登录社区云,与社区用户共同成长
邀请您加入社区
基于服务过1000+企业的经验,我们设定了五大筛选维度:功能覆盖度(是否支持题库管理、自动判分、防作弊)、易用性(零代码搭建、模板丰富度)、稳定性(高并发支撑能力)、性价比(万元内能获得的核心功能)以及拓展性(是否支持API对接与数据导出)。在实测了问卷星、考试宝、魔学院和人人秀四款主流工具后,我们一致认为:对于预算一万元以内的中小微企业,人人秀答题在功能完整度、互动趣味性、性价比和数据沉淀能力上
今年的申请者展现了人工智能、适应能力、创新与本地领导力如何协同发力,在可及性、可负担性与可靠性仍然有限的社区中应对紧迫挑战。阿联酋为应对全球性挑战的创新解决方案而设立的先锋奖项——扎耶德可持续发展奖,已正式结束2027届申报,共收到来自177个国家的10,233份申报,创历史新高,覆盖健康、食品、能源、水资源、气候行动及全球中学生奖六大类别。申报结束后,奖项将进入评审阶段。每年,奖项在健康、食品、
ChatGPT 和 Codex 的出现,让人第一次可以用自然语言调度复杂能力。Plus 和 Pro 的存在,让这种能力从偶尔使用变成稳定、高频、复杂任务中的工作环境。但越是这样,越要意识到:真正重要的不是 AI 能不能做,而是 AI 能不能被正确控制。AI 可以生成文章。但人要控制观点质量。AI 可以修改代码。但人要控制工程风险。AI 可以拆解任务。但人要控制目标方向。AI 可以长时间协作。但人要
Python深入解析装饰器:从基础到高级应用## 装饰器基础概念装饰器是Python中一种强大的语法特性,允许我们在不修改原始函数代码的情况下,为函数添加额外的功能。本质上,装饰器是一个接收函数作为参数并返回一个新函数的可调用对象。最简单的装饰器示例是一个接收函数并返回相同函数的装饰器,它实际上不添加任何新功能,但展示了基本结构:)```
量子纠缠与人工智能的协同创新正在重新定义计算的边界。DeepSeek等AI系统不仅加速了量子技术的研究,更重要的是,它们帮助我们发现和利用量子世界的新规律。这种跨维度的计算范式将不仅仅是速度的提升,更是解决问题方式的根本转变,为人类应对气候变化、疾病治疗和宇宙探索等重大挑战提供了全新的工具和方法论。
大众点评3D探店和京东3D商品展示背后,是鸿蒙3D生成能力的工具底座。Remy还支持碰一碰分享3D视频,在nova 16系列首发的3D有声照片功能可在3D空间照片任意位置添加语音旁白,还能邀请好友在微信上录制。大众点评3D自由漫步探店、京东立影裸眼3D试尺寸、京东内容助手3DGS商品建模——这些场景正在把消费决策从平面信息时代推进到立体感知时代。Remy端侧3分钟重建、V2Fun平面图片转3D模型
C++实现计算平面与平面的交线(附带源码)
