- @h1453586413
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因为大模型本身的限制问题,导致大模型缺少部分资料,因此在咨询大模型具体的问题之前,需要先找到问题相关的文档,然后告诉大模型,大模型才能回答我们的问题;给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!所以,相较于传统的RAG技术,基于智能体的RA
研究报告与行业分析一再提示:agent 的产业化不是简单的“把模型接到 API”,而是把模型嵌入到复杂的软件工程、运维、安全与治理体系中。给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!研究与从业报告指出,要实现可靠的 agent,需要新型的测
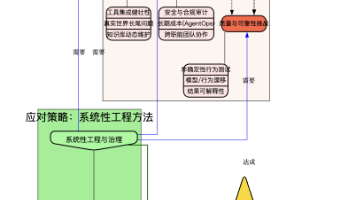
给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。有了记忆,代理可以随着时间的推移不断改进,记住过去的行为,并做出更具凝聚力的
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括CSDN粉丝独家福利这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以免费领取读者福利:对于0基础小白入门:如果你是零基础小白,想快速入门大模型是可以考虑的。一
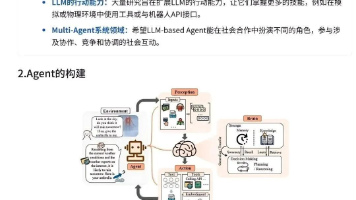
曾几何时,我们还在为“写个脚本实现自动化”而兴奋不已。如今,AI 已经进化成了能够自主感知环境、做出决策并执行任务的智能体(Agent)。它不再是简单的自动化脚本,而是一个拥有“大脑”的数字化伙伴。Agent 的核心概念与优势特性说明🤖 自主性能够独立思考和行动,极大减少对人工干预的依赖👀 感知环境可以接收并理解其所在环境的信息(如数据、用户输入、API反馈)🧠 决策与规划能基于感知信息制定
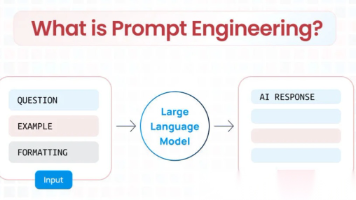
本文介绍了AI Agent从传统问答系统向具备任务规划能力的智能体演进,指出仅靠提示工程不足以构建高效稳定的Agent,关键在于"上下文工程"。文章对比了两者区别,阐述了上下文工程的重要性及核心要素,包括系统提示设计、工具设计、示例提供和历史管理。同时提出了应对长时程任务的三大策略:压缩、结构化笔记和子代理架构,帮助读者构建性能更佳的AI Agent系统。
AI智能体(AI Agent)是具备学习、推理和决策能力的自主执行任务的人工智能系统,应用于客服、数据分析、自动驾驶等领域。它们通过分析环境数据做出反应,并持续学习以提高效率和准确性。随着技术进步,AI智能体将在未来工作和生活中扮演越来越重要的角色。各种场合提到AI智能体(AI Agent),那么AI智能体究竟是什么呢?本文简单整理通俗的解读,给大家做参考。AI智能体(AI agent)是指能够自
回到开头那个问题:一张图能装下多少文字?DeepSeek用这个30亿参数的小模型告诉我们,答案不是一个固定的数字,而是取决于你愿意接受多少模糊度。10倍压缩几乎无损,20倍压缩还能保留核心信息。这个发现,可能比一个好用的OCR工具更有价值。AI如何像人一样,在有限的资源里,智能地选择记住什么、遗忘什么。不是追着热点跑,而是在探索AI的本质。

能感知环境、自主决策并执行任务的AI应用,核心是"目标拆解+工具调用"能力。

视频在这里:https://www.youtube.com/watch?langchain的ppt在这里:https://docs.google.com/presentation/d/1Z-TFQpSpqtRqWcY-rBpf7D3vmI0rnMhbhbfv01duUrk/edit?manus的ppt在这里:https://drive.google.com/file/d/1QGJ-BrdiTGsl