




- @qq_29462849
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
把这几条路线摆到一起,规律很明显:越便宜越好规模化,但离真实机器人执行越远;越接近真机执行,价值越高,成本越难降。仿真最便宜,却要真实数据校准;Egocentric 和 Human-Centric 规模最大,但要解决人机迁移;真机遥操精度最高,却撑不起未来的数据量;触觉信息最丰富,可规模又不够。所以未来的数据体系不会属于某一条路,而是一座金字塔:底层最宽、最便宜——仿真和 Egocentric /

Google DeepMind 发布的《Gemini Robotics 1.5.pdf》系统呈现了通用机器人领域的突破性进展,该系列包含与两大核心模型。通过 “思考 - 动作融合”“跨形态运动迁移”“嵌入式推理升级” 三大创新,结合 “协调器 + 动作模型” 的智能体架构,实现了机器人 “感知 - 思考 - 行动” 的闭环,为复杂多步骤物理任务解决提供了全新路径。以下结合报告关键图表,从技术架构、

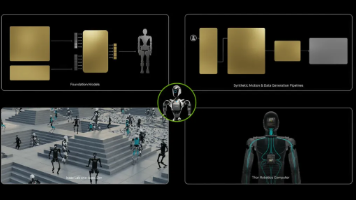
回头看这一年,NVIDIA 在具身上的路线异常清晰:用「三台计算机」把训练、仿真、运行三段全占住,用 GR00T 定大脑的参照系,用 Cosmos、EgoScale、DreamZero 同时占住数据的正门和研究的前沿,用 Isaac Sim / Lab / Newton 做仿真、再用 Isaac Lab-Arena 握住评测的尺子,用 Jetson Thor 卡住算力入口,最后用一个个联盟和一张张
去年 8 月,我们写过一篇聊「第一视角人类视频」的文章。那会儿这还是个刚冒头的方向,几篇论文、几个 demo。但后面这段时间,趋势已经完全不一样了。NVIDIA、伯克利、马里兰联手的,把 20,854 小时带动作标注的第一视角人类视频喂进一个 VLA,据论文披露,跑出了一条人类数据规模和验证 loss 之间的对数线性 scaling law——而且这个 loss 能预测真机表现。半年之间,这个方向

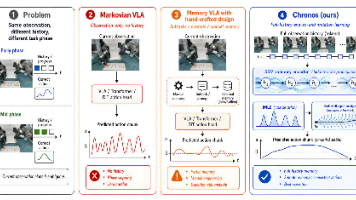
机器人真正走向现实世界,需要的不只是更大的模型,而是更像“行动者”的策略。行动者不会每一秒都从零开始看世界;它会记得刚才发生过什么,知道自己走到了哪一步,也能根据隐藏信息继续完成后续动作。Chronos 的名字来自时间。它要解决的,正是机器人操作中最容易被忽视、却最难绕开的东西:时间、历史与记忆。从“只看眼前”到“记住过去”,从“直接生成动作”到“二阶动力学精修”,Chronos 为长时序机器人模
他是英伟达 GEAR 实验室的一号位,GR00T 项目的联合负责人,推特签名写着"论文清单拉完,20 篇。Vesta 算一个(通用具身推理模型),NitroGen 勉强算半个(其实是游戏 agent),再加一篇视觉表征预训练。当然,这不是说大脑不重要。20 篇论文还不能给整个行业下这种判断。这是他们的判断,不是所有人标准答案。但一号位用 20 篇论文的选择替自己投的票,我们觉得值得认真看一看。

机器人是否真的需要一亿小时数据,今天还很难给出确定答案。但这句话背后可以折射出一个提醒:如果具身智能希望复制大模型时代的能力跃迁,就必须面对数据规模、数据质量和数据组织方式这三个问题。过去几年,行业已经证明了真机数据的价值,也证明了遥操作路线的有效性。但这条路径成本高、扩展慢、强依赖本体,很难单独支撑通用机器人模型走向下一阶段。human data 路线提供了另一种可能。从人类在真实世界中的动作痕

台上是一套体系化的战略——整机 + 智能闭环、三重跃迁、百万小时数据、开放生态;台下是一种「结硬寨、务实干」的冷静——别太把评测当真,做好自己的事、坚持真机,做好成本计算、商业上第一阶段不追第一。这两层合起来,也回答了我们开篇那个问题:站在头部的视角往前看,具身行业正在往哪走?星海图给出的答案很明确——它正从「拼产品、拼单点」走向「拼生态」,从「卖本体」走向「卖生产力」;而它自己押的,恰恰是这条路

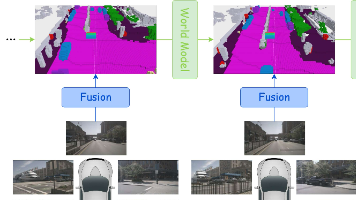
世界模型(World Models)是具身智能体连接感知、预测与决策的核心。这篇综述首次通过一个创新的三轴分类法,为这个复杂而充满活力的领域建立了一个清晰、全面的认知框架。该框架不仅系统性地梳理了现有工作的脉络,也为未来的研究提供了明确的方向。
增注:虽然当时看这篇文章的时候感觉很不错,但是还是写在前面,想要了解关于机器学习度量的几个尺度,建议大家直接看周志华老师的西瓜书的第2章:模型评估与选择,写的是真的很好!!以下第一部分内容转载自:机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)是怎么一回事摘要:...