




- @newlw
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近年来,随着科技研究和学术水平的快速发展,机器学习算法开始走入更多人的视野当中。自然语言处理(Natural Language Processing,NLP)和计算语言学(Computational Linguistics)便是其中一个主要的分支。这个分支是一门跨学科的研究领域,它试图找出自然语言的规律,建立运算模型,最终让电脑能够像人类般分析,理解和处理自然语言。

深度神经网络可以有效地挖掘原始数据中的潜在特征,而无需大量数据预处理和先验经验。神经网络在计算机视觉、语音识别和自然语言处理方面取得了一系列的成功,当
简单线性回归(simple linear regression) 简单线性回归通常就是包含一个自变量 x 和一个因变量 y,这两个变量可以用一条直线来模拟。如果包含两个以上的自变量就叫做多元回归(multiple regresseion) 被用来描述因变量 y 和自变量 x 以及偏差 error 之间关系的方程叫做回归模型线性回归的目的是要得到输出向量 Y 和输入特征 X 之间的线性关系,求出 。

我们可以直接使用一阶导数算子或者二阶导数算子对图像做卷积来提取图像的边缘,但是这些做法有一定的缺点,一方面是检测的正确率不够高,另一方面提取的边缘不是单像素长的。Canny边缘检测是一种更高级的方法,可以解决上述问题。其中前两个步骤相当于是朴素的边缘检测算法,第三个步骤是为了将边缘固定为单像素宽,第四个步骤是为了剔除假边缘。

本文研究基于深度学习的古汉语自然语言处理方法,重点解决断代、断句、分词和词性标注等任务。采用Bi-LSTM神经网络构建模型,通过手工标注语料进行训练。实验表明,断代准确率达80%以上,断句和分词标注模型效果良好。研究成果可辅助古文研究者提高工作效率,促进古汉语信息化和大型语料库建设。创新点包括:构建高效断代模型、自动学习断句规则、提出分词标注一体化方法。模型与语料库可形成良性循环,持续提升处理精度
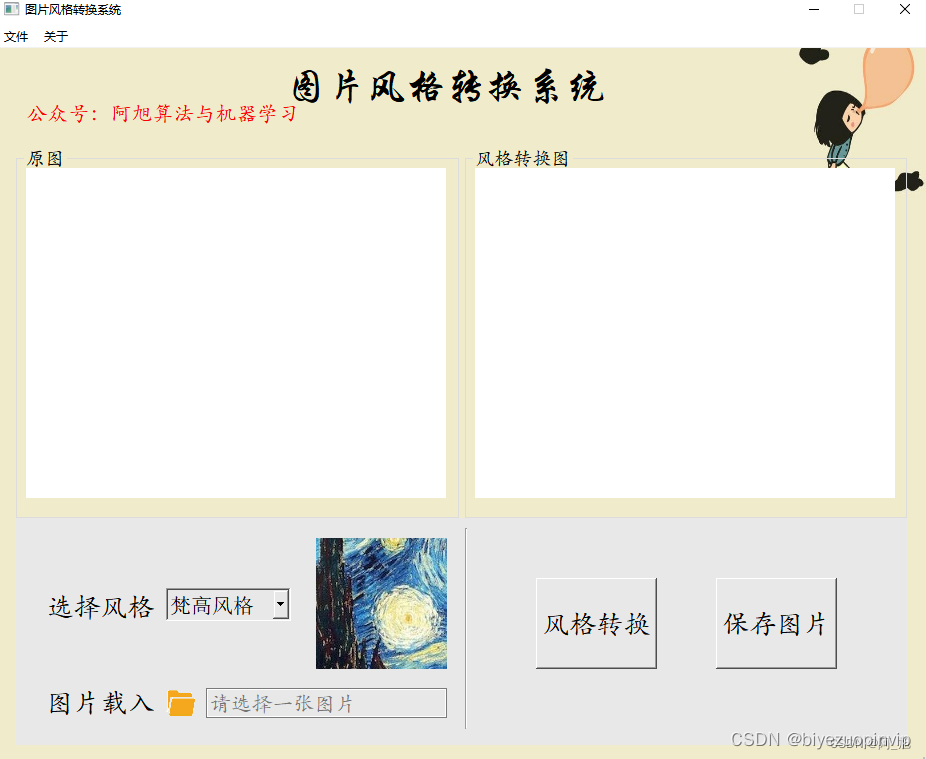
本文提出了一种基于深度学习的图片风格转换系统。系统采用离线模型优化的快速图像重建方法,通过VGG-19网络提取内容和风格特征,实现了高效风格迁移。相比传统的在线优化方法,该系统显著提升了处理速度。论文详细介绍了纹理建模、图像重建等关键技术,并对比了参数化与非参数化风格迁移算法的差异。系统实现包括核心算法设计、UI界面开发及功能模块集成,最终展示出多样化的风格转换效果。实验结果表明,该方法在保留内容
假设一个用户需要在Pubmed生物医学文献检索系统中找出蛋白质磷酸化修饰的一些信息,用户可能想要输入关键词phosphorylate(磷酸化),然后用户想得到所有(当然不可能找出所有的被磷酸化修饰的蛋白质,有些蛋白质研究人员们还在进一步在探索,这里的所有指的是目前已经发现的并且已经被收录于MEDLINE文献数据库中的所有被磷酸化修饰过的蛋白质)被磷酸化修饰过的蛋白质,以及修饰的激酶和修饰的位点,并

本文设计并实现了一个基于协同过滤算法的电影推荐系统。系统采用微信公众号作为交互平台,用户通过发送指令获取个性化电影推荐。研究首先分析了协同过滤算法的原理及优缺点,然后构建了包含数据采集、推荐算法、用户评价等模块的系统架构。系统实现采用Python技术栈,通过爬虫获取电影数据,使用用户评分曲线相似度计算进行推荐,并针对冷启动问题提出了优化方案。测试结果表明,该系统能有效实现个性化推荐功能,为用户提供

本文介绍了一个基于深度学习的银行卡号识别系统,使用CRNN模型(CNN-BLSTM-CTC)实现卡号识别,EAST算法实现卡号定位,并通过PyQt5构建交互界面。系统在Windows平台运行,支持自动和手动两种定位方式。训练数据通过预处理生成不定长度数据集,模型在10个epoch内收敛。虽然受限于训练数据规模,系统对部分颜色相近的卡号识别效果欠佳,但整体实现了银行卡号的自动定位与识别功能。项目提供

本研究将采用Python编程语言和相关的机器学习技术,结合自然语言处理理论,设计并实现一种基于Python的邮件分类系统。具体方法如下:数据收集与预处理:1、收集包括垃圾邮件和正常邮件的邮件文本数据,并进行预处理,包括文本清洗、词干提取等操作,以提高模型的泛化能力。4、系统优化与改进:根据测试结果和用户反馈,对系统进行优化和改进,包括算法优化、界面优化等,提高系统的用户体验和实用性。该系统可以通过
