- @JiShuiSanQianLi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
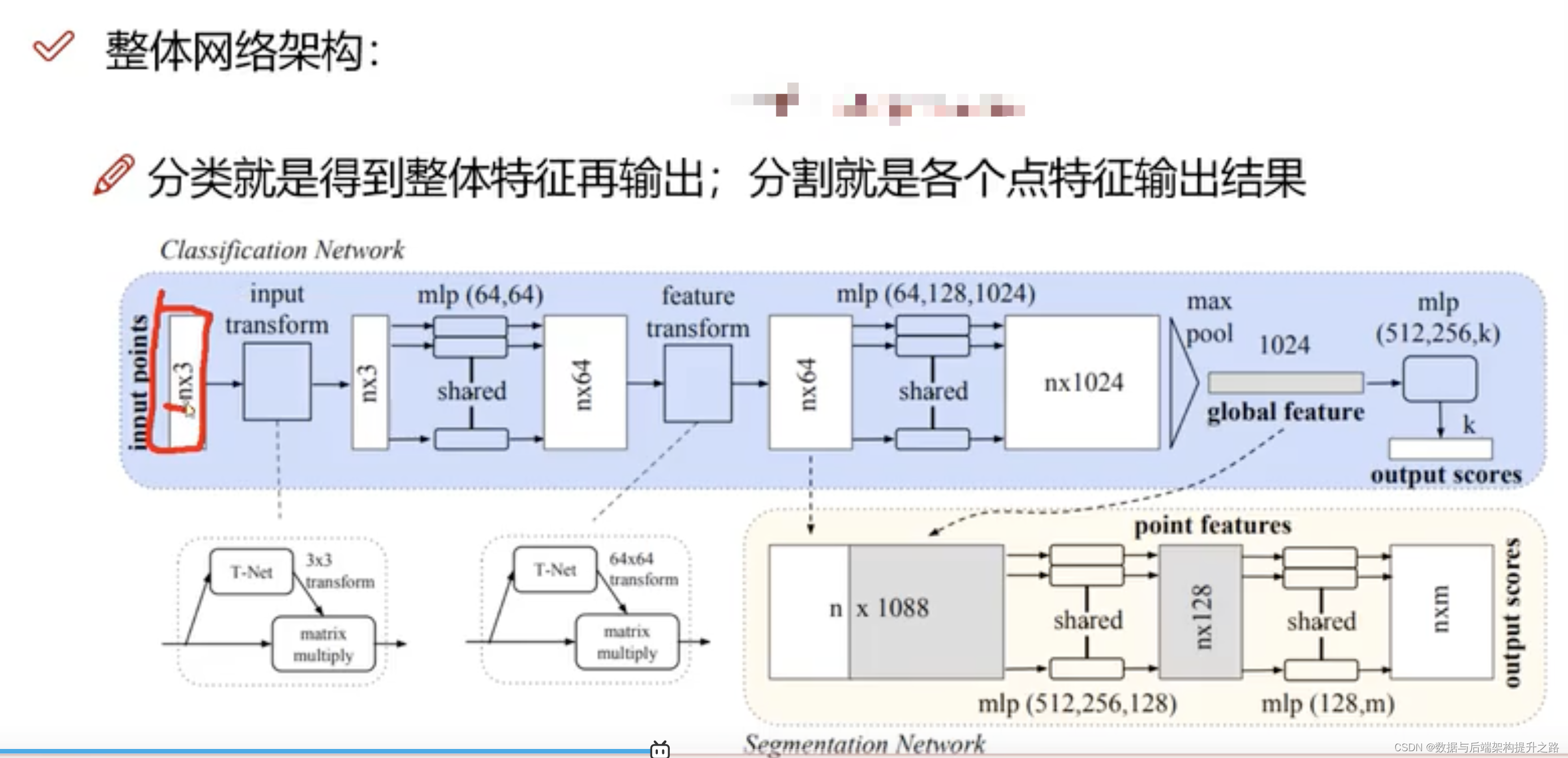
Seata分布式事务模式深度解析 摘要: Seata作为阿里开源的分布式事务解决方案,提供AT、TCC、Saga和XA四种模式。本文从架构师视角对比分析三种主流模式:AT模式通过全局锁实现自动事务管理,适合简单CRUD但存在性能瓶颈;TCC模式通过资源预留保证强一致性,适合核心资金链路但开发复杂;Saga模式采用补偿机制处理长事务,适合跨系统业务但缺乏隔离性。文章深入剖析各模式原理、适用场景及实战
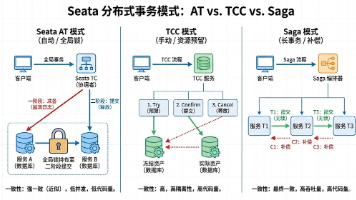
PostgreSQL和MySQL的MVCC实现差异主要体现在版本存储方式上:PostgreSQL采用"表内版本堆"模式,所有版本都存储在表文件中,通过xmin/xmax判断可见性,更新操作会追加新版本并标记旧版本过期,这种设计使得回滚快速但容易导致表膨胀;MySQL InnoDB则采用"主表+Undo日志"模式,当前版本存储在聚簇索引中,历史版本保存在Und
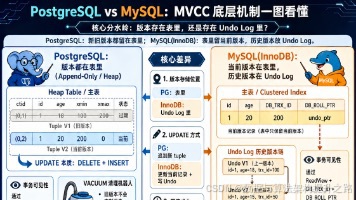
本文系统介绍了开源分布式向量数据库Milvus的核心架构与索引选型。Milvus采用分层解耦设计,包含Proxy接入层、Coordinator协调层、Workers执行层和DurableStorage存储层,支持弹性扩展。重点解析了FLAT、IVF_FLAT、IVF_SQ8、HNSW、SCANN和DISKANN六种索引类型的特点及适用场景,并对比了L2、IP和COSINE三种相似度量方式。作为RA
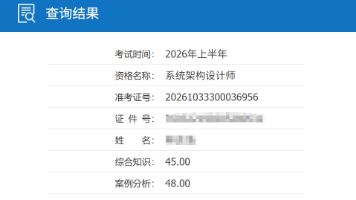
综合知识(上午场)不再仅仅停留在架构概念的表面。官方正在通过极其底层的技术细节(如操作系统硬件中断的边界界定、网络协议栈的底层机制、信息安全核心算法等)来过滤掉技术底盘不扎实的考生。这些“死知识”往往是容易被日常高层业务开发所忽略的盲区。无论是案例分析还是综合知识,题目背景都在快速剥离传统的单体应用或简单信息化系统,全面拥抱高复杂度的现代技术栈。云原生架构治理、大数据处理管道、高并发分布式中间件,
