




- @qq_36693723
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
图像分类是计算机视觉领域中的一个基本问题,它的目标是将图像分为不同的类别。在过去的几十年中,许多传统的机器学习方法已被开发用于图像分类,但随着深度学习技术的发展,深度神经网络已成为最先进的图像分类方法。

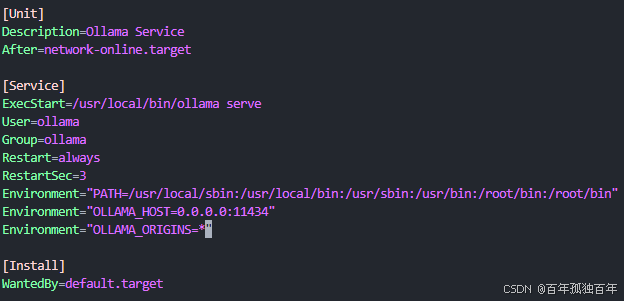
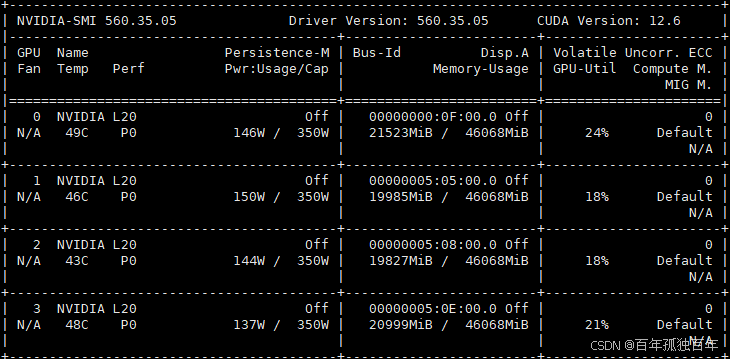
默认的ollama调用的各种大模型,如deepseek 70b模型,每个模型实例只绑定一张 GPU,如果是多卡,其它卡会一直闲置,造成一定浪费。本文档介绍如何通过 systemd 配置文件为 Ollama 服务添加 GPU 和调度相关的环境变量,从而实现多 GPU 的高效利用与负载均衡。
本文介绍了如何在 Windows 系统的 CMD 中使用 Docker 安装 AnythingLLM,并搭建自己的知识库问答大模型

由于ollama默认调用模型,模型实例会运行在一张卡上,如果有几张显卡,模型只会永远跑在第一张卡上,除非显存超出,然后才会将模型跑在第二张卡,这造成了资源很大的浪费。网上通过修改ollama.service的配置。修改之后可以负载均衡,显存平均分配在集群中的每张卡上,但是我不太了解这种方式是否会提升模型吞吐量?和默认的调用单卡实例有啥区别呢?
Domain Generalization (领域泛化)是指在训练模型时,模型能够学习到一般化的特征,而不是仅仅适应于训练数据所在的特定领域。例如,一个人脸识别模型在训练时只使用了来自一个特定国家的人脸图像,但是在测试时需要处理来自其他国家的人脸图像。如果该模型具有很好的领域泛化能力,那么它应该能够对来自其他国家的人脸图像进行准确的识别。

领域自适应(Domain Adaptation)是指通过学习源领域和目标领域之间的差异,来实现将源领域的模型迁移到目标领域的能力。在实际应用中,由于数据的获取和标注成本较高,我们通常会面临数据集不完整、不平衡、标注不准确等问题,这些问题会影响模型的泛化能力和性能。领域自适应可以帮助我们解决这些问题,提升模型的泛化能力和性能。

