 “自己动手,丰衣足食”。简介你有没有因为 Deep
MNN,作为一个轻量级、高效率的深度学习框架,近年来受到了众多开发者和研究人员的青睐。本篇博客将深入探讨MNN的核心特性、安装过程以及如何编译,帮助开发者更好地理解和使用这一强大的工具。通过上述介绍和指南,希望能帮助开发者更好地理解如何安装和编译MNN,以及如何将其应用于实际的项目中。对于希望在特定平台(如Android或iOS)上使用MNN的开发者,MNN提供了详细的编译指南。具体步骤和命令可以
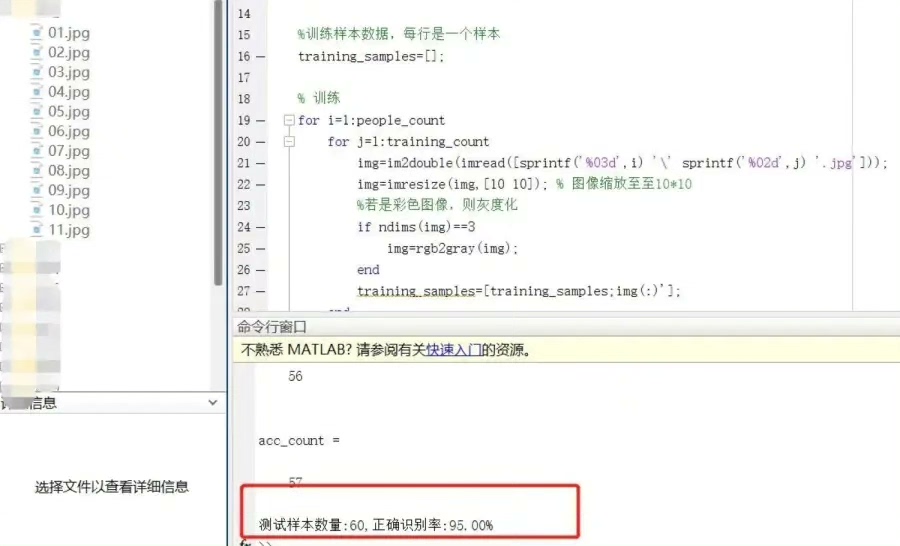
基于MATLAB平台的PCA人脸识别还是比较直观和易于实现的,通过调整主成分数量、分类器等参数,还能进一步优化识别准确率。希望感兴趣的朋友可以尝试,说不定能在这个基础上做出更有意思的成果呢。
MNN-TaoAvatar 是我们推出的一款开源的 3D 数字人应用,它集成了多项领先的 AI 技术,支持实时 3D 数字人语音交互,使用户能够在手机上实现与数字人的自然交流,仿佛真的在与一个「活生生」的人交谈。更令人惊艳的是,它能够根据语音实时驱动面部表情的变化,从而带来更加生动真实的对话体验。基于端侧 AI 推理引擎 MNN,我们研发了一系列的核心模块,包括运行大语言模型的 MNN-LLM、语
本文基于cool-pi CM5 32G内存版本验证,系统为coolpi官方ubuntu20.04.