车库存取管理系统主要功能模块包括系统用户(管理员、注册用户)模块管理(车辆信息、车位信息、车辆入场、车辆离场、用户账户、账户充值、收入汇总),采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取MySQL作为后台数据的主要存储单元,采用SSM框架、Java技术、Ajax技术进行业务系统的编码及其开发,实现了本系统的全部功能。
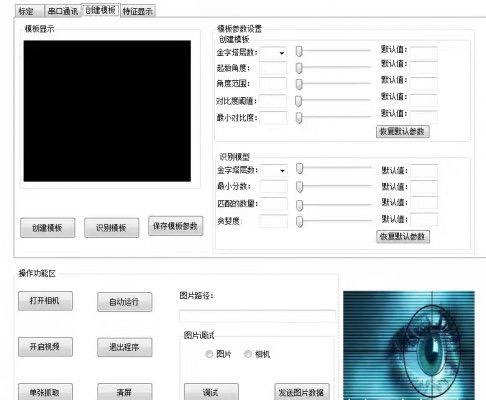
咱们今天要聊的这个C#+Halcon项目,直接把标定、通信、界面这些实用功能打包成了完整解决方案。注意第三个参数标定板描述文件必须和实际使用的标定板物理参数完全匹配,否则误差能差出个马里亚纳海沟。最后说个真实案例:某次现场调试发现标定误差忽大忽小,最后发现是串口通信的校验位设置成None导致数据错位。项目源码里有个魔鬼细节:标定数据保存时用了二进制序列化,但机器人的坐标系数据需要转成ASCII格式
本文摘要: 该研究提出了一套基于超复数广义分形流形的统一理论框架,将现代物理学多个前沿领域的关键问题纳入几何化描述体系。核心创新包括:1)建立无界广义豪斯多夫维数公理体系;2)给出精细结构常数的几何闭式解;3)通过代数退化链理论推导出64种基本粒子态;4)精确计算缪子反常磁矩;5)解释26维弦论的自洽性;6)预测中微子混合角θ13=π/21;7)揭示《易经》六十四卦与32维流形的拓扑同构;8)构建
Link: https://www.luogu.com.cn/problem/P16283在平面直角坐标系中,固定点 AAA 为坐标原点 (0,0)(0, 0)(0,0)。现在,考虑所有横坐标、纵坐标都在 000 到 202620262026 之间的整点。请你统计满足下列条件的点对 {B,C}\{B, C\}{B,C} 的数量:其中,若 A,B,CA, B, CA,B,C 三点共线,则三角形面积记
ranscan算法和最小二乘算法是两种常用的平面提取算法ranscan算法是随机采样,鲁棒性强,但是随机性导致结果不稳定最小二乘算法是全局搜索,结果稳定,但是鲁棒性差,需要配合其他算法使用在对精度要求不高的场景中,ranscan算法是首选,比如导航而在对精度要求高的场景中,最小二乘算法是首选,比如工业测量。
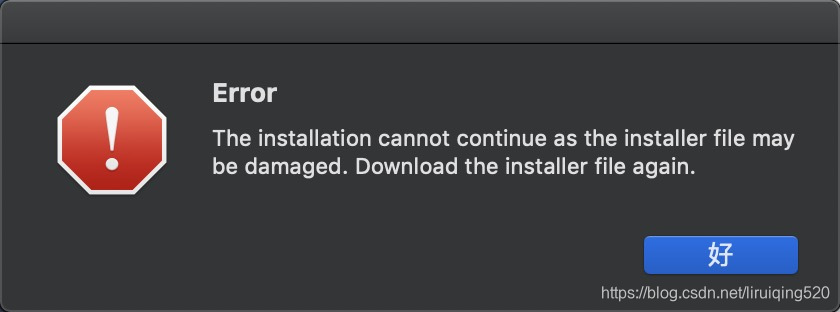
macbook M1安装adobe时总是提示如下报错:报错信息:The installation cannot continue as the installer file may be damaged. Download the installer file again.解决方法:XDM经过我的不断尝试终于解决了。主要原因就是安装包版本太高了,由于我只需要AI和PS,所以只测试了这两款软件,亲测
