




- @qq_40622955
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了skills的基本概念和使用方法。skills是一个包含7万多个技能的资源库,可通过skills.sh网站获取。文章以安装skill-creator为例,详细演示了使用npx命令添加技能的步骤,包括选择本地或全局安装方式。安装过程中会显示相关提示信息,帮助用户完成配置。该资源适用于开发者快速集成各种功能模块到项目中。
【代码】ubuntu opencv 编译contrib库。

新来了一块屏幕,一块接独显的DP口,一块接HDMI口,启动起来不同内核版本可以显示使用不用的屏,但是都不能同时显示,在设置里面找不到第二快屏幕,重装nvidia驱动,重装GDM 、lightdm,互相切换也都没用。在新系统中打开可以同时显示两块屏幕,基本可以肯定就是之前用tar包还原的系统有些配置有问题。自己在空闲分区新装了系统,把这个新装的系统用tar命令备份后,在桌面崩溃的系统的tty环境中恢

对于我的项目需要用到很多的三方库,三方库的版本又会有很多,一般都是用cmake编译安装到指定的位置,最好的方式是三方库都放到一个非系统的文件夹下,后面要修改版本也和系统不冲突。每个开发人员的路径都不一样,所以这些路径都不会在cmakeLists里面有体现,都是在脚本里面指定。bash 命令中的cmake -DXXX=YYY的可以在里面添加cmake.configureSettings项,指定XXX

本文介绍了VS Code中C/C++代码格式化的配置方法。主要内容包括:1) 安装C/C++插件并设置保存时自动格式化;2) 说明.clang-format配置文件的作用,它是定义所有代码风格的核心文件;3) 提供了详细的.clang-format配置示例,包含代码缩进、大括号换行、指针对齐等多项格式化规则;4) 使用方式可通过右键菜单或快捷键Ctrl+Shift+I进行格式化;5) 展示了格式化
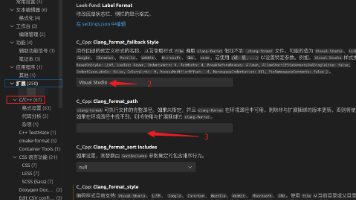
以上面的内容为模板,添加你的include path,然后就可以自由的跳转了。在.vscode文件夹下新建c_cpp_properties.json。当你想要ctl+鼠标左击跳转到三方库的定义的时候请往下看。如果有下划线表示找不到路径,请检查一下你的路径。
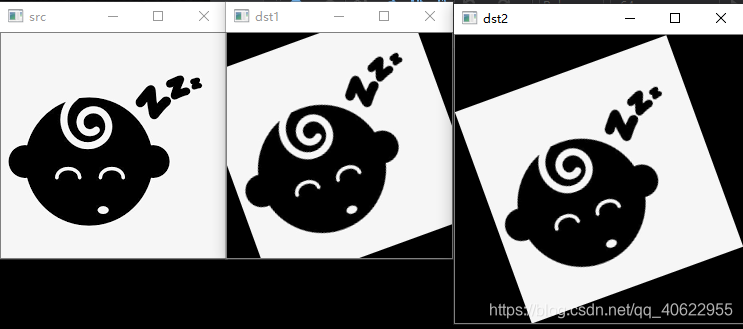
摘要:opencv里面似乎没有直接的旋转图片的接口,这里实现一个旋转任意角度的方法,在旋转的时候调用opencv里面的仿射变换函数实现。有两种旋转模式:一种按图片中心旋转,尺寸与原图一致;另外一种模式是扩充图片尺寸以包含所有像素点。文章目录1. 示例:2. 原理旋转平移的坐标变换3. 两种方式4. 源码1. 示例:2. 原理旋转平移的坐标变换设有任意一点p,在平面直角坐标中其坐标为(x,y),在平
简介:本篇文章展示pytorch做图像分类的完整过程。因为在我的应用场景下图片特征简单,对计算速度有要求,所以把网络模型写得很小(当然最终的模型要保密啦),加入了SPPnet对输入的图片尺寸没有要求。我的训练数据集结构如下:数据集划分参考pytorch图像分类完整流程如下导入依赖库import torchimport torch.nn as nnimport torch.nn.functional
opencv(C++)的kmeans
在工业场景中,正常样本往往是大量的,而且相对容易获取,比如符合质量要求的产品或零件。而缺陷数据通常较少,因为缺陷会导致产品被剔除或需要返工修复,从而增加生产成本和时间成本。此外,不同类型的缺陷样本也可能具有较强的特异性,涉及到领域专业知识和经验的积累,并且需要人工手动标注。在这种情况下,缺乏缺陷样本会导致深度学习模型无法对缺陷进行准确区分,存在过拟合的风险。用检测行业的话来说就是容易“漏检”,在工
