登录社区云,与社区用户共同成长
邀请您加入社区
Python的re模块是处理正则表达式的核心工具,用于字符串匹配、查找、替换等文本操作。文章介绍了re模块的基础使用步骤、核心函数(match、search、findall、sub等)以及Match对象的常用方法。重点讲解了正则表达式元字符的含义和使用技巧,包括匹配模式、分组、标志位等。同时提供了性能优化建议和实际应用示例(如邮箱验证),并提醒注意贪婪匹配、原始字符串等常见问题。该模块通过预编译模
Python的random模块是标准库中用于生成伪随机数的核心工具,支持多种随机数生成和序列操作。主要功能包括:1)生成随机浮点数(random.random)和整数(randint/randrange);2)序列随机选择(choice)、抽样(sample)和打乱顺序(shuffle);3)指定范围的均匀分布(uniform)和特殊分布随机数(gauss等);4)通过seed设置实现可重现结果。
本文主要对Kd-树相关算法进行学习,包括如何创建以及相关的空间查询方法编程实现等等,同时扩展一下scipy中的kdtree子包的最邻近查询,帮助大家扩展学习。
SciPy(Scientific Python)是基于NumPy的科学计算库,专门处理科学与工程计算。它提供了大量常用的数学函数、算法和工具,模块化组织。
Python学习路径分为三个阶段:入门阶段掌握基础语法与核心概念,包括变量、控制流、数据结构等;进阶阶段深入函数编程、面向对象、异常处理等核心技能;精通阶段则侧重高级特性与专业应用开发。每个阶段包含详细的知识点与示例代码,如文件操作、装饰器、正则表达式等,并强调实践中的注意事项,如内存管理、编码问题等。学习者可循序渐进掌握Python编程能力,从简单脚本到复杂系统开发。
C++17的结构化绑定是一项强大而实用的特性,它通过简化多返回值的接收和处理流程,极大地提升了代码的简洁性、可读性和安全性。它将开发者从繁琐的std::tie和显式的成员访问(如.first)中解放出来,使得代码意图更加清晰。无论是处理标准库容器(如std::map)、自定义聚合类型,还是函数的多返回值,结构化绑定都应该成为现代C++开发者的首选工具。通过结合引用限定符和范围for循环,它能应对各
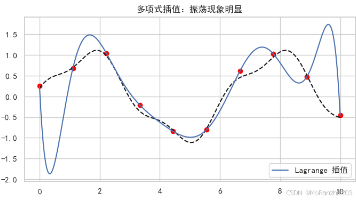
在科学计算与数据分析中,插值(Interpolation)是一类重要的工具,用来在已知数据点之间推测未知点的函数值。SciPy 提供了丰富的插值函数接口,可以轻松实现从一维到多维的插值运算。本文将结合数学公式、SciPy 函数与 Python 可视化案例,系统梳理常见插值方法。
《Python零基础入门:变量与数据类型详解》摘要:本文面向编程新手,系统讲解Python基础概念。变量被比作数据容器(如age=18),需遵循命名规则(蛇形命名法)。五大基础数据类型包括:整数/浮点数(数值运算)、字符串(文本处理)、布尔值(True/False)和None(空值)。通过type()函数可查验数据类型,支持类型转换(如int("18"))。重点提醒易错点:变量
