




- @wsdc0521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在python中连接hive和impala有很多中方式,有pyhive,impyla,pyspark,ibis等等,本篇我们就逐一介绍如何使用这些包连接hive或impala,以及如何通过kerberos认证。
impala数据血缘与数据地图系列:----------------------------------------------------------------------------------------------Impala血缘:CDH官方文档impala数据血缘:https://docs.cloudera.com/documentation/enterprise...
最近在内部做了个分享,顺便画了一下这次impala数据血缘的架构图:架构图:如果想了解如何实现请参照前面几篇文章:impala数据血缘与数据地图系列:1. 解析impala与hive的血缘日志2. 实时采集impala血缘日志推送到kafka3. 实时消费血缘记录写入neo4j并验证---------------------------------Impala血缘 架构图-------------

impala数据血缘与数据地图系列:1. 解析impala与hive的血缘日志2. 实时采集impala血缘日志推送到kafka-----------------------------------------实时采集impala血缘日志推送到kafka-----------------------------------------------------前两篇介绍了如何采集impala和hiv
我使用的是CDH6版本,开源版类似。/etc/hadoop/conf/hdfs-site.xmlhdfs-site.xml中配置了HA通过以下命令查看两个namenode的状态:hdfs haadmin -getServiceState namenode202hdfs haadmin -getServiceState namenode177例子:判断nameno...
Logstash依赖于JVM,在启动的时候大家也很容易就能发现它的启动速度很慢很慢,但logstash的好处是支持很多类型的插件,支持对数据做预处理。而filebeat很轻量,前身叫logstash-forward,是使用Golang开发的,所以不需要有java依赖,也很轻量,占用资源很小,但功能也很少,不支持对数据做预处理。因此一般都是将filebeat+logstash组合使用,在每个节点部署
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据, 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。作为大数据生态最重要的组件之一,HDFS充当着大数据时代的数据管理者的角色,为各个分布式计
加载HDFS文件数据到表:LOAD DATA INPATH "hdfs_source_path" OVERWRITE INTO TABLE tbl_nm;加载本地文件数据到表:LOAD DATA LOACL INPATH "loacl_source_path" OVERWRITE INTO TABLE tbl_nm;将数据导出至本地路径下:insert overwrite...
前面的文章我们简单介绍了什么是数据倾斜,今天我们来讲一下如何定位是否出现了数据倾斜,以及是在什么阶段出现的数据倾斜。
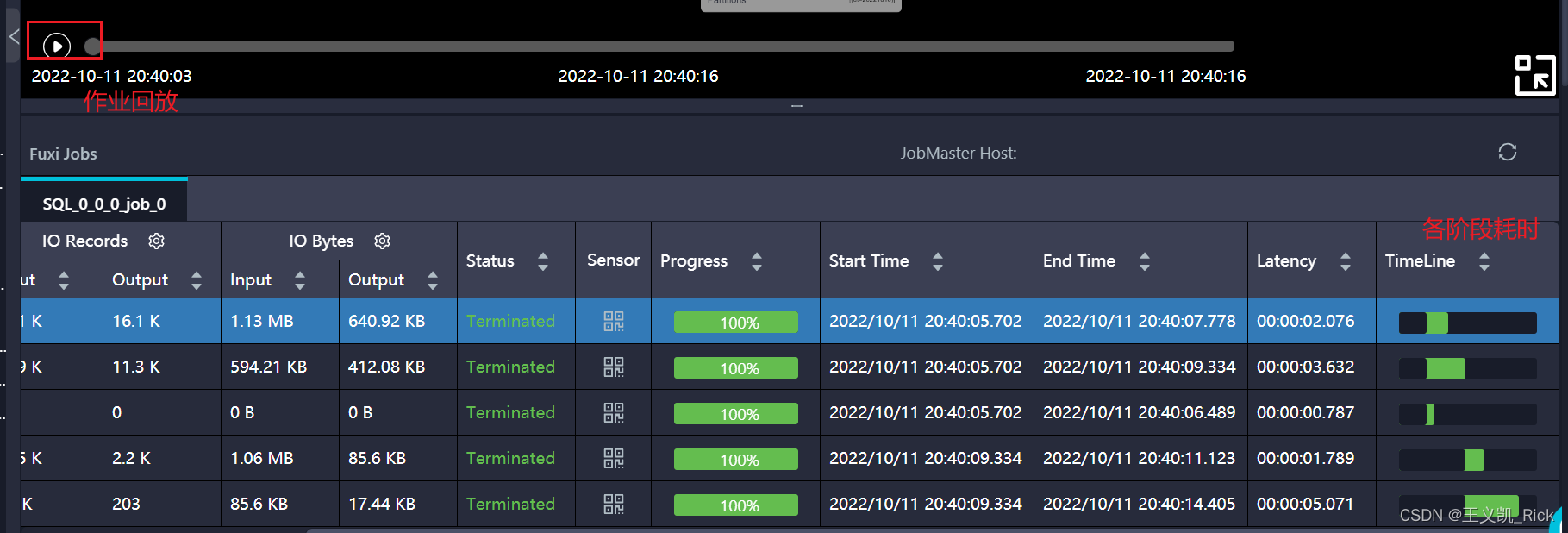
数据倾斜是指在并行计算模式下(map-reduce框架,数据被切分为N个片段,分发到不同的计算节点上,单独计算),部分节点处理的数据量远大于其他节点,造成该节点计算压力过大,从而导致少数节点的运行时长远远超过其他节点的平均运行时长,进而影响整体任务产出时效,造成任务延迟,这个现象就是数据倾斜。...