




- @qq_26442553
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
朋友们,大模型现在真的真的真的(重要的事情说3遍)在企业中开始落地了,算法大佬们在卷大模型训练,后端老哥们在卷多Agent架构和Harness工程,咱们数据开发呢?是不是感觉手里刚写完的、优化了三遍的SQL脚本突然就不香了?是不是半夜惊醒,脑补出老板那张严肃的脸,拍着你的肩膀说:“小张啊,模型已经觉醒了,不仅能写代码还能做报表还能做分析,你这天天跑数的岗位,咱们就优化掉吧。

5月大数据行业就业形势分析显示,行业门槛明显提高,市场逐步淘汰低学历、低能力者,但优质机会仍存。涤生教育就业数据亮眼,社招25人成功上岸,薪资涨幅显著,部分非科班学员斩获40w+高薪。中大厂面试更重AI技术和实战能力,难度提升;外包公司门槛较低,掌握八股文即可获取15k-22k岗位。典型案例包括:7年非科班学员获50w中大厂offer、应届生被裁后快速斩获35w+岗位等。数据显示学历弱势者通过能力

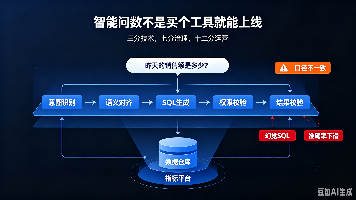
《智能问数落地指南:从技术路线到企业实践》 摘要:智能问数技术虽发展六年,但实际落地效果两极分化。文章系统梳理四代技术演进(规则模板、深度学习NL2SQL、大模型+语义层、Agent化协同),指出当前主流方案是统一语义层+指标平台路线。企业落地需遵循"三步走":需求诊断(聚焦高频场景)、POC验证(业务准确率≥85%)、规模化运营(持续迭代)。关键避坑建议包括:优先单场景做透、
5月大数据就业市场呈现两极分化:中高端岗位面试难度提升,AI技术成为考核重点,但学员通过系统准备仍取得显著成果。涤生教育数据显示,25名社招学员成功入职,薪资涨幅普遍达50%-200%,其中非科班背景者通过能力提升实现30-50万年薪突破,7年经验大专学历者获27.5k月薪。市场趋势显示:1)学历弱势者需强化实战能力与项目打磨;2)AI技术融合成为职业发展新门槛;3)二线城市优质机会涌现(如30万

Apache Doris与StarRocks高频面试题解析 本文聚焦大数据实时方向核心面试考点,梳理Doris/StarRocks的架构原理、性能优化与表设计: 架构对比:存算一体(高性能)与存算分离(云原生弹性)的选型逻辑,详解数据分布、版本控制与半数写入机制。 性能优势:列式存储+向量化引擎+MPP并行架构,对比ClickHouse的Join短板,强调CBO优化器与多副本高可用设计。 表模型与

Spark AQE(自适应查询执行)动态优化机制分析:AQE通过运行时统计信息弥补了Catalyst静态优化器的不足,在Shuffle边界动态调整执行计划。其三大核心功能在实际生产中可能引发严重问题:1. 动态合并分区机制可能因压缩数据误判导致OOM,需通过强制repartition或调整最小分区数解决;2. 动态Join策略切换时可能因压缩数据解压膨胀引发Driver内存溢出,建议降低广播阈值或

【秋招备战指南:稳扎稳打是关键】随着暑期实习结束,秋招战役即将打响。本文针对2024届毕业生提供实用建议:1. 时间紧迫性:秋招8月启动,中大厂10月截止,需尽早投递;2. 核心准备:(1)夯实技术基础(数据结构/SQL/大数据框架);(2)重点关注AI技术融合应用;(3)精细化打磨简历,确保内容真实可控;3. 投递策略:分层投递+实时记录,建议关注企业招聘公众号获取第一手信息;4. 面试技巧:提

Doris 湖仓一体凭借其强大的功能、先进的架构和核心技术,为企业数据管理提供了高效、智能的解决方案。在大数据时代,它就像一座坚实的桥梁,打通数据湖与数据仓库的壁垒,让数据流转更顺畅,价值释放更充分,助力企业在数字化转型的浪潮中抢占先机!

对数据的实时性要求越来越高。传统的离线数仓(T+1)已无法满足业务对秒级响应的需求,而实时数仓和数据湖(Data Lake)架构正成为主流。然而,如何将业务数据库中的变更数据(Insert/Update/Delete)低延迟、高可靠、无侵入地同步到下游系统,一直是构建实时链路的关键挑战。

AI浪潮下职场生存指南:岗位重塑而非取代 当前AI技术迅猛发展引发职场焦虑,但实际并非岗位消失,而是标准提升。未来3年,多数岗位将经历"AI+"转型: 岗位重塑:数据分析、运维等传统职位将借助AI工具提效 就业趋势:头部大模型岗位门槛高(需211硕士+),更多机会在行业应用层 最新案例:20位求职者成功转型,包括: 3年经验双非硕士斩获45W offer 6年普本开发者获60W