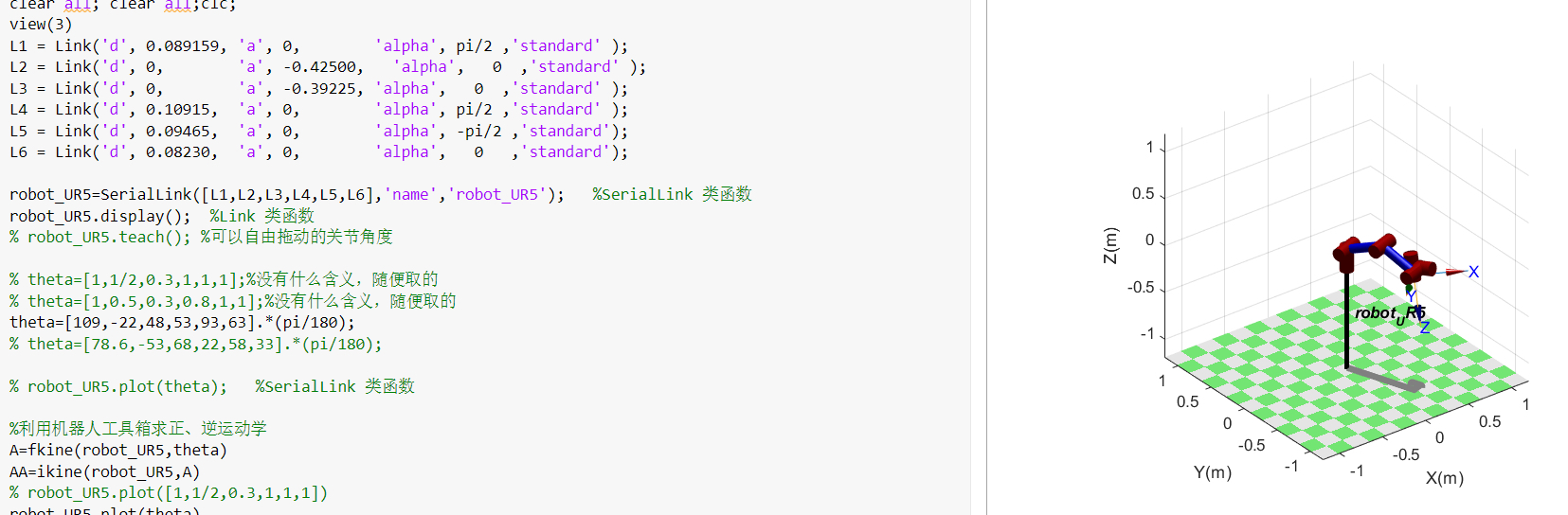
连杆机器人FK/IK基础(1)
h=d;m_s=0.5;I_s=0;m_l=5;Circle=2;
网络层理论上可以提供很多种服务。保证送达;保证 40 ms 内送达。保证按序交付;保证最小带宽;限制分组间隔变化,也就是减少 jitter。这些都属于 QoS(Quality of Service,服务质量)范畴。多跳寻路到目的端:靠目的 IP 地址;标明发送端身份:靠源 IP 地址;复用/分解到上层协议:靠 Protocol 字段;处理 MTU 不匹配:靠 Identification、DF、M
特别是夹取物体时,工具箱的纯运动学模型和Simscape带物理引擎的对比,末端抖动能差出3个数量级。尤其是做轨迹规划的时候,物理引擎带来的碰撞检测和关节力矩反馈,比纯数学建模真实多了。今天咱们就来唠唠怎么在Simscape里玩转正逆运动学,顺便对比下传统机器人工具箱的建模方式。仿真时记得打开Solver Profiler看看哪些关节在吃计算资源,UR5的第四个关节经常是性能黑洞——因为DH参数里那
2026年3月,当VS Code 1.110发布Agent Plugin预览时,大多数人看到的只是一个“新功能”。这是IDE四十年来最深刻的一次进化。VS Code不再只是一个你写代码的地方——它是你配置、分发、治理、调试和监控智能体的控制平面。问题不再是“AI会不会取代程序员”,而是“你的团队有没有准备好用控制平面的方式管理AI agent2026年下半年的竞争,将在“谁先把Agent Plug
API 是所有软件通用的数据通道;MCP 是专门给 AI 打造、带记忆、一键连所有工具的专用高速通道。
你有没有想过,AR 家具 APP 是怎么把虚拟沙发稳稳地放在地面上的?它怎么知道哪里是地面、哪里是桌面、哪里是墙壁?答案就是。AR Engine 能从摄像头画面中自动识别出各种平面——水平的地面和桌面、垂直的墙壁,甚至天花板。识别出来之后,你就能在这些平面上放置虚拟物体了。而比平面检测更进一步。它不是只给你一个平面,而是把整个环境的表面用三角形网格重建出来。有了网格数据,你就能做更精细的 AR 效
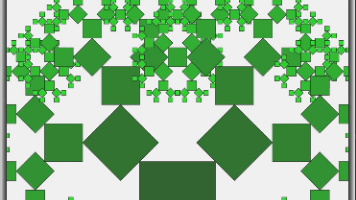
摘要:本文介绍了一个基于勾股定理的勾股树分形图生成器。该应用通过递归算法在Canvas上动态绘制分形图形,用户可实时调整递归深度、分支角度等参数,观察图形变化。代码采用TypeScript实现,包含绘图区域、参数控制面板和递归绘制逻辑,通过三角函数计算分支尺寸,实现正方形与直角三角形的层层嵌套,直观展示了数学几何之美。当角度为45°时可生成经典的对称勾股树图形。
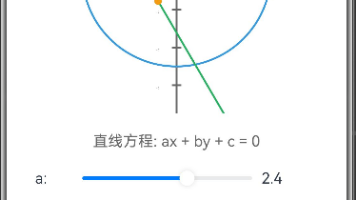
