




- @qq_33419476
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因为大家都是在一个真实的分布中得到的样本,对于分布的拟合都是近似的。想要以最快的方式下山,就沿着梯度的反方向走。下面的这张动图演示,乍看就像就像是在复杂地形中作战的沙盘推演,其实揭示的是随机梯度下降(SGD)算法的本质。同样是走一步路,坡度大的地方上升的高度就高,坡度小的地方上升的高度就小,对比现实生活中的盘山公路!了解之后,总的来说,随机梯度下降一般来说效率高,收敛到的路线曲折,但一般得到的解是
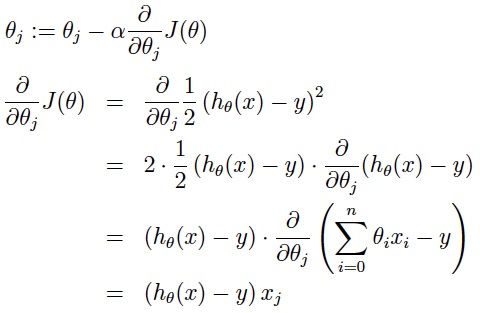
problem:会对未见过的操作懵逼,然后break down。

actor: 是policy network,通过生成动作概率分布,用来控制agent运动,类似“运动员”。critic: 是value network,用来给动作进行打分,类似“裁判”。

iterationsiterations(迭代):每一次迭代都是一次权重更新,每一次权重更新需要batch_size个数据进行Forward运算得到损失函数,再BP算法更新参数。1个iteration等于使用batchsize个样本训练一次bath_sizeepochs/ˈiː.pɒk/epochs被定义为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。
1. 背景Problem:最新的机器学习或深度学习模型的有效性受限于机器向人类和用户解释它想法和行为的能力。However, the effectiveness of these systems will be limited by the machine’s inability to explain its thoughts and actions to human users.Aim: 让用户
1. 概念漂移(concept drift) 背景:概念漂移指的是数据流中的潜在数据分布随时间发生不可预测的变化,使原有的分类器分类不准确或决策系统无法正确决策,常见于推荐系统、金融领域、决策等 Concept drift refers to unforeseeable changes in the underlying data distribution of data stre...
一、转载博客转载在:https://www.douban.com/note/640290683/注0:《deep learning》的chapter 5有一部分讲maximum likelihood,那里讲地更清楚,建议直接去参考那里的内容。注1:今天走在路上,突然想明白了似然度是怎么回事,它就是用来度量模型和数据之间的相似度,所以叫它似然度。注2:原文链接:https://cod...
基于语义指纹的重名辨识方法通过提取文献著者的特征字段数据,将其映射为一段64位或128位的二进制数字串,用以表征每条数据记录中的独特个体,将文本相似度比较转化为语义指纹相似度比较。是指当数据库查询或关联某个发明人的专利时,往往会将所有同名发明人的专利返回或将某个发明人与其他发明人的专利相连接,使得基于专利发明人的科研技术研究结果出现偏差。基于机器学习的方法较好地克服了规则方法的方法,在不同的专利发
卷积神经网络(Convolutional Neural Network,简化为ConvNet或CNN)是一种前馈神经网络,其中信息从输入到卷积运算符单向流动到输出[93]。reference:H. Cecotti and A. Graser, “Convolutional neural networks for p300 detection with application to brain-co
problem:传统的深度神经网络输入信息没有顺序。比如,NLP领域中,我们输入单词经常使用embedding,将单词映射为词向量,然后输入到神经网络。但这种输入方式有一些问题,“我 爱 你”和“你 爱 我”在传统的神经网络中不能很好的识别。虽然,有人提出n-gram信息加入到输入层,比如fasttext,这在一定程度上解决了短句子单词间的顺序问题,但是这种方法也有一些弊端,就是我们无法捕获长句子
