




- @a772304419
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MVTec AD:工业异常检测领域的经典基准数据集,包含 15 个品类(纹理类和物体类),每个品类均提供像素级标注掩码,广泛用于评估异常检测和定位算法的性能。MVTec AD 2:全新升级版 MVTec 数据集,涵盖 8 类工业异常检测场景。:面向逻辑约束异常检测的数据集,包含结构性和逻辑性两类异常。Real-IAD:真实工业多视角异常检测数据集,用于多功能工业场景的基准测试。:覆盖从极其明显到极
场景:分析一个人做深蹲的视频。YOLO会告诉你:“视频的每一帧里都有一个人。”(框出这个人)OpenPose会告诉你:“这个人的膝盖在这个位置,髋关节在那个位置,并且它们是这样连接的。”(画出骨骼图)OpenCap会告诉你:“在下蹲过程中,该受试者的膝关节屈曲角度达到了105度,膝关节承受的剪切力为X牛·米,这个数值在安全范围内。”(给出可量化的医疗/运动分析报告)关系总结YOLO 和 OpenP
Doris 选型 (AVX2) 与 AI 功能协作紧密:向量索引构建是高强度 CPU 计算,使用 AVX2 版本可显著提升索引构建速度和查询性能。尝试 AI 函数:在测试环境先用等初步分析。试用混合搜索:整合全文、向量检索和结构化查询。生态集成MCP Server:可通过与 LangChain/Dify 集成,用自然语言查询数据。RAG 系统:作为私有知识库和数据存储底座,开发智能问答/知识库应用
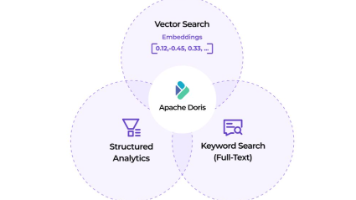
在 AI 技术快速演进的时代,数据基础设施正成为AI应用的核心支撑。Apache Doris 作为一款高性能、实时分析型数据库,深度融合了文本搜索、向量搜索、AI 函数和MCP智能交互能力,构建从数据存储、检索到分析的完整 AI 数据栈。Doris 提供高性能、低成本、易集成的一体化解决方案, 广泛支持混合检索与分析、面向Agent的数据分析、RAG 应用构建、语义检索应用,以及大规模AI系统和应
MVTec AD:工业异常检测领域的经典基准数据集,包含 15 个品类(纹理类和物体类),每个品类均提供像素级标注掩码,广泛用于评估异常检测和定位算法的性能。MVTec AD 2:全新升级版 MVTec 数据集,涵盖 8 类工业异常检测场景。:面向逻辑约束异常检测的数据集,包含结构性和逻辑性两类异常。Real-IAD:真实工业多视角异常检测数据集,用于多功能工业场景的基准测试。:覆盖从极其明显到极
Doris 选型 (AVX2) 与 AI 功能协作紧密:向量索引构建是高强度 CPU 计算,使用 AVX2 版本可显著提升索引构建速度和查询性能。尝试 AI 函数:在测试环境先用等初步分析。试用混合搜索:整合全文、向量检索和结构化查询。生态集成MCP Server:可通过与 LangChain/Dify 集成,用自然语言查询数据。RAG 系统:作为私有知识库和数据存储底座,开发智能问答/知识库应用
Doris 选型 (AVX2) 与 AI 功能协作紧密:向量索引构建是高强度 CPU 计算,使用 AVX2 版本可显著提升索引构建速度和查询性能。尝试 AI 函数:在测试环境先用等初步分析。试用混合搜索:整合全文、向量检索和结构化查询。生态集成MCP Server:可通过与 LangChain/Dify 集成,用自然语言查询数据。RAG 系统:作为私有知识库和数据存储底座,开发智能问答/知识库应用
请将 IMC 模式设置为Haswell或更高版本。设置 IMC 策略时,集群内所有主机(物理服务器)的 CPU 必须都支持你选择的那个基准。例如,如果你选了,但集群里有一台老旧的服务器,那么这台老服务器将无法被管理或无法迁移虚拟机。修改 IMC 策略通常要求集群内的虚拟机处于关机状态才能生效(或者是新启动的虚拟机才生效,具体视 FusionCompute 版本而定,建议在维护窗口操作)。
采用模板+数据=HTML实现页面的静态化。也就是服务端的页面静态化技术。JSP/Freemarker/Thymeleaf是常见的模板引擎。引依赖okhttp与HttpClient一样的作用,实现远程访问:实体类@Data等注解:freemarker默认会从templates目录中获取模板,所以不要乱改:freemarker...
spring boot配置文件详解application.properties是spring-boot的核心配置文件,这个配置文件基本可以取代我们ssm或者ssh里面的所有的xml配置文件。当我们启动springboot工程做的第一件事就是加载application.properties属性配置文件。application.properties虽然有时候是...