登录社区云,与社区用户共同成长
邀请您加入社区
普通的Web开发,常用的模式就是用户登录之后,登录状态信息保存在Session中,用户一些常用的热数据保存在文件缓存中,用户上传的附件信息保存在Web服务器的某个目录上。这种方式对于一般的Web应用,使用很方便,完全能够胜任。但是对于高并发的企业级网站,就应付不了了。需要采用Web集群实现负载均衡。
1. 列出使用的机器普通PC,要求:cpu: 750M-1Gmem: >128Mdisk: >10G不需要太昂贵的机器。机器名:finewine01finewine02finewine03将finewine01设为主节点,其它的机器为从节点。2. 下载和生成从这里checkout,我选择trunkhttp://svn.apache.org/repos/asf/lucene/
Centos_7.2 下 Kafka_2.13 分布式消息系统的集群模式配置图文详解一、前言在上一篇博客中完成了 《 kafka 分布式消息系统的单例模式配置 》 的工作,但是在实际生产环境中,二、环境介绍Linux 版本: Centos-7JDK 版本: JDK_1.8_Linux64bitzookeeper 版本: zookeeper-3.5.3-bet
华为昇腾950超节点获WAIC2026最高奖,标志着国产AI算力进入超节点时代。该产品采用1024卡标准配置,通过自研灵衢2.0全光互联协议实现3μs超低时延和256TB全局统一内存,使集群算力利用率达82%-85%,较传统架构提升一倍。全液冷设计使PUE低至1.08,单集群硬件成本约1.5亿元,在同等有效算力下TCO优于国际竞品。当前国产超节点面临机房配套、生态适配等短期挑战,但预计到2028年
Redis 集群的实现原理是什么?
本文深入探讨Redis Key过期事件在分布式锁中的隐藏陷阱,并解析Redisson的看门狗机制如何提升锁的可靠性。通过Redisson实现细节和集群环境下的红锁算法,为开发者提供分布式锁的最佳实践方案,确保高并发场景下的数据一致性。
Nacos作为微服务架构中的核心组件,提供了服务注册与发现功能,解决了服务动态变化时的IP和端口感知问题。文章详细介绍了Nacos的优势、架构原理及核心功能,包括服务注册、心跳检测、健康检查等。通过实战演示了如何整合Nacos到SpringCloud项目中,并讲解了集群搭建、负载均衡配置等高级应用。相比Zookeeper和Eureka,Nacos具有更强大的功能和更高的可用性,是微服务注册中心的未
本文深入剖析了Nacos 1.4.X版本注册中心的实现原理。从客户端视角,详细分析了服务注册流程、心跳机制实现,包括自动注册触发、HTTP请求发送等关键环节。服务端部分重点解读了注册表的三层Map结构设计、异步注册机制、健康检查策略,以及基于Distro协议的数据同步过程。文章还探讨了Nacos采用写时复制思想解决并发读写冲突、双层Map结构支持多环境隔离等设计亮点,并对Nacos的性能表现进行了
MySQL Router是MySQL官方提供的一个轻量级中间件,主要用于在MySQL InnoDB集群或组复制环境中实现客户端连接的路由、负载均衡和高可用性。它的核心功能是将应用程序的数据库连接请求智能地分发到后端可用的MySQL服务器节点。当主节点发生故障时,MySQL Router能够自动检测并将新的连接重定向到新的主节点,从而实现故障转移,对应用程序透明。透明路由:应用程序像连接单个MySQ
序号主机名称IP地址角色配置1kafka014C4G60G2kafka024C4G60G3kafka034C4G60G版本信息序号信息备注1系统版本CentOS 7.62JDK版本8u2013zookeeper版本3.7.04kafka版本2.8.0。
基于源码深度解析,Redis Cluster 集群原理:数据分片与故障转移