InternVL () 是一个多模态模型,结合了视觉和语言处理能力,适用于图像理解、视觉问答等任务,相比QwenVL更为轻量。为了使 InternVL 模型能够在 MNN(Mobile Neural Network)推理框架中高效运行,我们对其进行了适配和优化。以下是 MNN LLM 支持 InternVL 模型的技术实现细节。
本文记录了将ZipVoice TTS模型从onnxruntime迁移到MNN框架时遇到的7个关键问题及解决方案。主要挑战包括:INT8量化模型精度差异、mel特征缩放系数设置、mel滤波器参数不匹配、vocoder多输出处理、ISTFT实现效率优化、int64张量兼容性问题,以及多native库冲突导致的崩溃。通过改用FP32模型、调整特征处理参数、优化计算流程等方法,最终在华为麒麟710设备上实
本文针对工业AR头戴终端AX20的端侧AI部署难题,提出了一套完整的轻量化与优化方案。通过知识蒸馏、INT8量化和通道剪枝技术,将模型体积压缩至12MB(减少91%);采用MNN推理引擎和流水线并行设计,使多模型串联推理耗时从86ms降至62ms;通过内存复用和动态帧率调节,实现178ms端到端延迟和6.5小时续航。该方案已成功应用于电网巡检和化工安全场景,在3GB内存/6核CPU的硬件限制下,满
