




- @i_am_love_CrCr
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
若依,企业微信,验证码,短信,阿里,机器人

听说过删库跑路被抓的,今天就碰到升级服务器(Alibaba Cloud Linux ----> Ubuntu)原因是taos3.2不支持Alibaba Cloud Linux系统!为了保险起见把现在这个数据库里的数据都备份一份,为了不耽误同事们继续开发所以需要将需要升级的数据库在另一个服义务器中再跑一份出来!有navicat帮忙数据迁移很方便!但是犯错就在图方便上了!因为迁移的这两个数据库中有几个
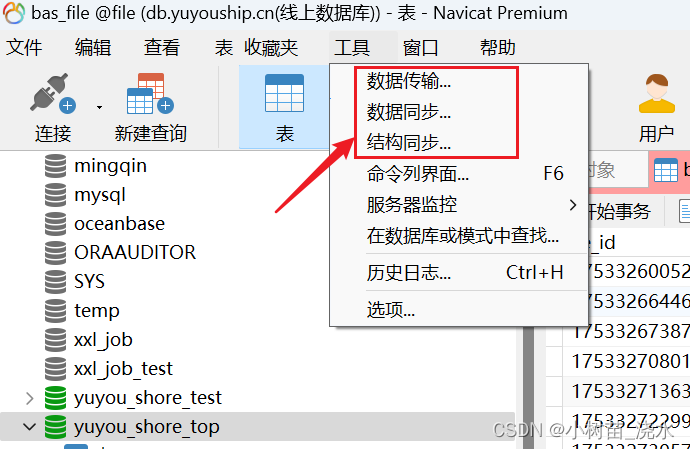
