




- @qq_31136513
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
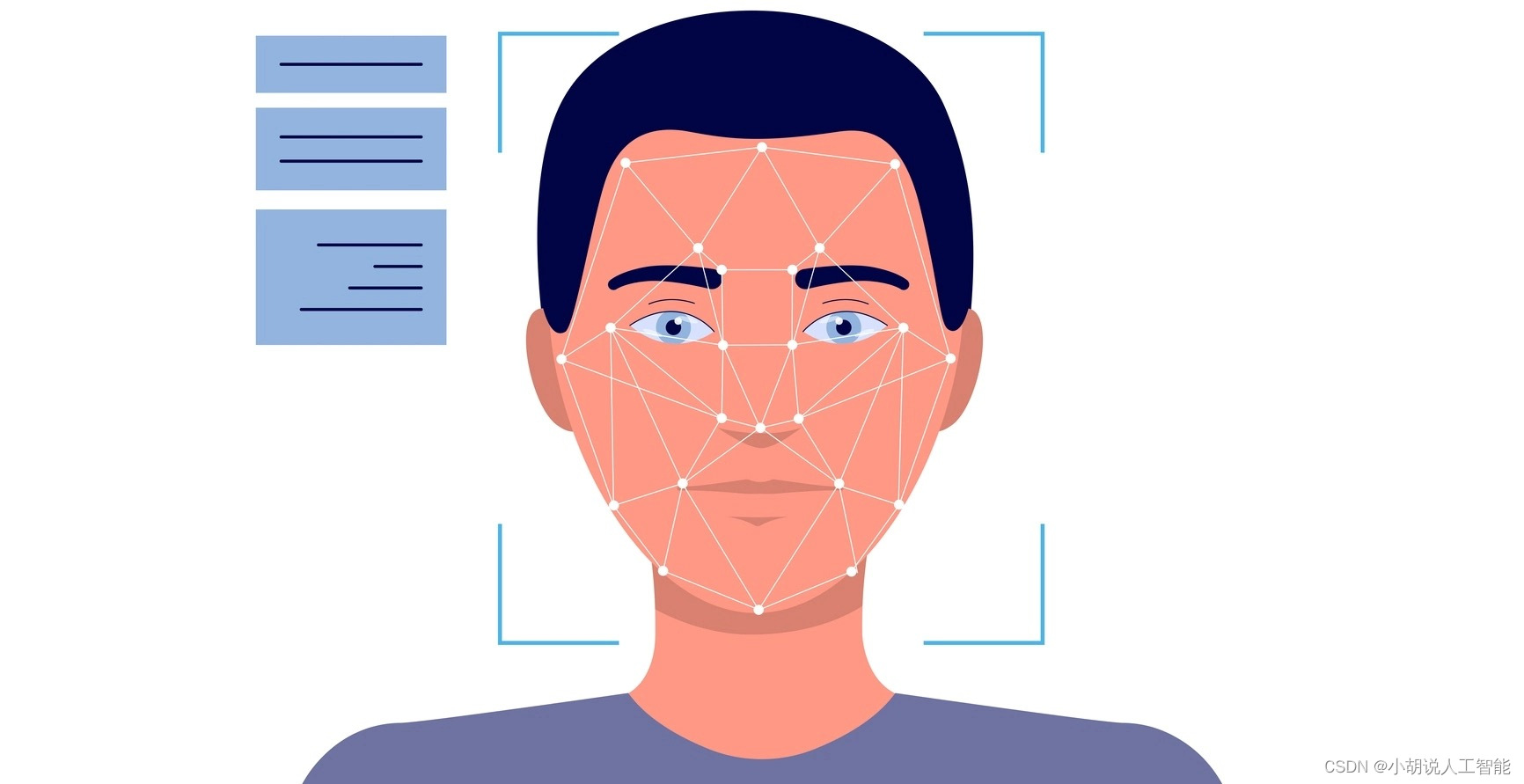
本项目采用了百度AI的训练模型,利用图像识别接口返回结果,旨在实现人脸在库中的判断,以及相关的人脸注册、删除和登录等业务场景。这个项目的应用潜力非常广泛,可以用于人脸识别门禁系统、人脸支付认证、人脸考勤等多个领域,提升安全性和便利性。
如果你想使用现在最火的ChatGPT来训练属于你的专属ChatGPT模型,那你千万不能错过这篇文章。迁移学习是机器学习领域中的一种重要方法,它通过利用先前的学习经验来提高当前任务的性能。本文通过3个经典的模型:InceptionV3-RestNet50-VGG16作为示例,为大家从0开始搭建了医疗影像行业迁移学习网络,并获取到了较好的准确度与结果一致性。而掌握好迁移学习的基础知识和应用,你就能通过
博主一直没有公开多少人工智能项目代码,但不少粉丝和朋友都很好奇真实人工智能项目到底是怎样的?我思前想后,打算针对几块我做过的人工智能项目给大家分享下,不过由于公司这两年发展比较快,项目方向有点多,不知道小伙伴们具体感兴趣哪块呢?欢迎大家关注我,在评论区回复具体目录项,如1.1,我会按照受欢迎程度来优先选择项目进行详细分析。...........................