直线与圆的位置关系可视化工具 该工具通过交互式界面动态展示直线与圆的位置关系(相离、相切、相交)。用户可以调整直线方程参数(ax+by+c=0)和圆的属性(圆心坐标、半径),系统实时计算并显示圆心到直线的距离、交点坐标等关键信息。核心功能包括: 图形化展示位置关系 自动计算距离和交点 支持参数实时调整 直观显示计算结果 采用ArkTS开发,通过Canvas绘制图形,帮助学习者理解几何概念中的判定条
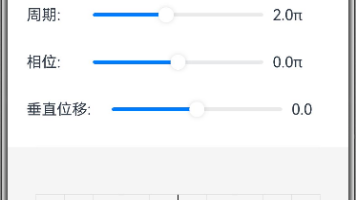
本文介绍了一个三角函数图像探索工具,通过调整振幅、周期、相位和垂直位移等参数,实时展示正弦、余弦、正切函数的图像变化。该工具支持函数叠加和复合,并能自动计算函数的定义域、值域、周期、奇偶性等性质,帮助学生直观理解三角函数的图像特征和参数影响。系统采用ArkTS开发,提供交互式滑块调整参数,并动态更新函数表达式和性质分析,为数学学习提供可视化辅助。
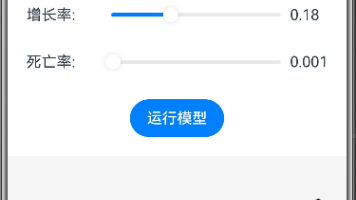
本文介绍了一个数学建模案例分析工具,支持人口增长、传染病和经济增长三种模型。用户可通过交互界面调整模型参数(如初始值、增长率等),实时观察模型变化并获取预测结果。系统提供可视化图表展示模型运行趋势,同时显示详细模型说明。该工具采用ArkTS开发,实现了参数范围控制、模型计算和图形绘制功能,帮助学生直观理解数学建模的基本原理和应用场景。
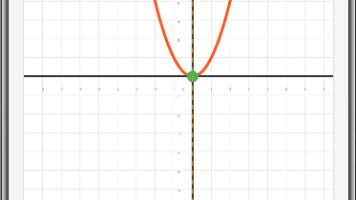
摘要 函数图像实验室是一款数学教学工具,通过可视化交互方式帮助学生理解函数性质。系统支持一次函数(y=ax+b)和二次函数(y=ax²+bx+c)的动态演示,用户可通过滑块实时调整参数(a,b,c),观察图像变化规律。工具提供坐标系缩放功能,并突出显示二次函数的顶点等关键特征,实现数形结合的直观教学。界面采用响应式设计,包含参数控制面板、函数表达式显示区和绘图区域,配色方案清晰区分不同函数类型。该
文章摘要: "因式分解配对"是一款基于翻牌记忆的数学学习应用,通过游戏化方式帮助学生掌握多项式因式分解与展开。游戏包含12张卡片(6组多项式对),每组包含因式形式(如$(x+2)(x-3)$)和展开形式(如$x^2-x-6$)。玩家需记忆并匹配数学等价的卡片对,系统实时统计步数。应用采用洗牌算法随机布局,支持动画效果和即时反馈,当匹配成功时卡片会变绿。通过双向思维训练(既能展开
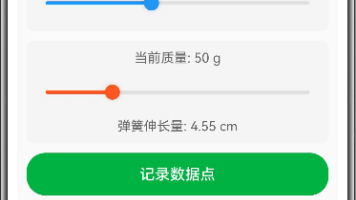