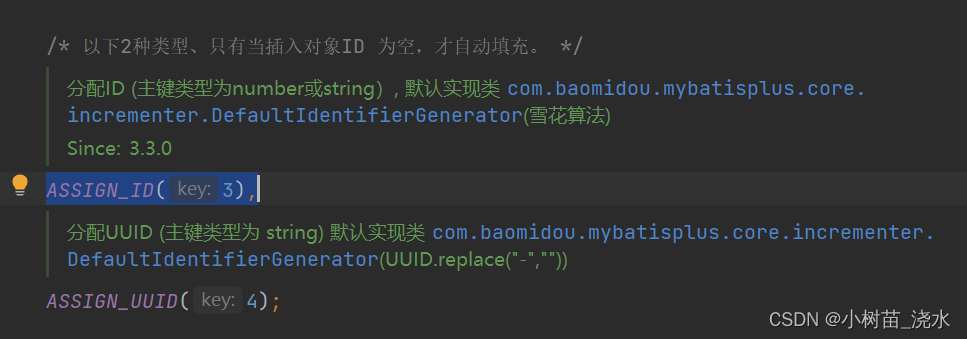
他是雪花算法,是根据地域时间等一些因素生成一个全球绝对唯一的id类型为number,同时在存入数据库时也会把数据库的结构改变,就是咱们之前提到的AUTO_INCREMENT = 85其中的85会变成一个19位的数字!在建表时定义了主键自增初始值也设置为一个二位常数,但是经过mybatis-plus的主键自增注解后会生成一个长度为19位的主键id!如果想解决可以参考这位博主的。不过咱们刚建的标其实还
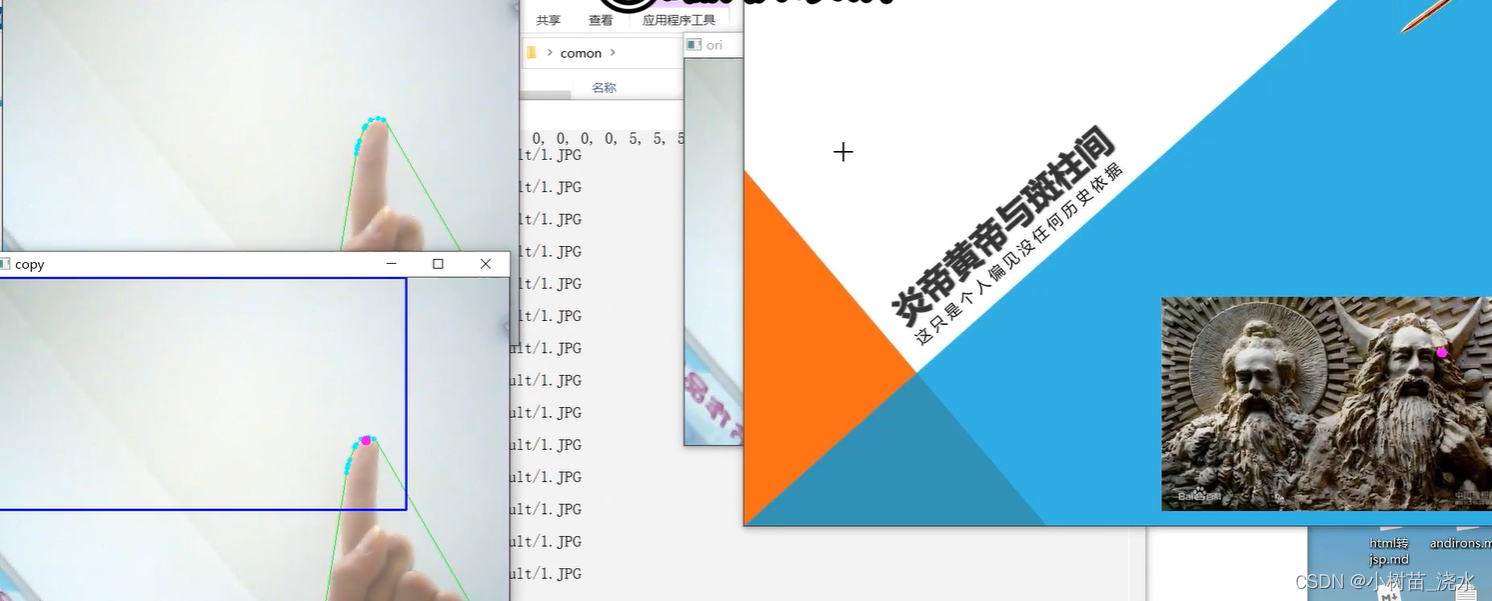
