- @u013524655
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
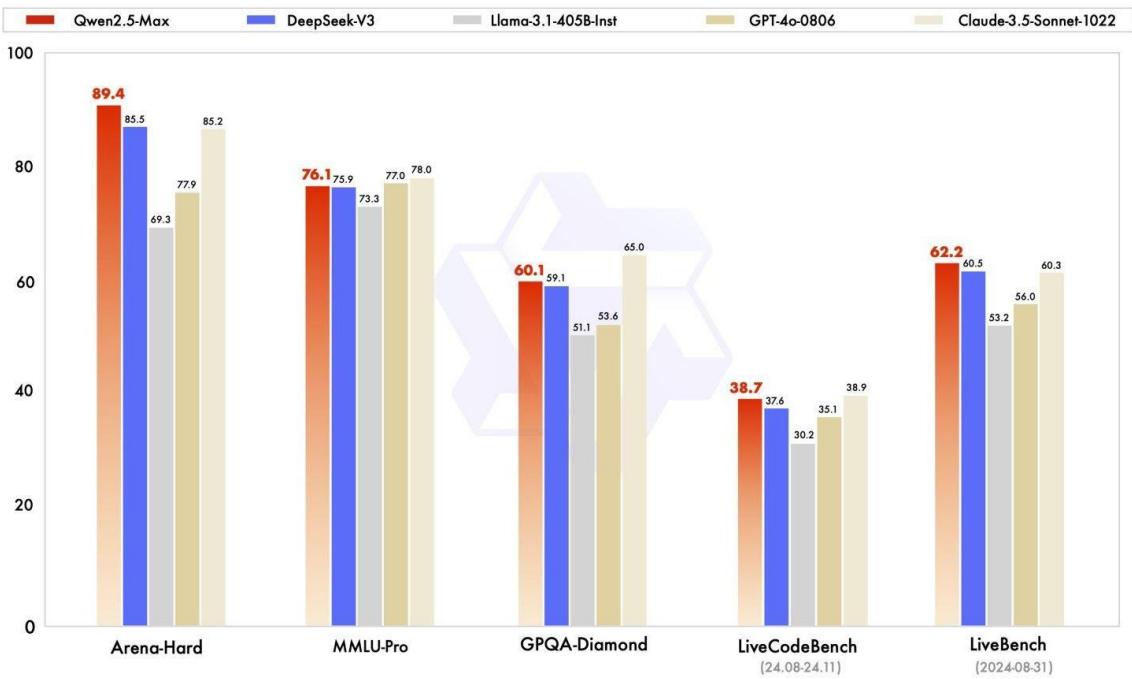
Deepseek 和通义千问LLMs在2025年初因其低成本和开放访问的LLM解决方案而变得流行。一家位于中国浙江省杭州市的公司于2024年12月宣布了其新的LLM,DeepSeek v3。随后,阿里巴巴于2025年1月29日发布了其AI模型通义千问2.5 Max。这些免费且开源的工具对世界产生了重大影响。Deepseek和通义千问也有潜力被世界各地的许多研究人员和个人用于学术写作和内容创作。因此
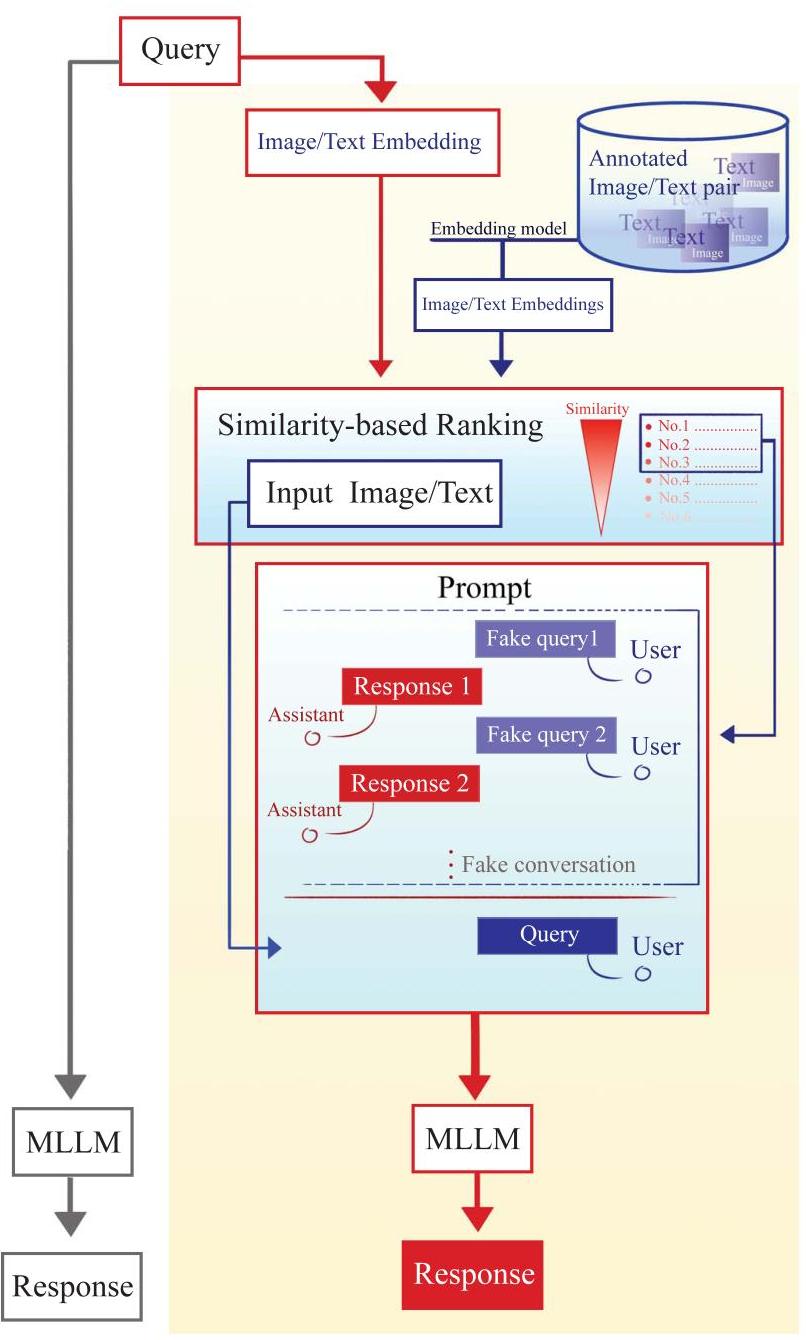
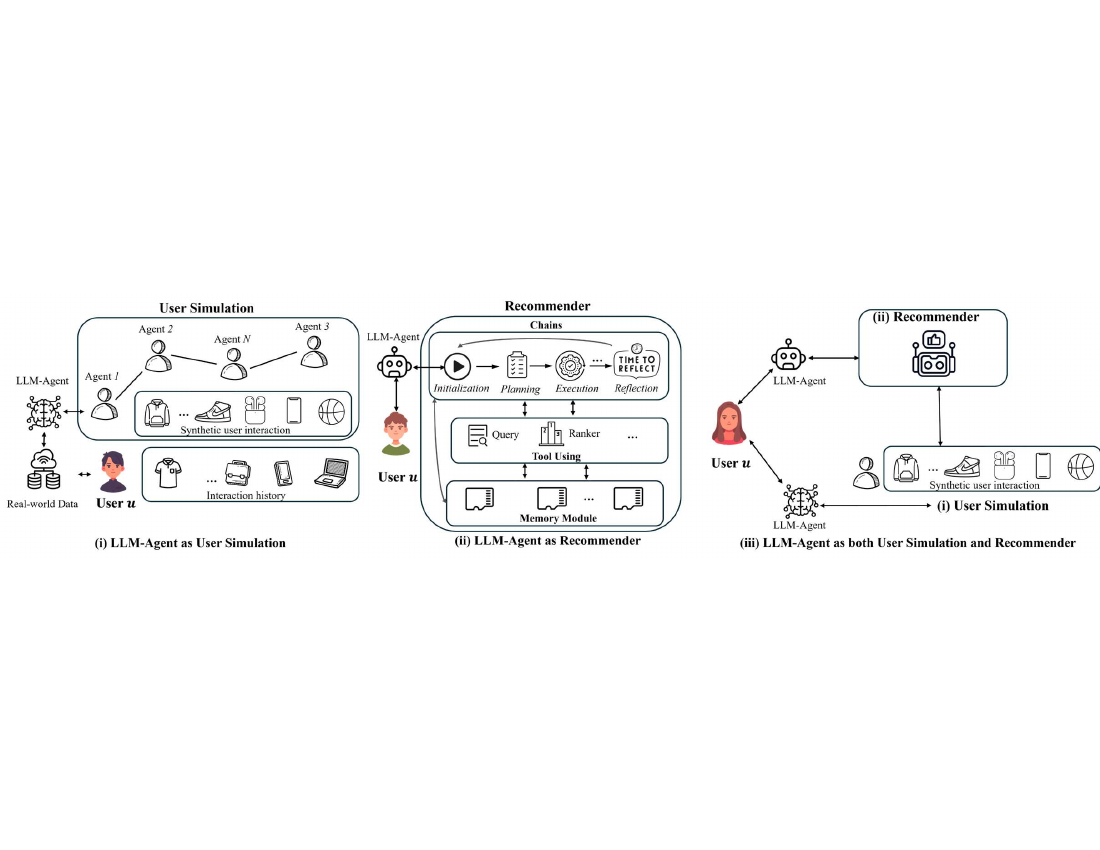
近期大语言模型(LLMs)的突破性进展催生了超越单一模型能力的代理型人工智能系统。通过赋予LLMs感知外部环境、整合多模态信息和与各种工具交互的能力,这些代理系统在复杂任务中表现出更大的自主性和适应性。