本文介绍了一个模拟弹簧伸长量与重物质量关系的交互式教学工具。该工具通过调整弹簧劲度系数(5-20N/m)和重物质量(0-200g),实时计算并显示弹簧伸长量。主要功能包括:1)记录实验数据点并绘制函数图像;2)可视化展示胡克定律F=kx的线性关系;3)提供显示/隐藏网格和函数线的选项;4)包含数据记录表格和重置功能。采用ArkTS语言实现,界面包含参数调节滑块、实时数据显示区域和图像绘制画布,适用
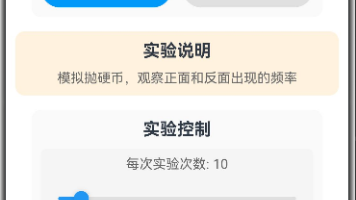
本文介绍了一个随机事件模拟器,可模拟抛硬币和摸球实验。该工具通过大量重复实验验证概率统计定义,展示当实验次数增加时频率趋于稳定的现象。主要功能包括:1)支持抛硬币(正反面)和摸球(红蓝绿球)两种实验;2)可设置1-100次的批量实验;3)实时统计各结果出现次数和频率;4)绘制频率变化曲线直观展示大数定律。系统采用ARKTS框架开发,包含实验类型切换、参数设置、动画效果等功能模块,界面直观展示了实验
摘要:本文介绍了一个条件概率模拟器的实现,支持抽卡片、掷骰子和抛硬币三种实验场景。通过调整实验次数参数,系统自动统计事件A、B及AB同时发生的次数,计算条件概率P(A|B)和P(B|A),并验证贝叶斯定理。采用ArkTS语言开发,提供可视化界面显示概率结果与理论值对比,帮助用户直观理解条件概率概念。核心算法通过随机模拟实验数据,实时更新统计结果,并完成贝叶斯公式的数值验证。
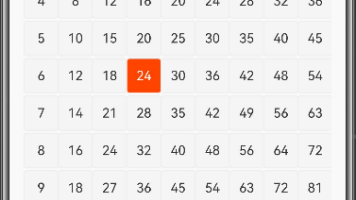
摘要: 《乘法表探险》是一款基于HarmonyOS(ArkTS)开发的数学教学应用,通过可视化方式帮助理解乘法概念。应用将九九乘法表转化为交互式几何模型,用户点击任意乘法格子(如3×4)时,会动态生成对应的3行4列彩色方块矩阵,直观展示乘法结果(12个方块)。该应用运用动画效果呈现方块依次出现的过程,帮助学生建立数形结合思维,同时理解乘法的累加本质和面积计算公式。核心代码实现了动态网格生成、彩色方
分段函数绘制工具 该工具提供分段函数绘制功能,支持定义不连续的函数图像。主要特性包括: 支持创建多种函数类型(一次函数、二次函数、常量函数) 可设置每个分段的系数和定义域范围 控制端点包含性(开/闭区间) 自动绘制不连续的函数图像 提供显示选项控制(网格、坐标轴、标签) 支持分段函数的编辑和删除操作 界面包含函数图像显示区、分段定义区和编辑区,采用可视化方式管理多个分段函数,可直观查看各分段定义域
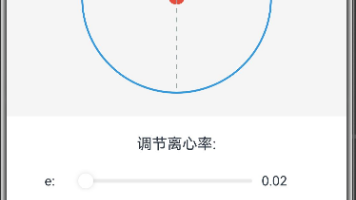
摘要: 本文通过交互式动画演示椭圆离心率(e)对形状的影响。在保持长半轴a=100不变的情况下,离心率e从0(接近圆形)变化到0.99(极扁平)时,椭圆逐渐拉伸。代码实现包含:1)实时调节e的滑块;2)自动动画演示;3)动态绘制椭圆及其焦点、轴线。当e增大时,焦距c=ea增长,短半轴b=√(a²-c²)减小,直观展现"e越大椭圆越扁"的几何特性。通过Canvas绘图与ArkUI