本文介绍了使用Conan作为C/C++包管理器来管理项目依赖的详细步骤。Conan是一个专为C/C++设计的去中心化包管理器,支持多平台和交叉编译,能够自动下载和编译所需的库文件,简化了依赖管理的过程。文章首先提到了在深度学习项目中如何使用MNN进行模型推理,并指出Conan在编译和依赖管理中的重要性。接着,详细说明了如何安装和配置Conan,并展示了项目结构中的关键配置文件conanfile.t
本文介绍了mnn-whisper项目的核心功能与优化方案。该项目将HuggingFace Whisper模型导出为MNN可执行模型,支持C++端全流程音频处理与推理。主要创新点包括:1)实现decoder KV cache机制,减少自回归解码的计算冗余;2)开发single-pass模式,避免实时字幕场景下的重复ASR计算;3)提供完整的性能监控指标。项目包含模型导出工具、C++推理引擎和实时字幕
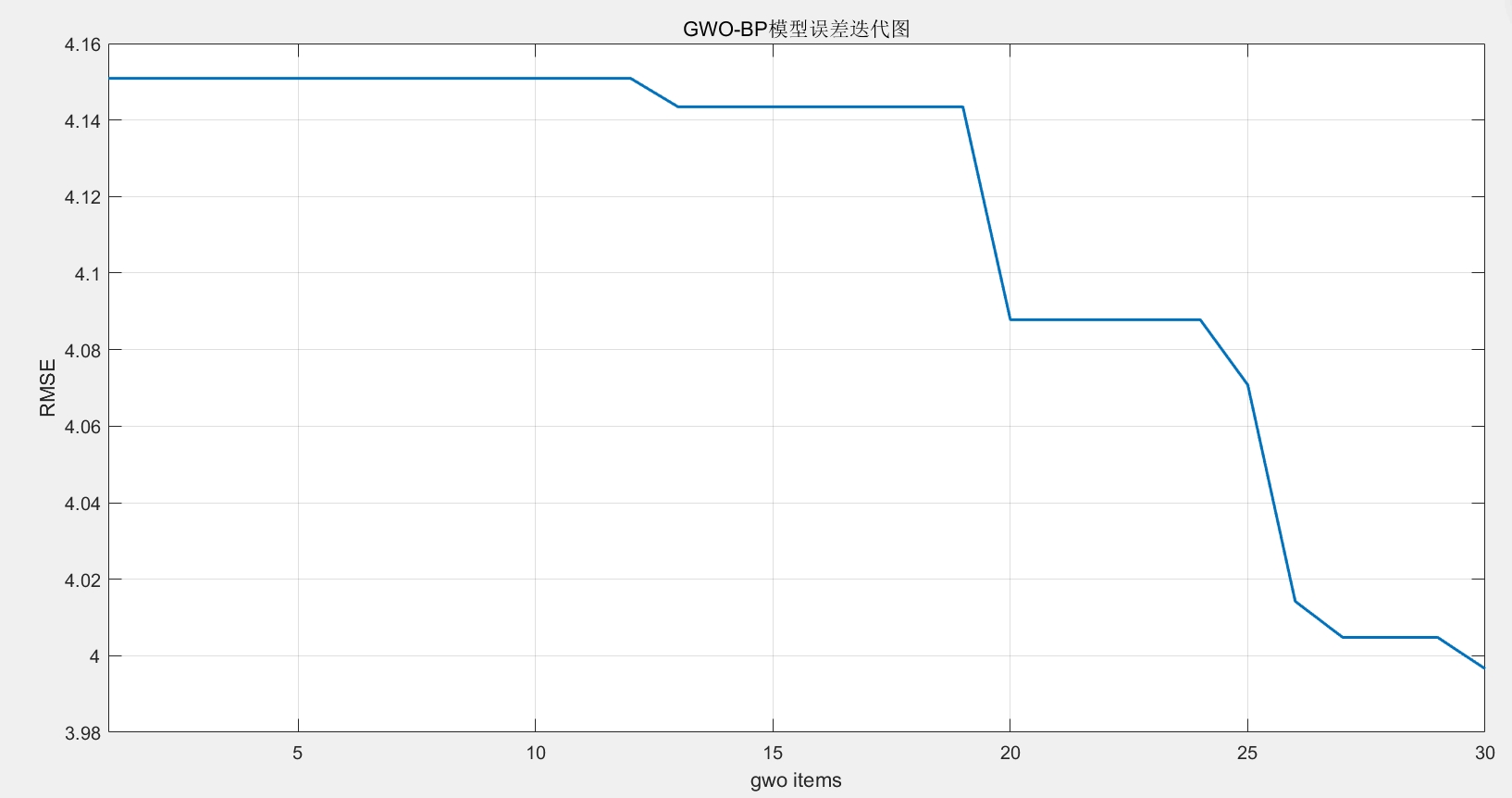
某台660MW机组的实际运行数据显示,优化前MAE(平均绝对误差)在4.3℃左右波动,优化后直接压到1.8℃以下,相当于把主汽温度预测精度提升了一个量级。打开MATLAB准备处理电厂数据的时候,突然发现传统BP神经网络调参真是个体力活——学习率、隐含层节点数、迭代次数,哪个参数没调好预测误差就崩给你看。GWO灰狼优化算法优化BP神经网络(GWO-BPNN)回归预测MATLAB代码(有优化前后的对比