FLOPs(floating point operations)是指浮点运算次数,通常用来评估一个计算机算法或者模型的计算复杂度。在机器学习中,FLOPs通常用来衡量神经网络的计算复杂度,因为神经网络的计算主要由矩阵乘法和卷积操作组成,而这些操作都可以转化为浮点运算次数的形式进行计算。
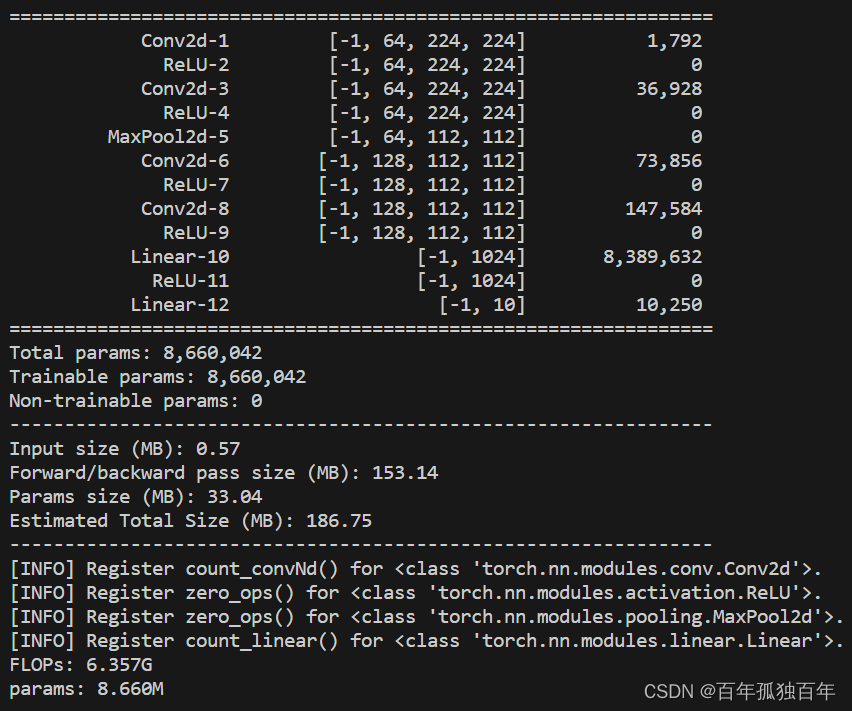
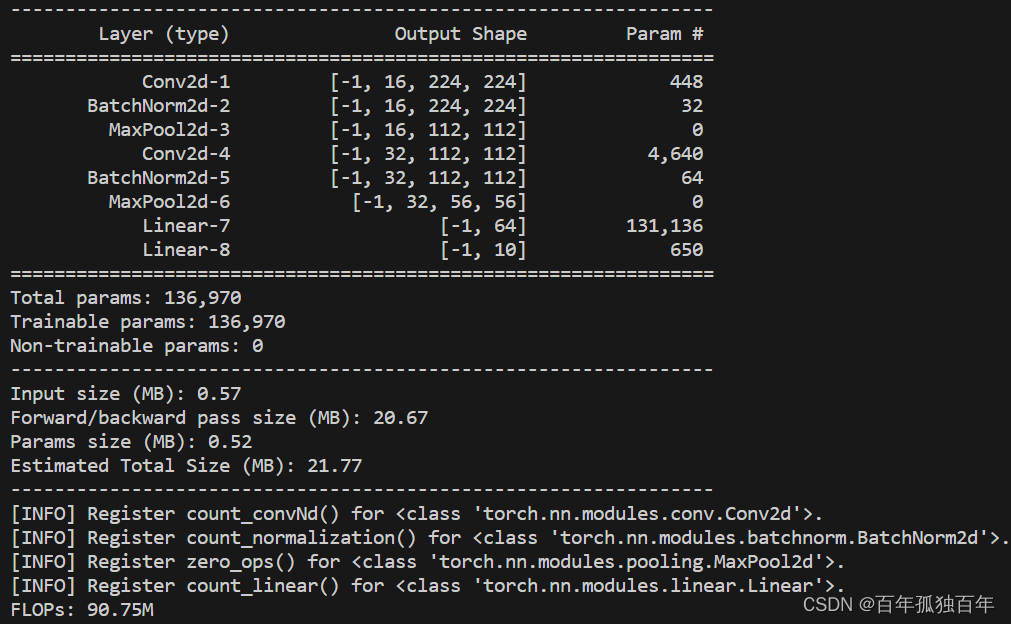
在深度学习中,模型的参数数量是一个非常重要的指标,通常会影响模型的大小、训练速度和准确度等多个方面。在本教程中,我们将介绍如何计算深度学习模型的参数数量。本教程将以PyTorch为例,展示如何计算一个包含卷积、池化、归一化和全连接等多种层的卷积神经网络的参数数量。