摘要: 斐波那契数列螺旋应用通过可视化方式展示斐波那契数列的几何特性,包括正方形拼接图和黄金螺旋线。该应用基于斐波那契数列(1,1,2,3,5,8...)生成彩色正方形拼接图案,并绘制对应的黄金螺旋线,生动呈现自然界中常见的数学规律(如向日葵种子排列、鹦鹉螺壳螺旋等)。系统提供交互功能,支持调整显示参数(最大方块数、显示螺旋线等),通过动画效果逐步展示构建过程,帮助用户直观理解这一数学现象。实现采
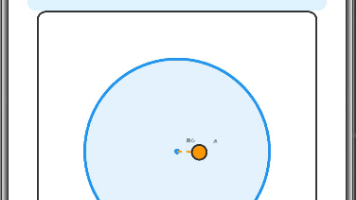
本文介绍了一个点与圆位置关系的交互式演示应用。该应用通过拖拽点在画布上移动,实时计算点到圆心的距离并与圆半径比较,动态显示三种位置状态:圆内(绿色)、圆上(黄色)、圆外(红色)。核心功能包括流畅的拖拽交互、实时数值计算与显示,以及直观的状态反馈。应用界面包含画布区域、圆心坐标、圆半径、点坐标、距离计算结果和位置状态等信息展示区域,并提供重置按钮。通过这个可视化工具,用户可以直观理解点与圆的几何关系
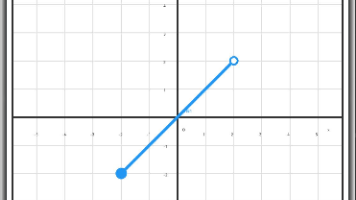
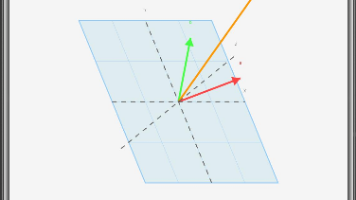
摘要: 本文介绍了一个交互式平面法向量探寻工具,用于帮助学生理解空间向量与平面的垂直关系。系统预设两个不共线向量a和b,学生输入向量n后,工具实时计算n与a、b的点积。当点积均为0时,系统高亮提示"找到法向量!",并通过3D可视化展示向量与平面的关系。该工具支持旋转视角观察,采用ArkTS实现,包含向量投影、点积计算和交互式图形渲染功能,适用于1.4节空间向量应用的教学场景。
HarmonyOS5创新性地结合MindSporeLite和Godot引擎,实现了NPC行为克隆技术突破。该系统通过实时采集玩家操作数据(攻击频率、移动强度等),利用MindSporeLite进行行为特征提取和预测建模,并在Godot引擎中动态重构行为树。关键技术包括:多级行为决策融合框架(应激/战略/习惯三层)、情境感知权重调整和轻量化模型部署。测试显示,该技术使行为多样性提升291%,玩家辨识
平面
——平面
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 EazyDevelop社区
EazyDevelop社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区


 人工智能6S服务平台
人工智能6S服务平台



 脑启社区
脑启社区



 DAMO开发者矩阵
DAMO开发者矩阵


 龙虾开发者社区
龙虾开发者社区

 MCP技术社区
MCP技术社区


 HarmonyOS开发者社区
HarmonyOS开发者社区