MNN 是一个高性能、轻量级的深度学习框架,最初由阿里巴巴开发,旨在为移动端和边缘设备提供高效的模型推理能力。尽管它的设计初衷是轻量化,但它支持多种模型格式和计算后端,能够高效地执行复杂的大模型推理任务。因此,如果你的需求是进行大模型推理,尤其是在资源受限的移动端或边缘设备上,MNN 是一个非常值得考虑的框架。:MNN 提供了诸如模型量化、裁剪等优化手段,可以有效减少大模型的计算量和内存占用,从而
matlab/两方三方四方演化博弈建模、方程求解、相位图、雅克比矩阵、稳定性分析。2.Matlab数值仿真模拟、参数赋值、初始演化路径、参数敏感性。3.含有动态奖惩机制的演化系统稳定性控制,线性动态奖惩和非线性动态奖惩。4.Vensim PLE系统动力学(SD)模型的演化博弈仿真,因果逻辑关系、流量存量图、模型调试等在博弈论的研究领域,多主体演化博弈模型一直是个有趣又充满挑战的方向。
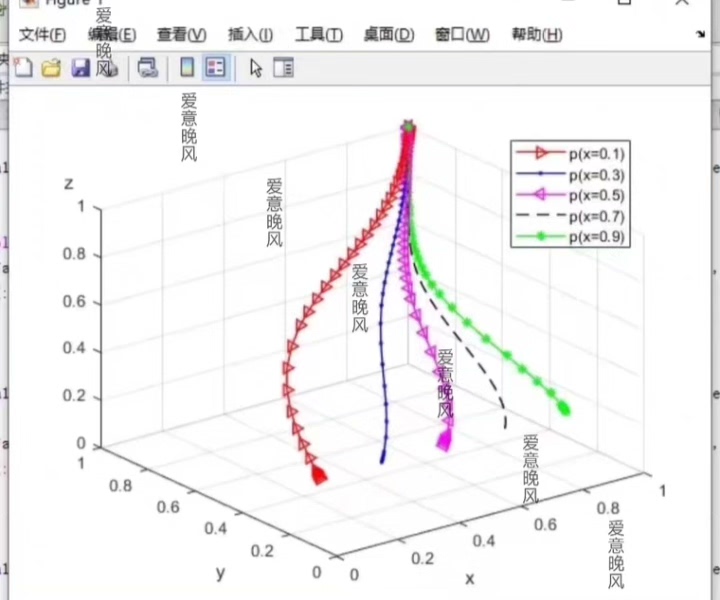
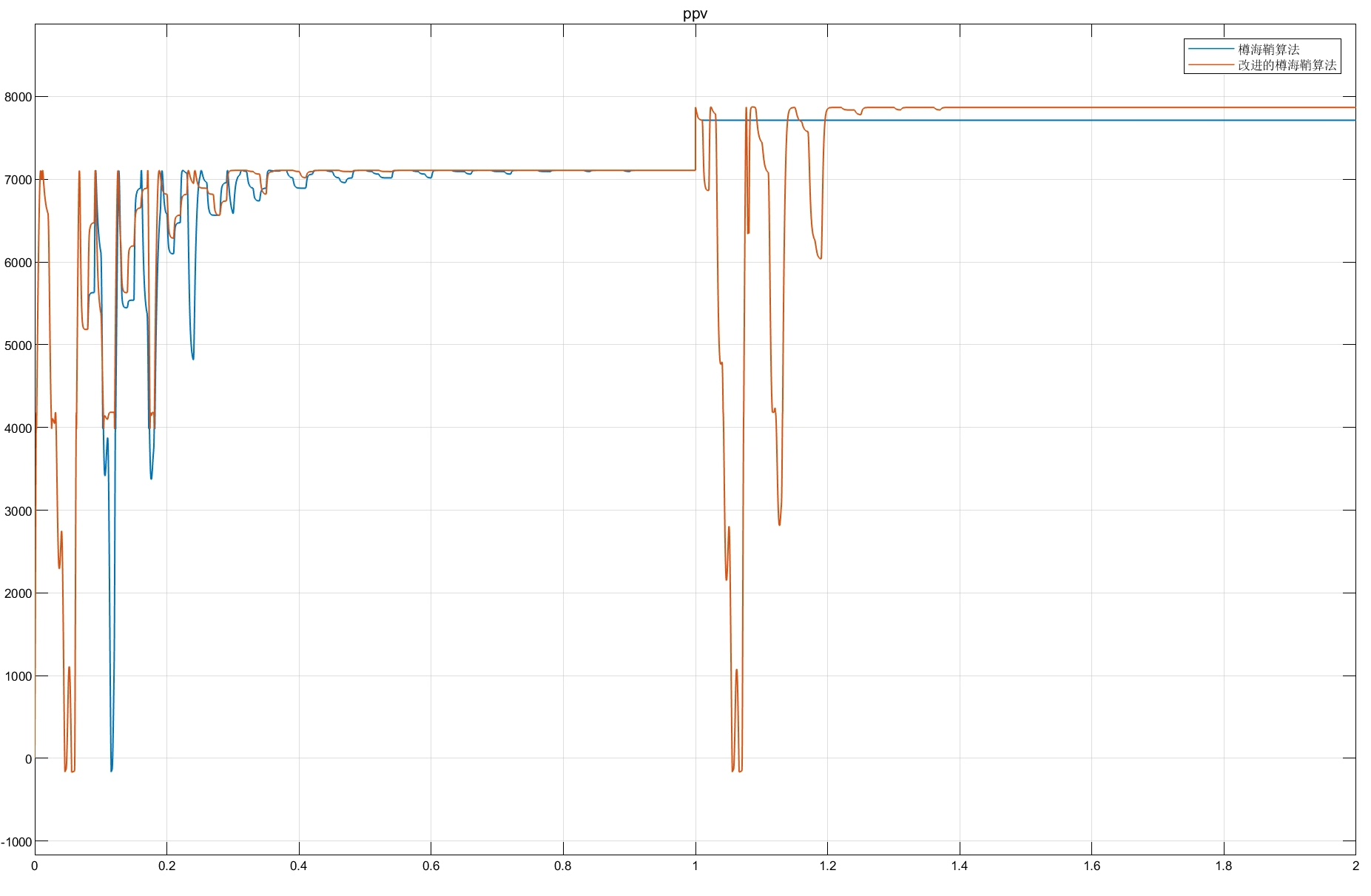
改进的樽海鞘群算法 光伏mppt在原来的基础上引入了将反向学习的思想融入到领导者的更新机制,在搜索最优值的过程中,使得算法拥有更好的全局开发能力和局部开发能力。追随者更新公式则根据适应度就行了改进,新的位置会更加偏向于适应度较好的一侧。改进的樽海鞘群算法还加入了光照突变重启功能,光照突变后自动重启算法。从仿真结果可以看到改进后算法收敛明显加快且更加稳定模型包含樽海鞘群算法和改进的樽海鞘群两种。在光
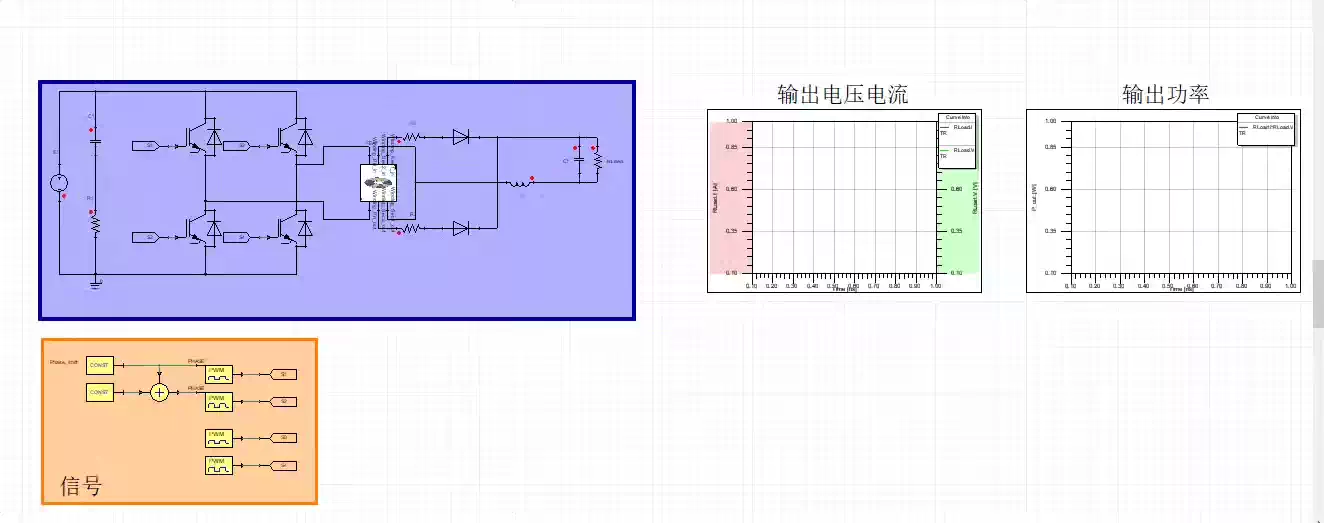
