- @zhazhagu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
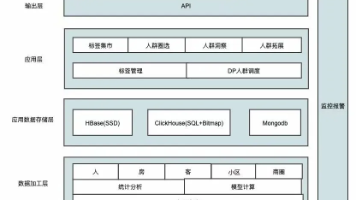
贝壳DMP平台通过统一埋点规范收集用户线上线下行为数据,构建主题宽表实现用户数据归一,利用Spark、HBase等技术实现海量数据处理和实时画像计算。平台采用ClickHouse、MongoDB等多存储方案,支持秒级人群预估和分钟级复杂计算,提供标签管理、人群圈定、精准推送等功能。经过两年发展,该平台已广泛应用于广告投放、个性化推荐等场景,显著提升用户精细化运营效果。未来将持续优化标签深度、效果提
文章摘要: 在使用Docker Compose配置MySQL 8.0服务时遇到容器启动失败问题。当使用卷名"hive-metastore-data"时出现MySQL系统表缺失错误(如mysql.plugin表不存在),而使用"hive_metastore_data"则正常。错误日志显示MySQL无法打开系统表,提示需要进行升级操作。该问题可能与卷名称中的连字
之前部署了单节点环境这里我们使用最新的镜像elasticsearch:9.0.4来部署下集群,目前自己学习中暂时没用logstash 就没有添加这个服务。
本文介绍了如何使用Docker Compose部署PostgreSQL与ClickHouse集成环境。通过pg_clickhouse扩展实现PostgreSQL访问ClickHouse数据,包含三个主要步骤:1) 使用Docker Compose启动PostgreSQL(pg_clickhouse)和ClickHouse服务;2) 在ClickHouse中创建taxi.trips表并导入NYC出租
大数据面试之Oozie1.Oozie1.1 Oozie介绍说明,感谢亮哥长期对我的帮助,此处多篇文章均为亮哥带我整理。以及参考诸多博主的文章。如果侵权,请及时指出,我会立马停止该行为;如有不足之处,还请大佬不吝指教,以期共同进步。1.Oozie1.1 Oozie介绍大数据协作框架三大功能- Oozie Workflow jobs :工作流任务,可以生成DAG图- Oozie Coordinator
大数据面试之Spark1.Spark1.0 Spark架构1.1 Spark的Shuffle过程?与Hadoop的Shuffle过程对比1.2 Spark中reduceBykey和groupBykey的区别1.3 Spark中和repartition相似的算子?优缺点1.4 Spark的调优1.5 Spark中数据倾斜处理1.6 Spark的多种提交方式?python提交方式?1.7 Spark广
Sisyphus 是 Oh My OpenCode 的核心 Agent,相当于一个"项目经理"。遇到问题先规划:不会一上来就写代码,而是先拆解任务擅长分工协作:把不同的工作分配给专门的 Agent持续跟进:用 Todo 列表跟踪进度,直到任务完成并行执行:能同时启动多个 Agent 处理不同的事Agent职责什么时候用Sisyphus总指挥,负责规划和协调所有任务都会经过它Oracle高难度问题顾
Linux服务器性能评估与优化指南 本文介绍了影响Linux服务器性能的关键因素和评估方法。主要从CPU、内存和磁盘I/O三个方面进行分析: CPU评估:通过vmstat和sar命令监控,当%user+%sys>80%时可能存在CPU瓶颈;单线程应用可能导致个别CPU满载而整体利用率不高。 内存评估:使用free和vmstat命令检查,当可用内存占比<20%时需要扩容;swap交换频繁
本文介绍了基于LLama-Factory框架使用LoRA算法微调Deepseek大模型,并通过FastAPI提供HTTP接口的完整流程。文章首先对比了SFT、RLHF和RAG三种模型优化方法的特点与适用场景,重点阐述了LoRA微调算法的低秩分解原理和计算优势。随后详细说明了使用Docker Compose部署LLaMA-Factory的环境搭建步骤,包括配置镜像源、GPU支持和数据卷挂载等关键配置