这一演变带来了推荐系统(RS)的新机遇:基于LLM的代理型推荐系统(LLM-ARS)可以提供更加互动、情境感知和主动的推荐服务,可能重塑用户体验并拓宽推荐系统的应用范围。尽管早期结果令人鼓舞,但基本
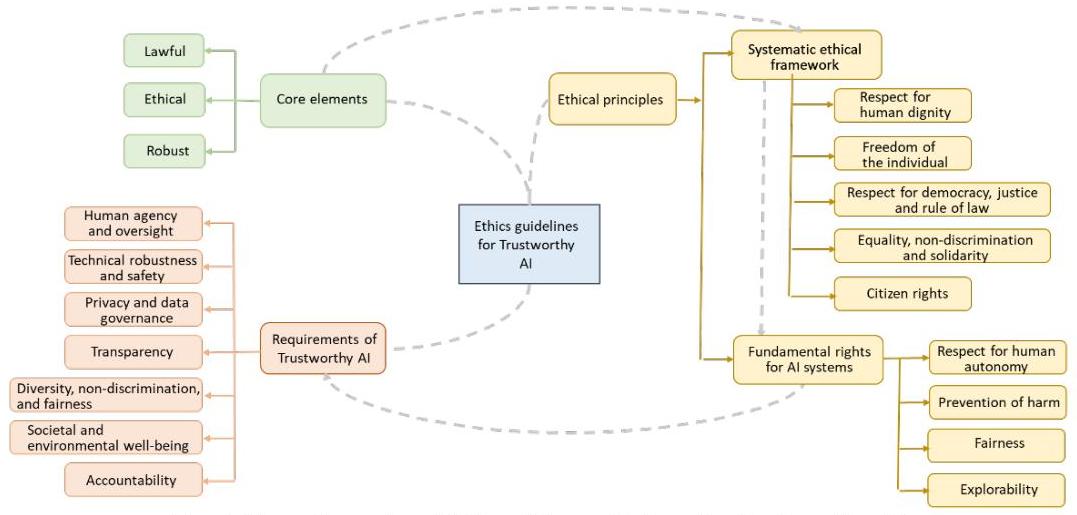
近年来,人工智能技术在各个领域和行业中的各种应用中表现出色。然而,神经网络中的各种算法使得理解决策背后的原因变得困难。因此,可信赖的人工智能技术开始受到欢迎。可信的概念是跨学科的;它必须符合社会标准和原则,并且技术被用来满足这些要求。在本文中,我们首先调查了各国和地区关于使人工智能算法值得信赖的伦理要素的发展;然后重点调查了人工智能可解释性的最新研究。我们对用于使人工智能可解释的技术和技巧进行了深
转载自:摘 要:电信领域欺诈现象比较突出,本文对数据挖掘技术在电信欺诈侦测中的应用进行研究,并利用某移动运营商的真实数据进行有效性验证。具体通过商业理解、数据理解、数据准备、模型生成、模型应用等几个步骤完成欺诈的侦测。在模型生成阶段利用聚类算法中的Kohonen神经网络算法,Kohonen是一种自组织学习算法。【关键字】数据挖掘;欺诈侦测;kohonen算法;CRIS