本文详细记录了在资源受限的Jetson Orin Nano Super开发套件上部署ResNet18模型的完整技术路径。通过FP16基线测试、知识蒸馏、结构化剪枝、QAT显式量化和DLA探测五个阶段,作者揭示了模型优化过程中容易被忽视的关键问题:INT8量化后因CPU调度开销导致吞吐量意外下降50%,通过CUDAGraph静态化调度实现1664FPS的反超;指出PyTorch剪枝接口仅作数值置零的

本文系统介绍了大语言模型对齐训练的三种主流方法:PPO(RLHF)、DPO和KTO。PPO通过强化学习训练奖励模型,效果最佳但成本最高;DPO直接优化偏好数据,性价比高;KTO只需二元标签,最经济实用。文章结合Hugging Face的trl库实现方案,特别探讨了这些方法在具身智能领域的应用,指导开发者根据资源状况选择最优对齐策略:PPO适合追求极致性能,DPO适合平衡成本与效果,KTO则适合预算

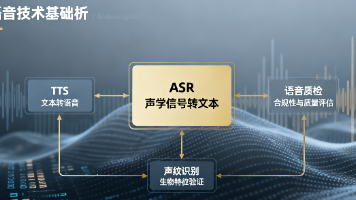
摘要:AI大模型推动自动语音识别(ASR)技术革新,端到端模型突破传统级联架构局限。开源工具Wenet-e2e等提供工业级解决方案,全链路对话模型将延迟降至650ms。2025年全球语音市场预计超500亿美元,开发者可通过GitHub资源库入门,关注多模态融合和低延迟优化等趋势,把握语音AI时代机遇。
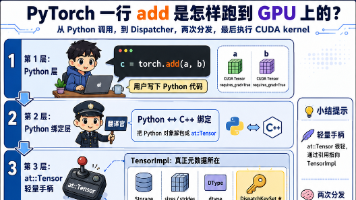
本文深入剖析了PyTorch中torch.add(a,b)调用的完整执行路径,揭示了其核心调度机制。PyTorch通过七层抽象完成调用,关键组件是Dispatcher系统,它基于TensorImpl中的DispatchKeySet(64位掩码)动态决定算子执行路径。文章详细讲解了:1)PyTorch的三层架构(c10/ATen/torch);2)Tensor作为轻量级手柄的设计;3)Dispatc
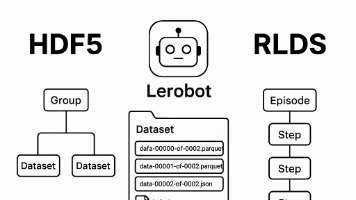
HDF5如本地硬盘,切片快、小数据友好;LeRobot云原生Parquet,边下边训,大模型预训练首选;RLDS/TFDS序列强,离线RL神器,TF生态无缝。按场景挑格式,别再全量下载!
本文深入探讨了点云数据处理的关键技术,包括数据清洗、降噪、简化、配准等预处理步骤,为后续的SLAM和语义分割任务奠定基础。特别地,文章详细介绍了PointNet和PointNet++这两个先进的深度学习算法,它们能够有效处理无序点云数据并提取特征。此外,还探讨了三维重建中的NeuralRecon系统,它采用多尺度方法和GRU网络来优化三维结构的生成。文章强调了这些技术的优点和面临的挑战,展望了在三