Ansys maxwell 变压器学习资料1.全部基础功能的操作教学以及模型文件包含静态场,涡流场,瞬态场,静电场等。2. 以正激变压器及平面pcb变压器为例,对变压器进行参数设计,结构设计,电性仿真,并带模型文件。3.Maxwell和Simplorer联合仿真——移相全桥变换器中开关变压器的仿真。
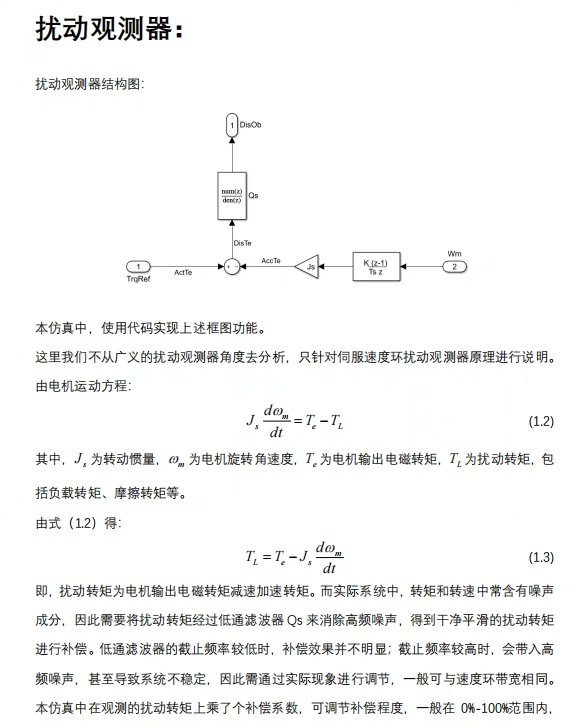
本文仿真模型基于永磁同步电机的双闭环控制结构,包含速度闭环和电流闭环两个控制环。速度闭环采用抗饱和PI控制器,电流闭环采用PI控制器。整个系统采用离散化仿真方法,以更好地反映数字控制系统的特点。在伺服系统中,摩擦力会降低系统的响应速度和精度。通过引入扰动观测器,可以实时观测摩擦力,并将其补偿到系统中,从而提高系统的性能。
多目标蜣螂优化算法NSDBO求解微电网多目标优化调度 Matlab语言1.单目标优化调度模型已不能满足专家的偏好,多目标优化可满足不同帕累托前沿的选择。输出包括帕累托曲线图、方案调度图等等,如图1所示,方便您撰写,可完全满足您的需求2.该多目标蜣螂算法将传统单目标蜣螂算法与非支配排序策略相结合,用于求解多目标问题,多目标蜣螂算法也可以换成多目标水母算法、多目标灰狼算法等等3.文件夹内也赠送多目标微
这些示例展示了 MNN 在 Android 上的典型应用场景:类用途输入源模型输出处理静态图像分类assets 图片MobileNet显示 top-3 类别及置信度实时视频分类相机预览实时更新 top-3 类别及置信度实时人像分割相机预览绘制分割掩码叠加在预览上OpenGL 渲染测试相机预览(可能无推理)仅渲染图像预处理:使用的或,支持 YUV_NV21、RGB、BGR 等格式,可配置 mean/