用户根据其喜好选择主音调式和即兴参数,然后输入歌曲信息,如BPM(每分钟节拍数)、弦级数和重复次数,从而生成独特的音乐。这种方法实现了上下文相关的即兴演奏,让用户能够在创作音乐时融入个人风格和情感。

本项目采用 CBIR(Content-based image retrieval)步骤,基于 OpenCV 的图像搜索引擎,实现构图空间特征评价指标,提高匹配精度。 CBIR(Content-based image retrieval)技术,是目前主流的图像搜索方法之一,CBIR 技术基于图像内容的相似性来检索相似的图像,相比于传统的图像搜索方法,CBIR 技术具有更高的准确性和可靠性。同时博主还

本项目基于从网络获取的多种银行卡数据集,采用OpenCV库的函数进行图像处理,并通过神经网络进行模型训练。最终实现对常规银行卡号的智能识别和输出。

本项目基于Keras框架,引入CNN进行模型训练,采用Dropout梯度下降算法,按比例丢弃部分神经元,同时利用IOT及微信小程序实现自动化远程监测果实成熟度以及移动端实时监测的功能,为果农提供采摘指导,有利于节约劳动力,提高生产效率,提升经济效益。

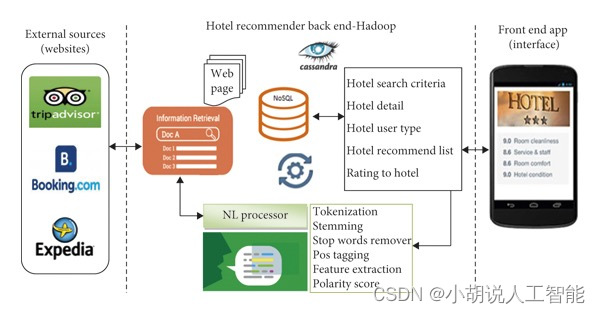
本项目是以向量机(SVM) 作为技术支持,使用酒店评论集作为数据集,训练出针对酒店评论情感的分析模型,使用word2vec产生词向量,实现服务器端提供数据、客户端查询数据的打分推荐系统。本系统可以帮助用户更好地了解酒店的口碑和评价,从而做出更明智的决策。
本项目基于Kaggle公开数据集,进行心脏病和慢性肾病的特征筛选和提取,选择随机森林机器学习模型进行训练,预判是否有疾病、针对相应的症状或需求给出药物推荐,实现具有实用性的智能医疗助手。这种智能医疗助手有望提高医疗决策的准确性,为患者提供更好的医疗体验,并对医疗资源的合理分配起到积极作用。

本项目基于网络爬虫技术爬取新闻,进行中文分词和特征提取,形成相似的新闻集,通过K-means算法进行聚集,最终集热点推荐、热词呈现及个性化分析等操作于一体,实现新闻推荐功能。