【Kubernetes入门指南】本文系统介绍了容器编排平台Kubernetes的核心概念与集群搭建方法: 核心概念解析 Pod是最小部署单元,包含1个或多个共享网络/存储的容器 通过Deployment/StatefulSet等控制器管理Pod生命周期 Service提供稳定的访问入口,解决Pod IP变动问题 集群架构 控制平面(API Server等组件)负责集群管理 工作节点(kubelet
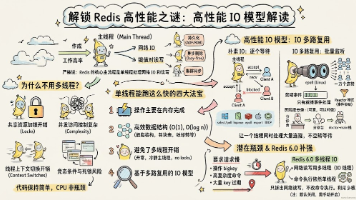
Redis作为单线程服务却能支持高并发的核心在于其高效的内存操作、优化的数据结构和基于多路复用的IO模型。虽然严格来说Redis并非完全单线程(后台任务如持久化使用独立线程),但其主请求处理路径保持单线程设计,避免了多线程锁竞争和上下文切换的开销。通过非阻塞Socket和epoll等多路复用技术,Redis单线程可以同时监听和处理大量连接请求,配合事件驱动机制实现高吞吐。6.0版本引入的多线程仅用
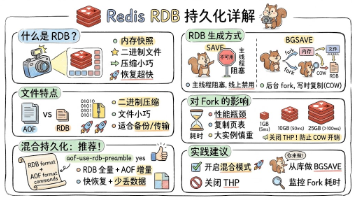
Redis持久化机制RDB与AOF对比及混合模式实践建议 摘要: Redis提供RDB和AOF两种持久化方式,RDB通过二进制快照实现快速恢复,但存在数据丢失风险;AOF记录写命令保证数据安全,但恢复速度较慢。RDB支持SAVE(阻塞式)和BGSAVE(后台fork子进程)两种生成方式,后者利用写时复制机制减少内存开销。配置save参数可控制自动触发快照的条件,需权衡性能与数据完整性。Redis
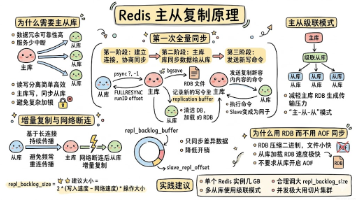
Redis主从库模式通过读写分离保障高可用性,主库负责写操作并同步到从库。首次同步分为三阶段:建立连接、全量RDB传输和增量命令同步。采用"主-从-从"级联模式可减轻主库压力,网络断连后通过环形缓冲区实现增量复制。建议控制单实例数据量、合理设置缓冲区大小,并发高时可采用切片集群。RDB因其体积小、加载快的特点优于AOF作为同步方案。
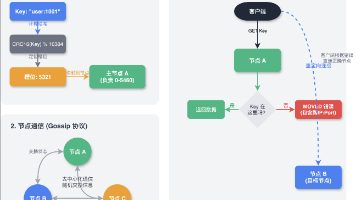
Redis Cluster哈希槽机制精要 Redis Cluster采用16384个哈希槽实现数据分片,通过CRC16算法计算键的槽位(CRC16(key) % 16384)。关键设计要点: 槽数选择:16384槽(而非65536)平衡了数据分布均匀性和Gossip通信效率,确保2KB的槽位图适合CPU缓存。 键映射优化: 支持HashTag({user1000}.profile),仅对花括号内内
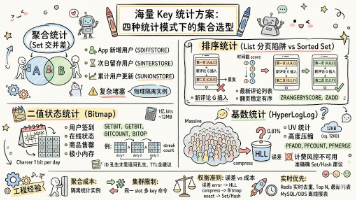
本文总结了Redis在处理海量Key统计时的四种典型模式及对应数据结构选型方案: 聚合统计(交并差运算)推荐使用Set类型,适用于用户留存分析等场景,但需注意大数据量聚合操作可能阻塞主线程。 排序统计推荐Sorted Set,通过score稳定排序特性解决List分页时的"元素漂移"问题,特别适合评论列表、排行榜等场景。 二值状态统计首选Bitmap,以极低内存开销(1bit/状态)处理签到、在线
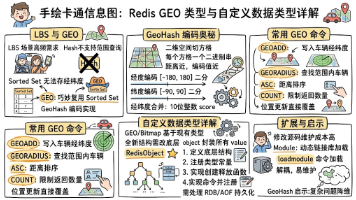
本文介绍了Redis GEO类型的实现原理及自定义数据类型的方法。GEO类型通过GeoHash编码将二维经纬度映射为一维整数,利用Sorted Set实现高效范围查询,解决了LBS场景下的位置存储与检索问题。文章详细解析了GeoHash的编码算法(二分区间与交叉编码)及Redis GEO命令的使用方式。进一步,文章阐述了Redis自定义数据类型的机制,包括RedisObject结构、新增类型的四个
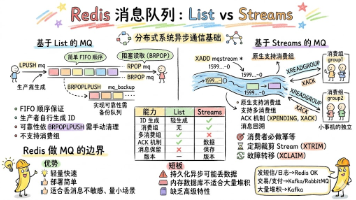
本文对比了Redis中List和Streams两种消息队列实现方案。List通过LPUSH/RPOP保证消息顺序,支持阻塞读取(BRPOP),但缺乏消费组支持和消息确认机制,需手动维护备份队列保证可靠性。Streams作为Redis 5.0引入的专有消息队列类型,支持消费组负载均衡、自动生成消息ID、ACK确认机制,能更好满足消息保序、重复处理和可靠性三大核心需求。作者指出Redis适合轻量级消息