本文针对 SciPy 和 NumPy 库在不同 Python 版本下的协同工作能力进行了系统测试。测试覆盖 Python 3.6 至 3.10 版本,结合多个 SciPy 和 NumPy 版本组合,评估其兼容性。结果显示,在多数现代 Python 版本中,最新稳定版组合表现良好,但部分旧版本存在兼容性问题。报告提供详细测试数据和实用建议,帮助用户优化库版本选择。
版本兼容本质是工程约束与创新需求的动态平衡。掌握底层内存模型、接口演化规律及依赖解析算法,可构建健壮的科学计算工作流。随着PEP 665标准推进,未来版本管理将更加智能化。注:本文所有代码示例均通过Python 3.7-3.10、NumPy 1.19-1.22、SciPy 1.6-1.8验证。
Python版本升级为科学计算带来性能提升,但需严格遵循库版本依赖关系。建议通过虚拟环境隔离测试,采用渐进式迁移策略。持续关注[PyPI]官方文档更新,可最大限度降低适配成本。
$ \text{NumPy 1.16} \xrightarrow{\text{缺失 NPY_ARRAY_WRITEABLE}} \text{SciPy 稀疏矩阵操作崩溃} $$在科学计算领域,SciPy、Python 和 NumPy 的版本协调如同精密齿轮的啮合。本文将深入解析三者间的版本依赖关系,助您构建稳定的计算环境。注:$x$ 表示 NumPy 版本号,$[a,b)$ 表示半开区间。:升级至
$ \begin{array}{c|c} \text{数据类型} & \text{适用检验} \ \hline \text{两组连续变量} & \text{独立样本t检验} \ \text{多组分类数据} & \text{卡方检验} \ \text{配对样本} & \text{配对t检验} \end{array} $$实战建议:将检验结果转化为业务指标,如"新策略预计每月提升转化率2.3%,增加营
此代码完整展示了地理空间数据处理的核心流程,输出结果包含三个分析视图:全球宏观视角、区域聚焦视角和空间影响范围分析。
TVM(Tensor Virtual Machine)是一个开源的深度学习编译器框架,其核心目标是将深度学习模型高效编译为多种硬件后端的可执行代码。总结:TVM 通过解耦计算定义与硬件调度,结合机器学习搜索最优配置,实现了编译优化脚本的自动化生成,成为深度学习部署的关键基础设施。针对特定硬件(如 GPU/CPU)插入优化指令,例如循环分块$tile$、向量化$vectorize$等。定义硬件无关的
Transformer主导NLP领域,CNN仍是视觉任务基石,RNN在边缘计算中保留价值。深度学习模型架构的选择直接影响任务性能与部署效率。,分析其数学原理、适用场景及局限性。
