




- @weixin_38346042
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
寻找特定位置,runner以两倍速前进,chaser一倍速,当runner到达tail时,chaser即为所求解。给定一个链表和一个数值,写一个函数重新排序链表,使得小于给定值的节点排在链表的左边,大于给点值的节点排在链表右侧。在head之前并指向head只要涉及操作head节点,当头节点操作不确定的时候,不妨创建dummynode;并且可以用一个简单的小testcase来验证(例如长度为4和5的
配置c++ 编译时的选项,包括编译器的路径、C/C++标注, 指定头文件的搜索路径(如opencv等)该工具可以自动识别MinGW编译器的安装位置,如果没有添加到环境变量中,它会自动帮忙配置到环境变量。,这样将3个json拷贝到其他目录,也可以运行和调试c++程序。如果未下载MinGW,它会提示你下载,然后帮忙自动配置环境变量。:设置头文件的搜索路径,让编译器可以找打相应的头文件。完成安装后,会自
在这篇文章中,我们将展示如何使用一个名为Mask RCNN(基于区域的卷积神经网络)的卷积神经网络模型来进行目标检测和分割。使用mask - rcnn,我们不仅检测对象,我们还获得一个灰度或二进制mask对象。Mask rcnn最初是在2017年11月由facebook的人工智能研究团队使用Python和caffe2推出的。我们将在c++和Python中共享OpenCV代码来加载和使用模型。The
原理: L1正则是基于L1范数和项,即参数的绝对值和参数的积项;L2正则是基于L2范数,即在目标函数后面加上参数的平方和与参数的积项。 区别:1.鲁棒性:L1对异常点不敏感,L2对异常点有放大效果。2.稳定性:对于新数据的调整,L1变动很大,L2整体变动不大。 答案解析 数据分析只需要简单知道原理和区别就行,公式推导不需要,面试过程中也不会出现。:逻辑回归里面,对于正负例的界定,通常会设一个阈值,
在没有过拟合的情况下,相同模型结构下,一般模型的参数量和计算量与最终的性能成正比,在比较不同模型性能时,最好能保持模型参数量和计算量在相同水平下,因此相应参数的统计很重要。这里只进行理论计算,最终的效果(内存和速度)还和网络结构,代码实现方式、应用的平台性能等条件有关系,例如使用GEMM实现CNN时会增加内存,但实际的计算速度会加快。相同条件下,GRU由于时序依赖关系不能并行加速,实际速度会比CN
1. 简要说明很多高校小伙伴,面临就业找工作,经常会问到没有项目经验该怎么办。关于这个问题通过网上找开源项目自学习,几乎成为获取项目经验的唯一途径。很多人会问开源项目哪里找,不会搜等等问题。这篇文章我将讲解如何在github中高效的找开源项目,github本身就是一个巨大的开源宝库,而且github开源项目也是最全的。2. github2.1 搜索github注意的点github项目页面中,主要包
针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(Bot
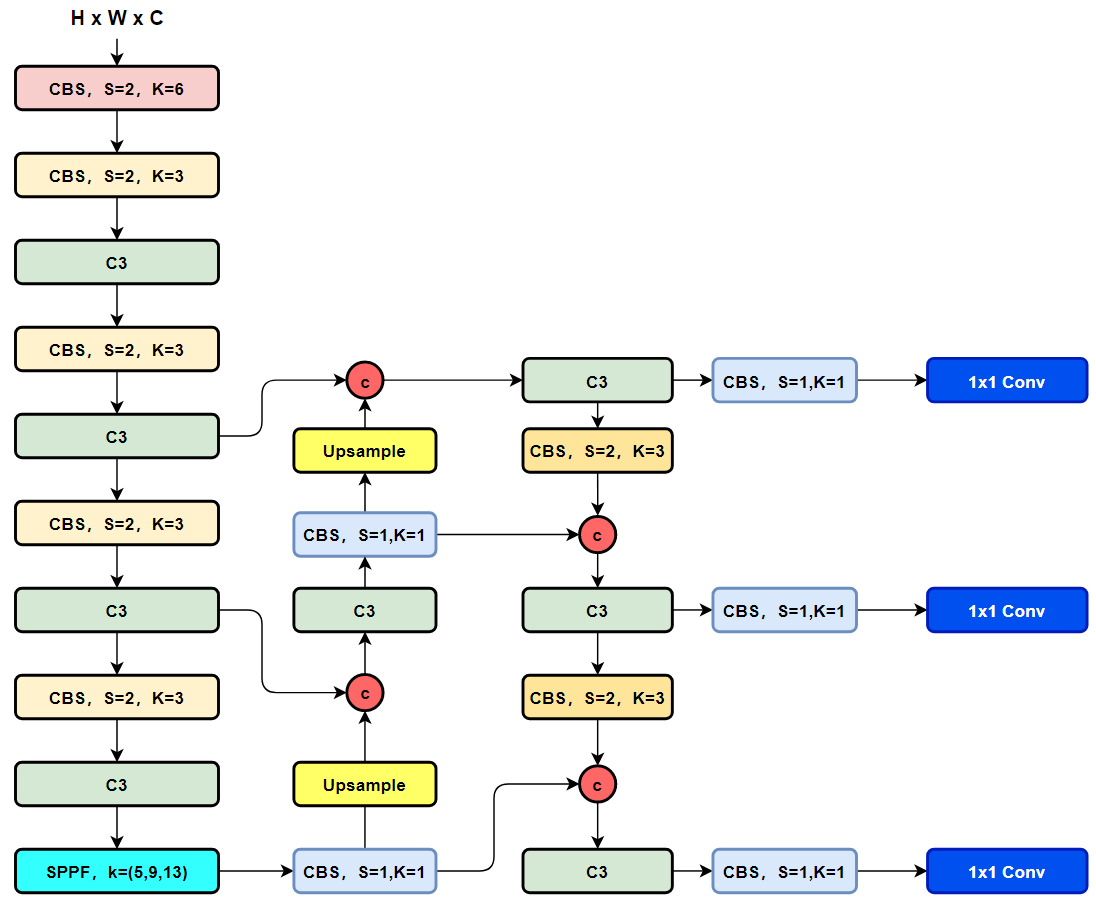
众所周知,在目标检测领域,YOLO 系列模型一直充当着老大哥的角色。虽然其检测性能表现优异,但一直被广为诟病的便是其后处理过于繁琐且耗时,不好优化且不够鲁棒。最近,基于的端到端检测器(DETR)取得了显著的性能。然而,DETR的高计算成本问题尚未得到有效解决,限制了它们的实际应用,并阻止它们充分利用无后处理的优点,例如非最大值抑制(NMS)。于是乎,百度近期又基于 DETR实现并开源了第一个实时的

但各个节点还是独立的,并没有关系,并没有上个节点的next存放了下个节点的地址。上个节点next存放了下个节点的关系,就可以从当前节点找到下个节点,所以我们说各个节点是连着的,这样才能称为一个链表。实现指向下个节点,当j=i时,输出找到节点p_i对应的数据。按照生成head节点的方法,生成子节点也可以用类似的方法。,链表的前一个节点的指针域,存放的是下一个节点的地址。,也就是说随着节点的移动,他们
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。说明:每次只能向下或者向右移动一步。网格的左上角 (起始点在下图中标记为。机器人试图达到网格的。的路径,使得路径上的。:一个机器人位于一个。