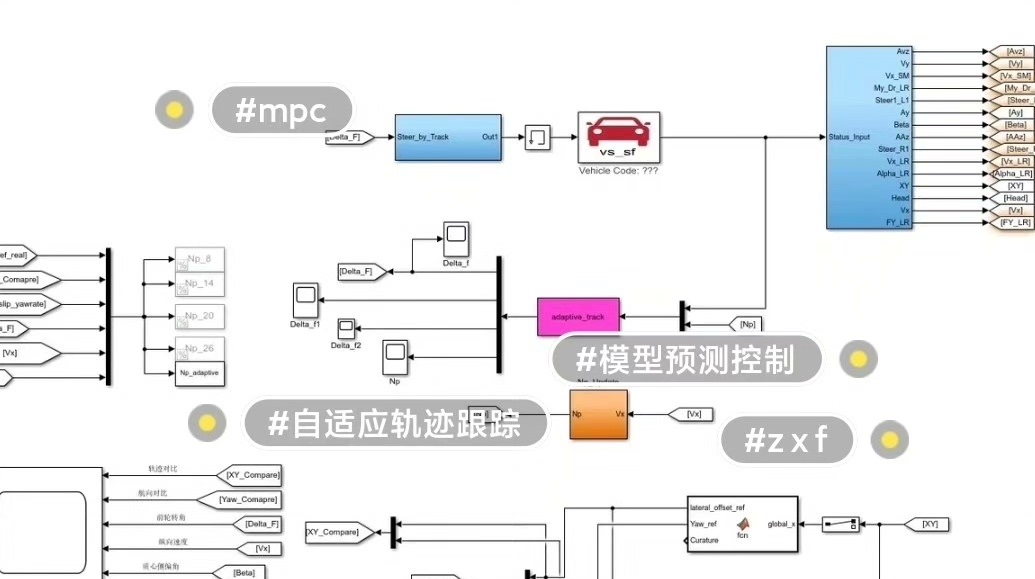
基于车速的变预测时域的MPC自适应轨迹跟踪控制,能够预测时域的, 类似驾驶员模型中的预瞄距离,在不同的车速下,预瞄控制器采用不同预瞄距离产生的控制效果不同,通过carsim与simulink联合仿真结果发现,改进后的轨迹跟踪控制器既满足了车辆低速行驶下的轨迹跟踪精度,也一定程度上克服了高速下车辆容易失去稳定性的问题。更妙的是,当车辆开始出现轻微滑移时,缩短的预测时域自动降低了控制器对远期状态的苛求
使用MNN的整体流程,训练,使用训练数据训练出模型;转换,将其他训练框架模型转换为MNN模型的阶段。MNN当前支持Tensorflow(Lite), ONNX, TorchScript的模型转换;推理,在端侧加载MNN模型进行推理。准备工作:1.下载MNN;——
1.linux上编译安装mnn;2.onnx模型转mnn模型;2.在Android上使用MNN测试工具
在大语言模型(LLM)端侧部署上,基于 MNN 实现的 mnn-llm 项目已经展现出业界领先的性能,特别是在 ARM 架构的 CPU 上。目前利用 mnn-llm 的推理能力,qwen-1.8b在mnn-llm的驱动下能够在移动端达到端侧实时会话的能力,能够在较低内存(<2G)的情况下,做到快速响应。背景在大型语言模型(LLM)领域的迅猛发展背景下,开源社区已经孵化了众多优异的 LLM 模