关键点: 指令必须精确指定任务目标,包括输入和输出要求。例如,避免使用“解释一下”等模糊词汇,而应改为“简要总结以下文本的核心论点”。提升效果: 这能降低模型自由发挥的风险,输出更贴合用户意图。数据显示,清晰定义任务可将质量提升率提高30%以上。
作为爬虫新手,学 requests 参数这种偏实操的知识点,纯看视频就像 “盲人摸象”—— 参数用法零散、代码抄录易错、实操门槛高、学完易忘;而视频解析工具就像 “爬虫学习导航”,把零散知识点结构化归纳、把复杂实操简化为 “一键运行”、把被动记忆变成主动自测。
摘要 文章分析了Python科学计算环境中常见的scipy与scikit-learn版本兼容性问题,重点讨论了二进制兼容性错误的解决方案。当出现"_qhull"相关错误时,建议优先重建环境而非修复。作者详细比较了pip和conda的依赖管理机制,指出conda在科学计算领域更可靠,因其能全面检查C/C++二进制库兼容性等底层问题。文章提供了最佳实践:先用conda安装核心科学包
本文详细介绍了使用Python的scipy.stats库进行正态分布检验的三种方法(KS检验、Shapiro-Wilk检验和Q-Q图)以及68-95-99.7法则的验证。通过实战案例和代码示例,帮助读者掌握数据正态性检验的核心技术,提升统计分析和机器学习模型的准确性。
本文深入讲解Python中scipy.optimize.curve_fit在非线性拟合中的实战应用,涵盖指数衰减、对数增长和S型曲线三种常见模型。通过代码示例演示参数优化技巧、拟合质量评估及协方差矩阵解读,帮助读者掌握非线性拟合的核心方法,提升数据分析能力。
SciPy是Python中强大的科学计算库,广泛应用于信号处理、优化、积分和线性代数等领域。本文介绍了SciPy的安装方法(推荐使用pip或conda),并通过实例演示了其基本功能,如获取物理常量、数值积分、优化求解和解线性方程组。此外,还展示了高级用法,如信号滤波和插值技术,并举例说明其在传感器数据分析与物流路径优化中的实际应用。SciPy为科学计算提供了高效工具,帮助开发者专注于业务逻辑而非底
本文提供了一份详细的Python教程,教你如何使用scipy库中的curve_fit函数进行多元函数拟合。通过非线性最小二乘法,你可以轻松处理复杂的数据拟合问题,包括一元和多元高斯函数拟合。教程包含完整代码示例和可视化技巧,适合初学者快速上手。
Scipy是一个基于Python的开源科学计算库,它提供了大量的数学函数、算法以及工具,用于解决各种科学和技术问题。Scipy是Python科学计算生态中的核心库之一,它建立在NumPy的基础上,扩展了矩阵运算、信号处理、图像处理、优化、统计、特殊函数等多个领域的功能。Scipy在科学计算领域有着广泛的应用,它不仅是数据科学、机器学习、物理模拟、工程分析等领域的重要工具,也是科学研究和工程实践中不