根据处理咱们可以获取得到五个数据,咱们需要利用其中的三个数据 (开始点, 结束点, 远点)通过反余弦定理求出手指岔开角度,进而判断伸出手指的个数。为了使系统稳定运行这里家里arry进行缓存50个前50帧图像处理结果然后综合判断此时此刻的识别结果。视频也是图片构成的,只是在不同帧展示不同的图片而已。这里根据自己电脑的性能选择取图片的频率。这里利用到了 凹凸图处理(腐蚀,另外一个名词想不起来了!最终是
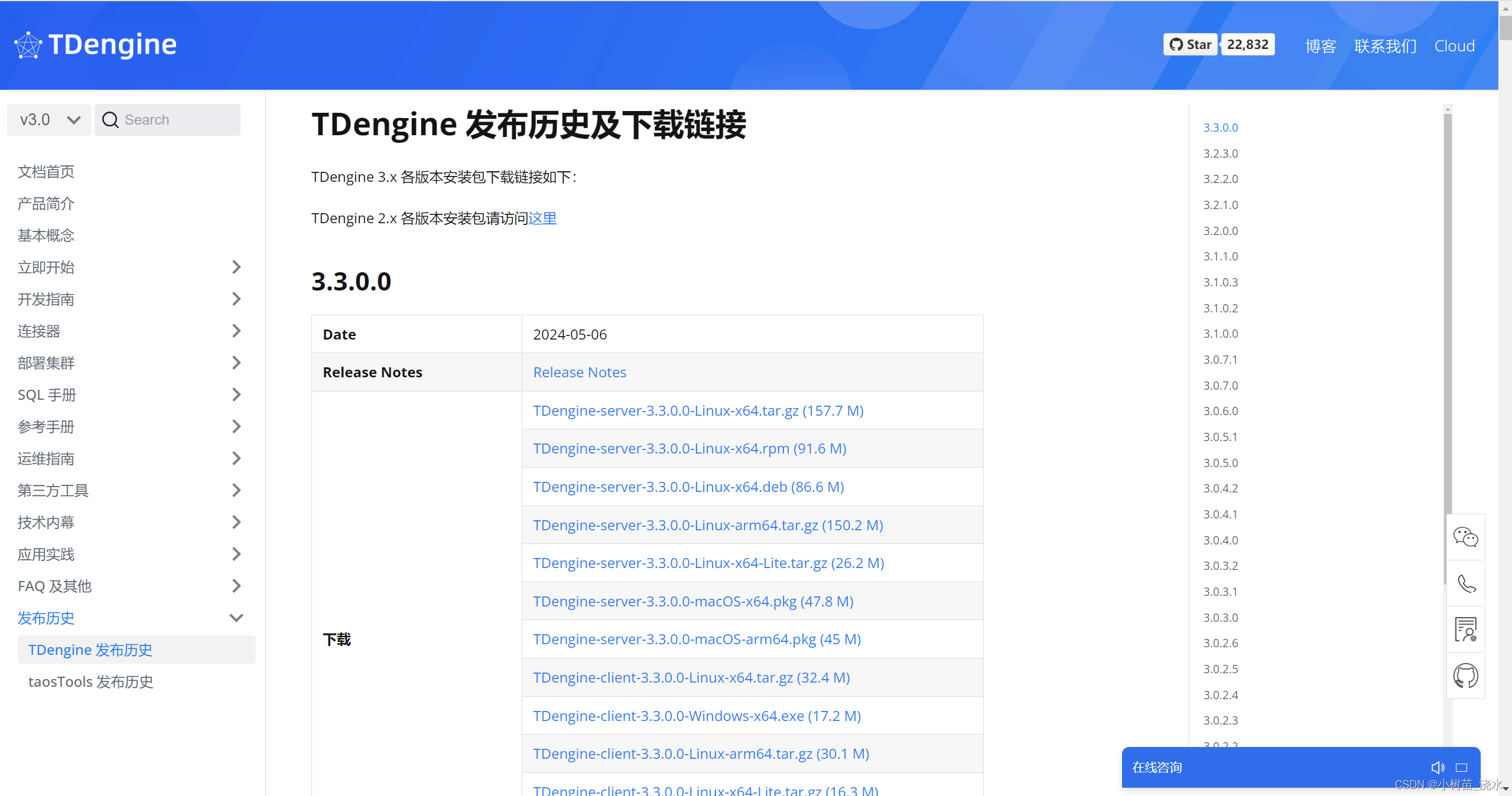
涛思数据库服务器安装分为两种情况一。新服务器直接安装(非常好)二。旧服务器删除后删除干净再安装(麻烦得很)
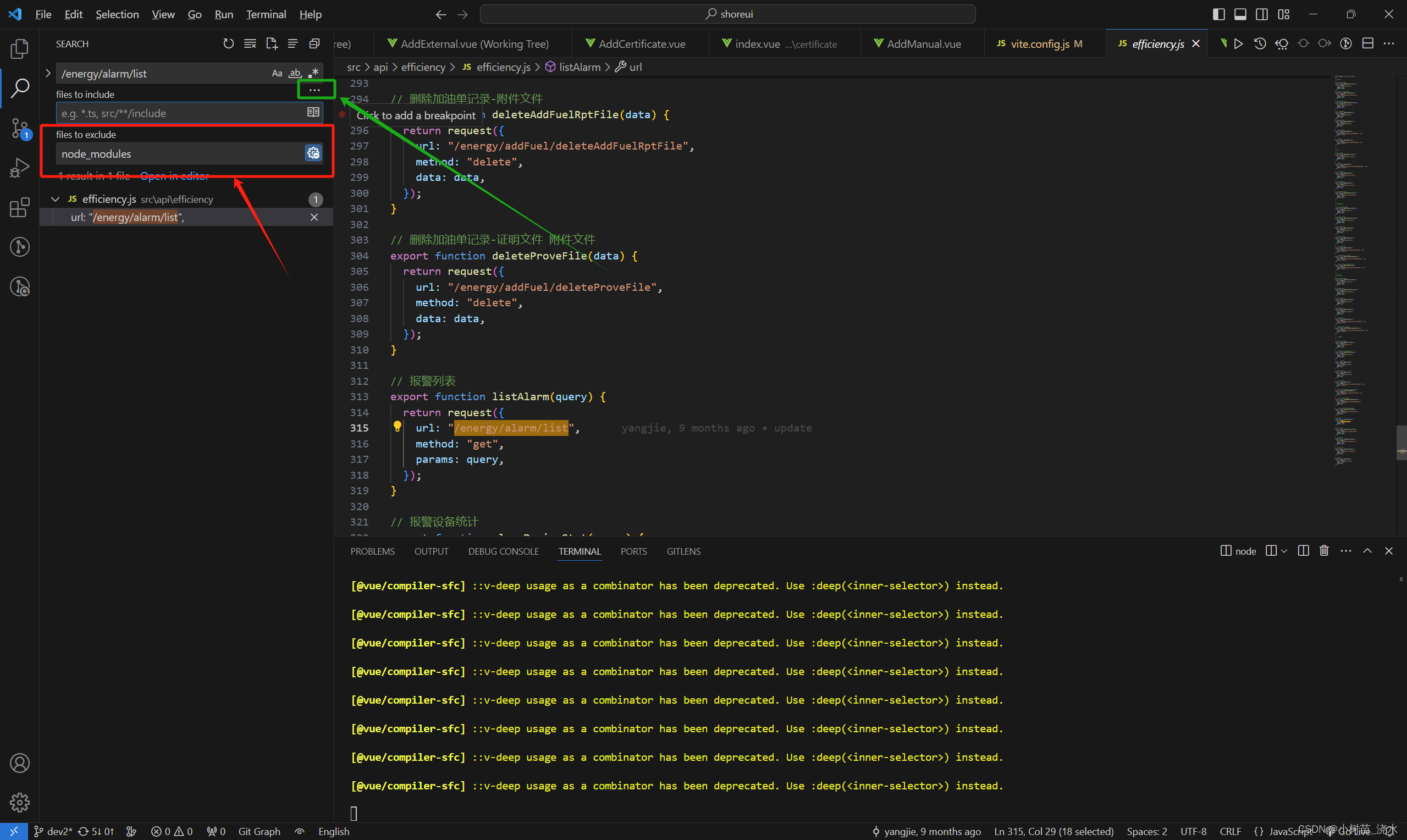
解释一下,红框里面是选择搜索时要排除的文件,node_modules文件夹是npm install库时存放的包,所以这个文件夹一定要排除!其它的影响都不大了。更新VS Code后总感觉全局搜索很慢,可能是有些数据被不小心修改了。如果你的页面没有这个输入框 你只需要点一下绿色框中的三个点就行了!
听说过删库跑路被抓的,今天就碰到升级服务器(Alibaba Cloud Linux ----> Ubuntu)原因是taos3.2不支持Alibaba Cloud Linux系统!为了保险起见把现在这个数据库里的数据都备份一份,为了不耽误同事们继续开发所以需要将需要升级的数据库在另一个服义务器中再跑一份出来!有navicat帮忙数据迁移很方便!但是犯错就在图方便上了!因为迁移的这两个数据库中有几个