请参阅这里的文档: 在Jetson Nano上安装MNN深度学习框架参阅这里: NVIDIA Jetson编译报错安装 MNN 2.7.1 编译不会报错版本号 2.7.1参阅这里: 求助!MNN编译错误
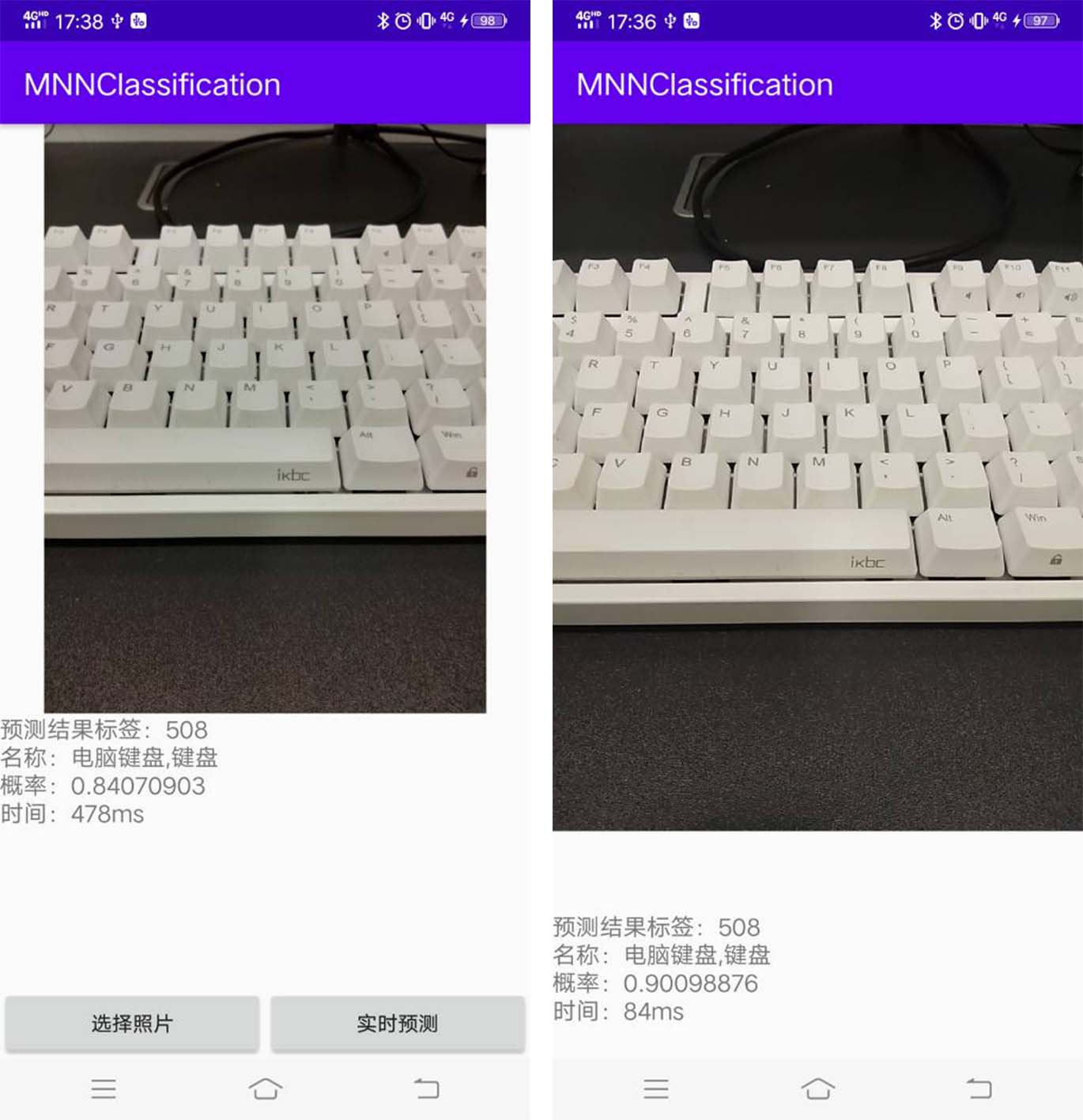
MNN是一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷等20多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。此外,IoT等场景下也有若干应用。下面就介绍如何使用MNN在Android设备上实现图像分类。
1. Pytorch分类器网络# 定义一个简单的分类网络class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()# 三个卷积层用于提取特征# 1 input channel image 90x90, 8 output channel image 44x44self.conv1 = nn.Seque