plt.plot(df["天数"], df["隔天进步1%"], label="隔天进步1%", color="green")plt.plot(df["天数"], df["每天退步1%"], label="每天退步1%", color="blue")plt.plot(df["天数"], df["每天进步1%"], label="每天进步1%", color="red")plt.savefig("天
标准 scipy 内置优化模块为 scipy.optimize,scipy-optimstruct 并非 PyPI 官方独立分包,是行业内对「Scipy 结构化优化工具集」的统称。
本文详细介绍了Python中scipy.optimize.curve_fit在多元函数拟合中的应用,从二维曲面到三维数据建模的实战技巧。通过高斯曲面拟合案例,讲解参数调优、边界约束、分阶段拟合等关键方法,并展示三维可视化技巧,帮助读者掌握复杂数据建模的核心技术。
函数导数难以计算或不存在的情况寻找非线性函数的局部最小值维度适中的问题这种算法被广泛应用于机器学习、计算机视觉、信号处理等领域,特别是当目标函数计算成本高昂时尤为有用。边界约束支持:SciPy版本添加了对变量边界的支持,通过bounds参数实现。它使用np.clip确保所有单纯形顶点都在指定边界内,这是标准Nelder-Mead算法的扩展。自适应参数策略:通过adaptive参数启用,基于Gao和
XSP18是一款集成USB Power Delivery(PD2.0/3.0)PPS快充协议、QC2.0/3.0快充协议、华为快充协议和三星AFC等多种快充协议,的USB Type-C受电端(sink)取电芯片, 产品使用 XSP18 芯片可无需再配充电器, 功率最大支持 100W。充电器内部有协议芯片,当外部设备连接时,设备会和充电器进行协议匹配,匹配成功之后,充电器才会输出相应的电压给设备供电
SciPy是一个强大的Python库,提供了丰富的科学计算和数据分析工具。它建立在NumPy库的基础上,为科学家和工程师提供了许多高效的数值算法和统计函数。在本文中,我们将探讨如何使用Python和SciPy库进行统计分析和建模,包括描述性统计、假设检验、回归分析以及更高级的统计建模技术。
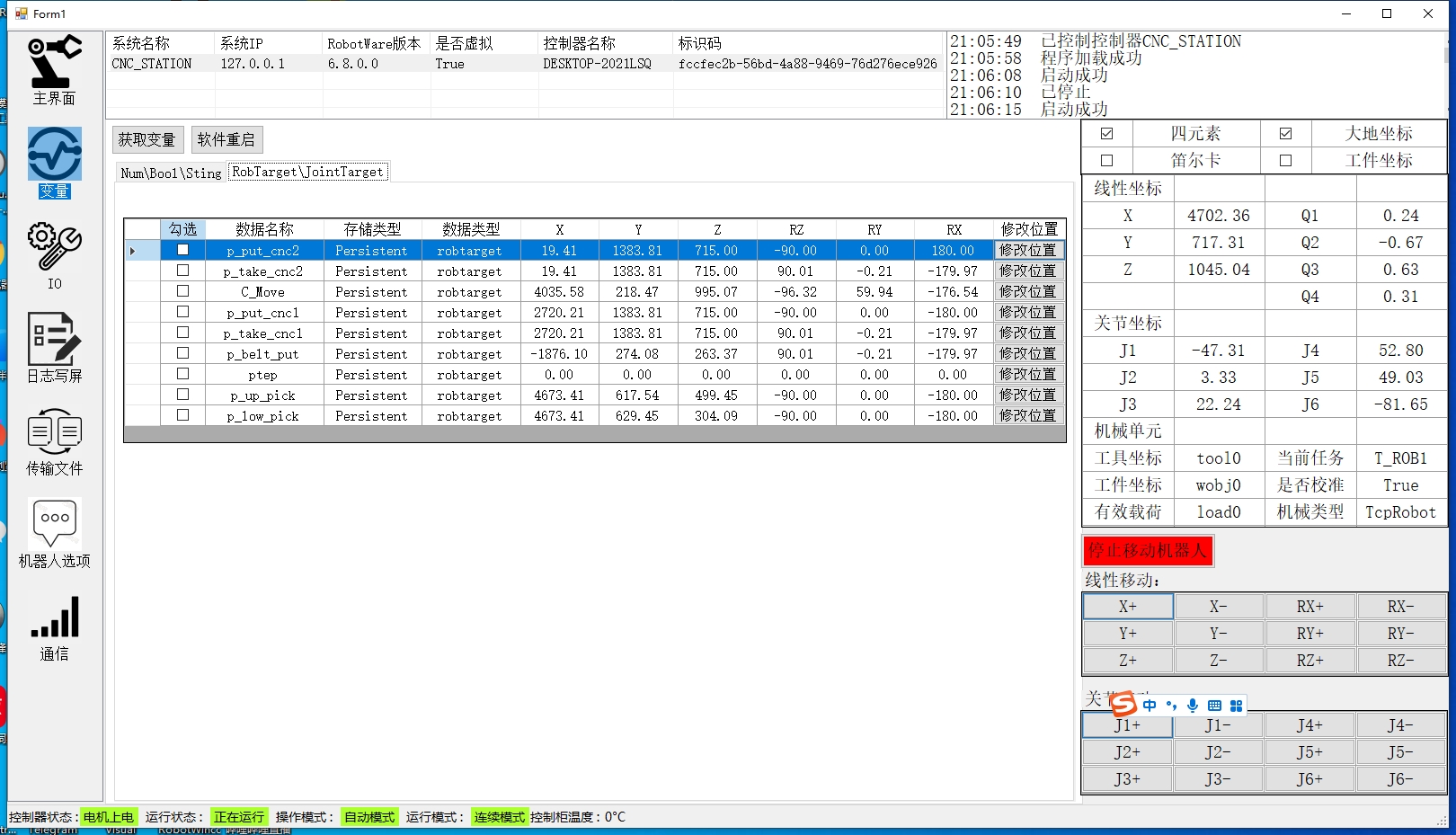
开发中遇到的坑:PC SDK的文档真是一言难尽,多试试API返回值。实时监控超过20个变量时建议分组处理,别把控制器搞崩了。最后提醒,生产环境一定要加异常恢复机制,机器人一动起来可没Ctrl+Z的机会。StartWatching的参数别设太小,机器人控制器扛不住高频请求。先装个NuGet包ABB.Robotics.Controllers.PC,这是PC SDK的命根子。这段代码扫局域网里的ABB控
scipy
——scipy
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区













 DAMO开发者矩阵
DAMO开发者矩阵