PandasAI 是一个 Python 库,它让您可以轻松地使用自然语言向数据提问。除了查询功能外,PandasAI 还提供了通过图表可视化数据、通过处理缺失值来清理数据集以及通过特征生成来提高数据质量的功能,使其成为数据科学家和分析师的综合工具

近期,AWS 推出了一款名为 Multi-Agent Orchestrator 的全新开发工具,其设计目的在于简化开发人员对复杂 AI 交互的管理流程。这款工具具备高效的请求分配机制,能够精确地将用户请求路由至最合适的 AI 代理,并且能实时追踪对话状态,从而满足从基础聊天机器人到高级 AI 系统的多样化需求。

PandaAI 是一个开源框架,将智能数据处理和自然语言分析相结合。无论您是处理复杂的数据集,还是刚刚开始数据之旅,PandaAI 都提供了定义、处理和高效分析数据的工具。通过其强大的数据准备层和直观的自然语言界面,您可以在不编写复杂代码的情况下将原始数据转化为可操作的见解。对于之前版本的用户来说,PandaAI 3.0 (目前处于测试阶段)标志着一个重要的发展,它不仅超越了对话分析,还引入了一个

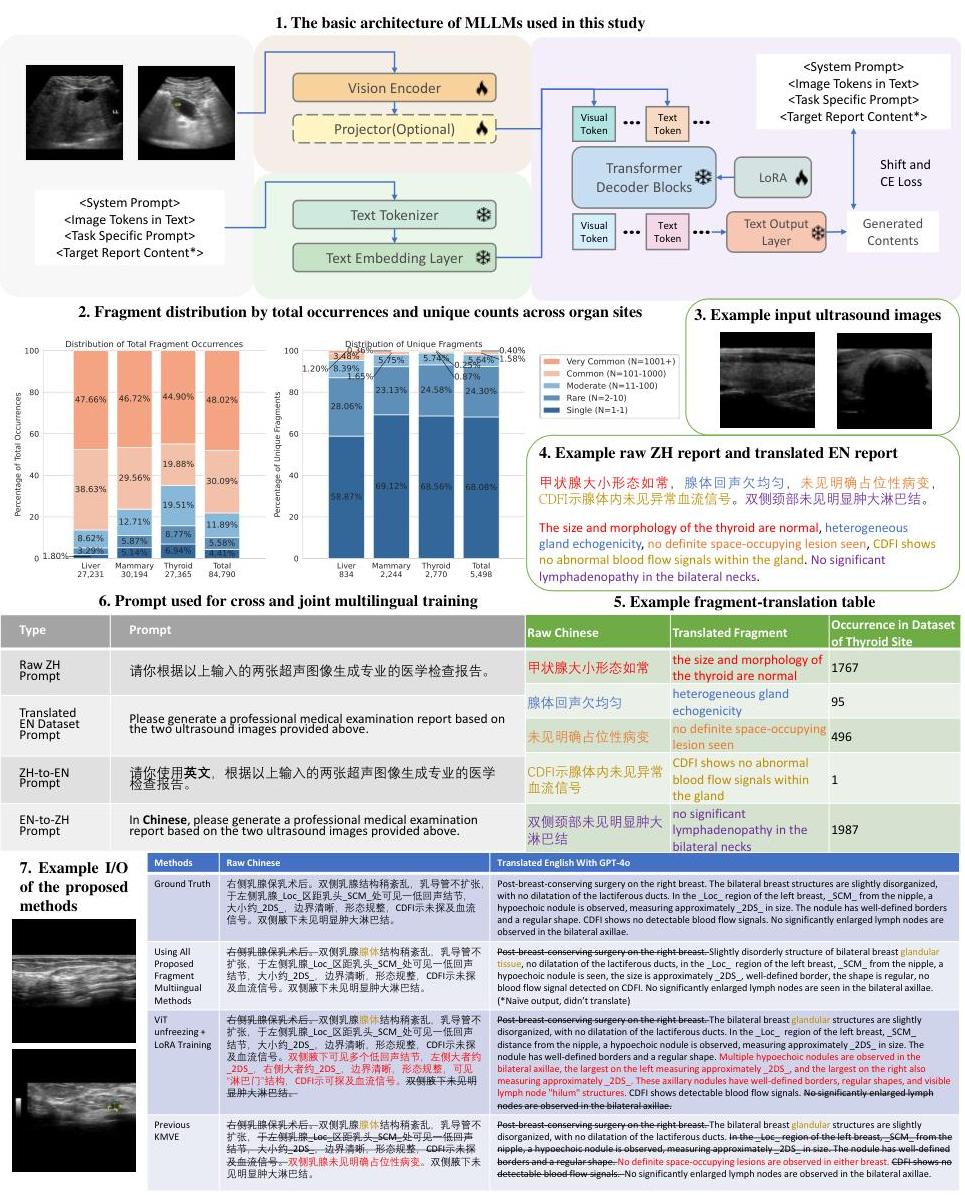
由于超声图像的可变性、操作者依赖性和对标准化文本的需求,超声(US)报告生成是一项具有挑战性的任务。与X射线和CT不同,超声成像缺乏一致的数据集,使得自动化变得困难。在本研究中,我们提出了一种统一框架,用于多器官和多语言的超声报告生成,结合基于片段的多语言训练,并利用超声报告的标准化特性。通过将模块化文本片段与多样化的影像数据对齐,并策划一个双语英汉数据集,该方法实现了跨器官部位和语言的一致且临床
目标:我们旨在动态检索信息丰富的示例,以增强多模态大语言模型(MLLMs)在疾病分类中的上下文学习。方法:我们提出了一种检索增强上下文学习(RAICL)框架,该框架将检索增强生成(RAG)和上下文学习(ICL)相结合,自适应地选择具有相似疾病模式的示例,从而提高MLLMs的ICL效果。具体来说,RAICL检查来自不同编码器的嵌入,包括ResNet、BERT、BioBERT和ClinicalBERT