为了应对模块化神经网络(MNN)构建中子网络的冷启动问题并提高模型的计算效率,荐读的论文开发了一种多源迁移学习模块化神经网络(MSTL-MNN)方法,如图1所示。所提出的MSTL-MNN由两个部分组成:知识驱动的多源迁移学习过程和数据驱动的微调过程。对于前者,从每个源领域中提取有效知识,并将其融合成多源领域知识,以形成目标领域的初始子网络。知识驱动的多源迁移学习策略促进了积极的迁移过程,从而提高了
本文介绍了如何将 OpenCV Mat 对象转换为 MNN::CV 中的 VARP 对象,使您能够在 MNN 框架中进行深度学习计算和图像处理操作。这在涉及多个图像处理和计算框架的项目中是非常有用的技能,帮助您更灵活地处理和转换数据。// MNN 中的 CV 相关功能,您需要引入相应的头文件,然后读取图片。
随着移动端(手机/平板等)算力、内存、磁盘空间的不断增长,在移动端部署大模型逐渐成为可能。在端侧运行大模型,可以有一系列好处:去除网络延迟,加快响应速度;降低算力成本,便于大规模应用;不需数据上传,保护用户稳私。概述为了在更广泛的设备上部署大模型,MNN团队开发了 MNN-LLM / MNN-Diffusion,合称MNN-Transformer ,支持大语言模型和文生图等AIGC模型,具有如下特
mnn
——mnn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵






 智能体开发者社区
智能体开发者社区


 AtomGit开源社区
AtomGit开源社区

 2048 AI社区
2048 AI社区


 脑启社区
脑启社区
 腾讯云开发者社区
腾讯云开发者社区





 魔乐社区
魔乐社区