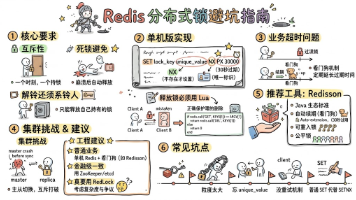
Redis分布式锁实现要点与常见陷阱 分布式锁必须满足互斥性、死锁避免和持有者校验三个核心要求。Redis通过SET NX PX命令实现基本锁机制,配合Lua脚本确保安全释放。关键注意事项包括:设置合理的TTL并配合看门狗续期机制、释放锁时校验持有者身份、避免过粗或过细的锁粒度。在集群环境下可考虑RedLock算法,但其可靠性存在争议。实践建议优先使用成熟库如Redisson,避免重复造轮子;强一
摘要 本文深入解析Kafka Controller中各类ZooKeeper Listener的实现原理,包括BrokerChangeListener、TopicChangeListener等核心监听器。这些监听器通过ZooKeeper的Watcher机制感知集群变化(如Broker上下线、Topic增删、ISR变更等),并驱动PartitionStateMachine和ReplicaStateMa
是 Kubernetes 集群的默认调度器,负责将新创建的或尚未调度的 Pod 分配到合适的节点上运行。核心职责通过监测(Watch)机制发现集群中未被调度的 Pod为每个 Pod 选择最优节点将调度结果写入 API Server(绑定操作)通俗理解:kube-scheduler 就像一个“房屋中介”——有新 Pod 要入住,中介根据房客的需求(资源、标签、亲和性)和房屋的现状(节点资源、标签、污
在开篇的引子中,我们提出了资源管理的三个层次。层次问题K8s 组件状态监控层资源用了多少?✅ 第十期已讲扩缩层资源不够怎么办?HPA✅ 第十期已讲约束层如何防止超用?✅ 本期已讲一句话回顾本期:我们通过 ResourceQuota 实现了“管住总量”,通过 LimitRange 实现了“定好规矩”——这就是集群资源管理的“安全网”和“标准尺”。
AI视界——从资讯看技术》专栏 · 第七期当基础设施的核心组件突然变更许可证,运维的架构决策能力,比以往任何时候都更重要。
一致性哈希算法就是因为新分片逮住一个就分片切割才造成了数据分布部均匀。哈希槽分区算法是在一致性哈希算法思想的基础上,把范围变成具体的一个个槽,以此来解决扩容后数据不均匀分布的问题。数据分片算法决定如何把数据映射到不同的分片上。可以有16384个分片吗?为什么是16384个槽位?
本文深入解析Redis Cluster 6.2预防脑裂的五大关键配置参数,包括cluster-node-timeout、cluster-replica-validity-factor等,并通过实战演示网络分区测试环境搭建与故障模拟。文章详细探讨了不同参数组合对数据一致性和集群可用性的影响,为生产环境配置提供决策树指导,帮助开发者有效规避分布式系统中的脑裂风险。
每个节点会负责一定数量的槽,如图所示。这种方式的突出优点是简单性,常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为512或1024张表,保证可支撑未来一段时间的数据量,再根据负载情况将表迁移到其他数据库中。使用特定的数据,如Redis的键或用户ID,再根据节点数量N使用公式:hash(key)%N计算出哈希值,用来决定数据映射到哪一个节点上。由于Redis
只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),因为每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复FAILOVER_AUTH_ACK消息作为投票,之后相同配置纪元内其他从节点的选举消息将忽略。当从节点收集到N/2+1个持有槽的主节点投票时,从节点可以执行替换主节点操作,例如集群内有5个持有槽的主节点,主节点b故障后还