具体来说,我们将首先介绍一个具有全连接层的神经网络的参数计算方法,然后扩展到包含卷积、池化、归一化和全连接等多种层的卷积神经网络。
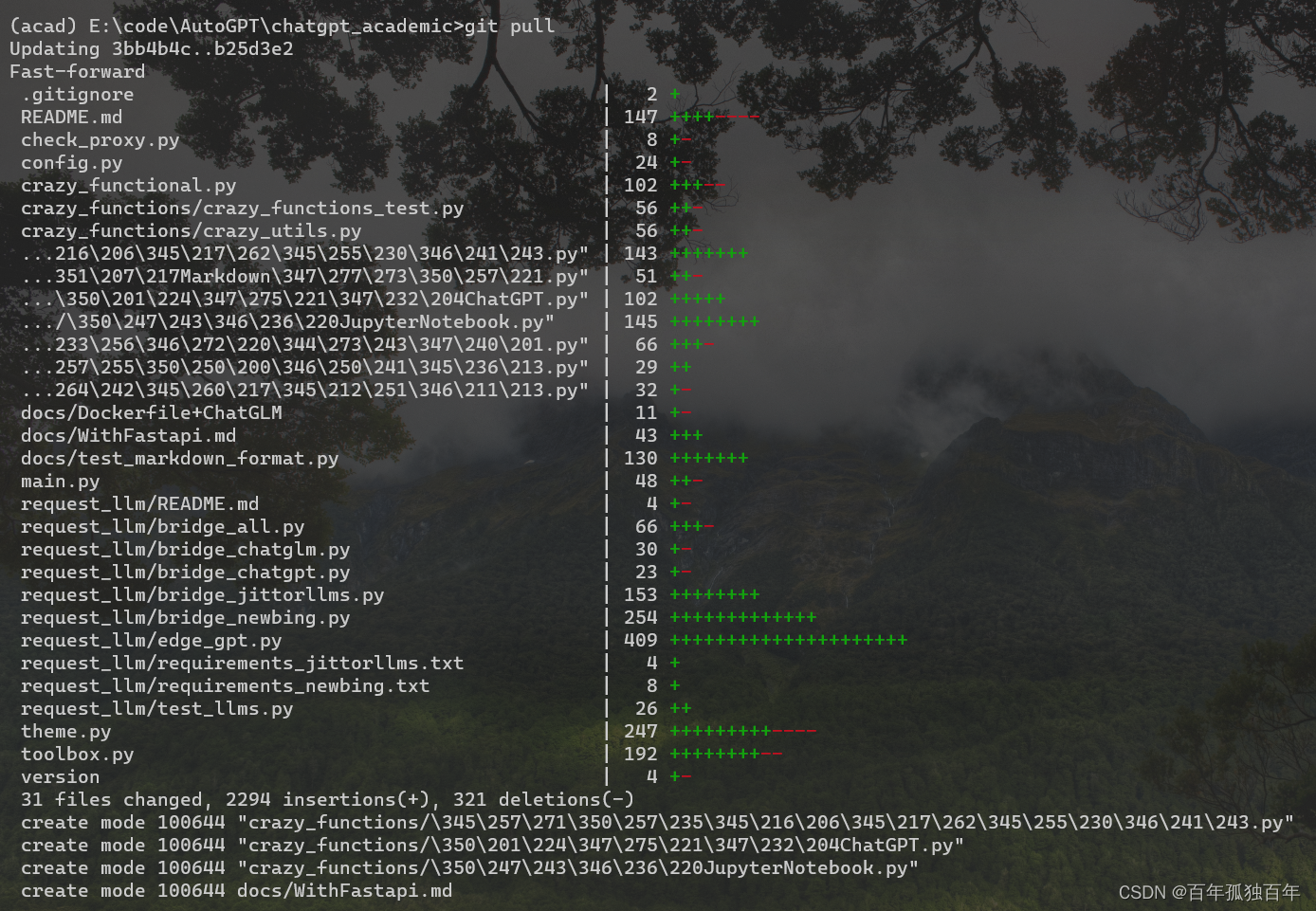
使用git更新别人的远程代码,并与本地的合并,且不修改自己之前的配置。
在使用 Docker 部署应用时,通常需要从 Docker Hub 或其他镜像仓库拉取镜像。但有时候,我们可能需要在没有互联网的环境中部署镜像,或者希望直接分享某个镜像给同事、朋友,而不必让他们重新下载。因为很多人使用docker下载文件非常慢,因此我在这里分享一下我docker当前下载的anythingllm和open-webui压缩包。首先分享镜像获取方式,提供两种方式:一个是切换国内镜像,一
