
写文章




- @m0_58419490
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
pyspark.sql.utils.AnalysisException: Path does not exist: file:/Digdata-java/java_project/kafka_pro
由报错可知是由于路径错误引起的,首先检查路径是否书写错误,检查过后发现路径并无错误,此时仔细查看代码路径 ,发现有两处变蓝,添加转义符或在引号前面加“r”即可恢复正常。
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Lj
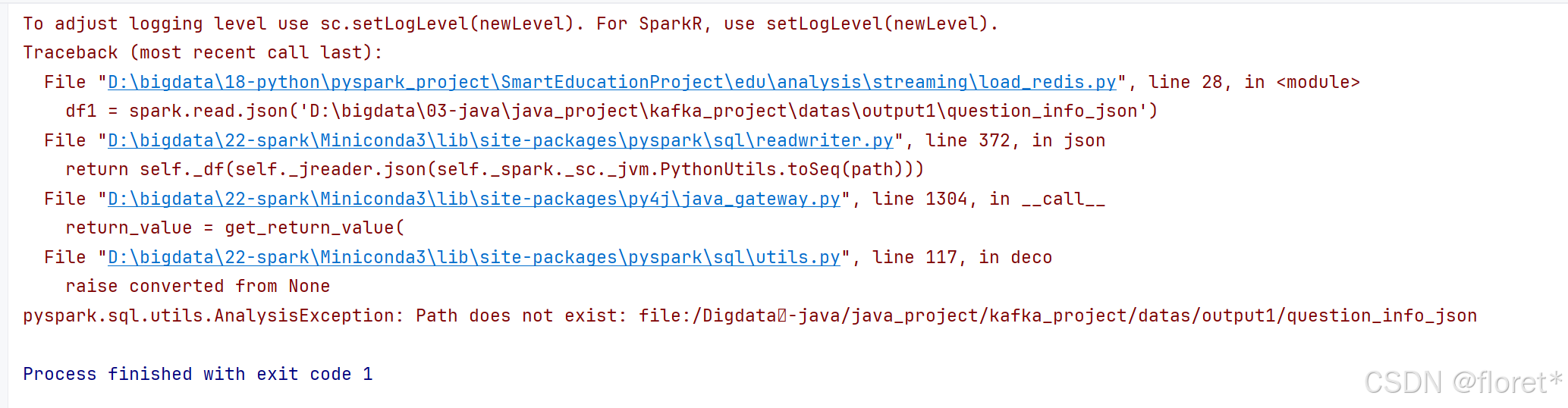
在运行pyspark时出现了以下错误,可以看出是hadoop的问题,这时,只需要把hadoop下的hadoop.dll文件拷贝到C:\Windows\System32下,重启pycharm即可运行。
从hive导出数据到mysql(超详细)
用kettle把hive中的数据导出到mysql

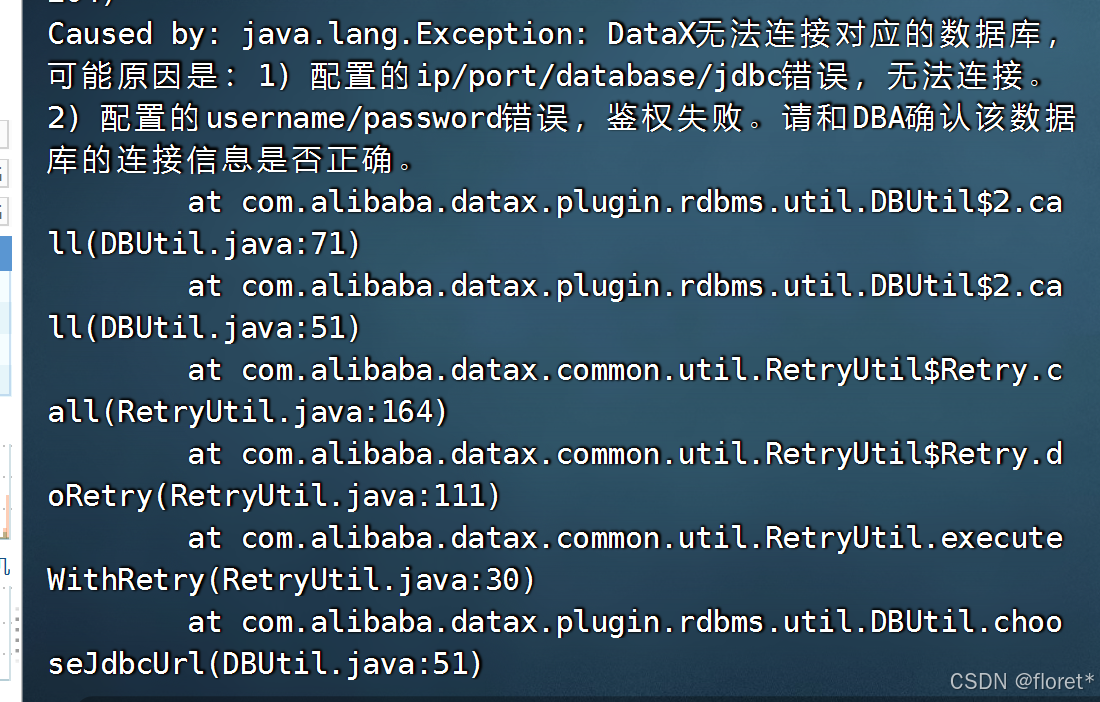
Caused by: java.lang.Exception: DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的usern
用datax把mysql中的数据导入到hive时报如上错误 ,在检查账号密码以及数据库都正确的情况下,仍然报以上错误。拷贝一份mysql的驱动包即可。
Caused by: java.lang.Exception: DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的usern
用datax把mysql中的数据导入到hive时报如上错误 ,在检查账号密码以及数据库都正确的情况下,仍然报以上错误。拷贝一份mysql的驱动包即可。
阿里云(FAILED: ODPS-0130071:[12,1] Semantic analysis exception - column view_count in source has incom)
可以看出是由于数据类型导致的,这里count之后数据类型为bigint。有两种解决方案,一种是重新建表,数据类型为bigint。另一种是用cast进行数据类型的转换。在执行插入语句时,出现了如下错误。查看我们的建表时数据类型为int。

Caused by: java.lang.Exception: DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的usern
用datax把mysql中的数据导入到hive时报如上错误 ,在检查账号密码以及数据库都正确的情况下,仍然报以上错误。拷贝一份mysql的驱动包即可。
到底了