这里我们故意忽略了槽和数据在节点之间迁移的细节,目的是想让读者重点关注在上层槽和节点分配上来,理解集群的水平伸缩的上层原理:集群伸缩=槽和数据在节点之间的移动,下面将介绍集群扩容和收缩的细节。当下线主节点具有从节点时需要把该从节点指向到其他主节点,因此对于主从节点都下线的情况,建议先下线从节点再下线主节点,防止不必要的全量复制。扩容之初我们把6385、6386节点加入到集群,节点6385迁移了部分
本文详细介绍了如何使用TongWeb应用服务器和TongHttpServer(THS)负载均衡器构建高可用Java应用集群。通过实战指南,包括架构设计、环境准备、集群配置和性能优化,帮助开发者实现故障自动转移和水平扩展能力,提升系统稳定性与处理能力。
本文详细介绍了如何利用TongWeb应用服务器与TongHttpServer(THS)构建高可用Java应用集群,解决单点故障问题。通过架构设计、负载均衡选型、生产环境部署及调优实战,为企业提供了一套完整的集群部署方案,确保系统的高可用性和稳定性。
智能体(Agent)是具备目标理解、工具调用与自主决策能力的AI执行单元;集群(Cluster)则通过任务分片、角色化部署与协调层编排,实现多智能体协同并行处理。其技术价值在于打破传统单体AI的串行瓶颈,消除上下文污染与人工反复干预,显著提升知识工作流的吞吐量与稳定性。典型应用场景包括批量内容生成、合同智能审查、竞品信息抽取及跨源数据融合等高频、多步骤、强依赖的办公任务。本文以Kimi K2.5智
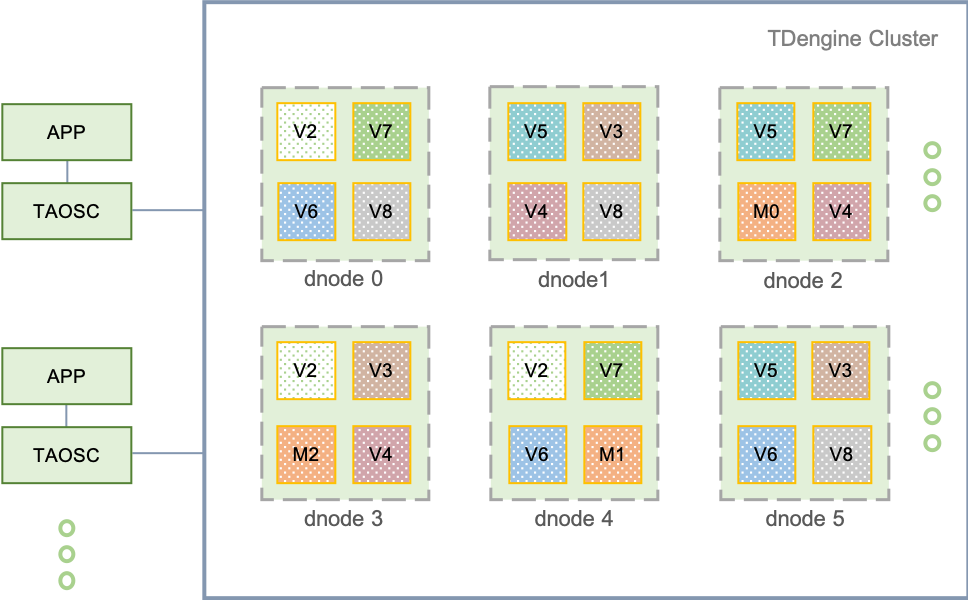
TDengine 的设计是基于单个硬件、软件系统不可靠,基于任何单台计算机都无法提供足够计算能力和存储能力处理海量数据的假设进行设计的。因此 TDengine 从研发的第一天起,就按照分布式高可靠架构进行设计,是支持水平扩展的,这样任何单台或多台服务器发生硬件故障或软件错误都不影响系统的可用性和可靠性。同时,通过节点虚拟化并辅以自动化负载均衡技术,TDengine 能最高效率地利用异构集群中的计算
Kubernetes集群不是简单的软件安装,而是分布式基础设施的系统性工程。其本质是基于容器运行时、etcd一致性存储、CNI网络模型和API驱动控制面的协同系统。理解kubeadm初始化背后的约束条件——如内核cgroup v2支持、etcd存储隔离、Pod/Service CIDR规划、证书生命周期管理——是保障集群可复现、可验证、可演进的关键技术前提。这些设计决策直接影响高可用能力、升级平滑
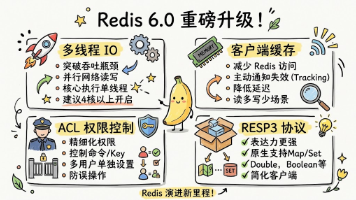
Redis 6.0 是一次相当重要的版本升级。从 1.0 一路发展到 5.x,单线程几乎是 Redis 的"招牌"。6.0 第一次在网络 IO 层引入了多线程,配合客户端缓存、ACL 权限、RESP3 协议等新特性,让 Redis 在性能、安全和易用性上都迈出了一大步。理解这些新特性背后的设计动机,能帮我们判断什么时候该升级、怎么用好它们。
Kafka与大数据生态深度集成全景解析 本文深入剖析Kafka作为现代数据架构核心"数据总线"的定位,系统梳理其与主流大数据组件的集成方案: Kafka与Hadoop/Hive集成 提供Kafka Connect HDFS Sink、Flink写入和自定义Consumer三种数据归档路径 详细对比各方案在开发量、灵活性和运维复杂度上的差异 Kafka与ClickHouse的实时分析组合 解读Cli
集群
——集群
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区



 人工智能6S服务平台
人工智能6S服务平台


 AI编程社区
AI编程社区

















 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵

 脑启社区
脑启社区
 AI硬件创业社区
AI硬件创业社区
 EazyDevelop社区
EazyDevelop社区

