登录社区云,与社区用户共同成长
邀请您加入社区
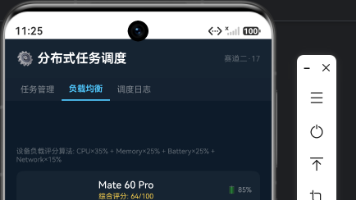
本文深入解析鸿蒙分布式任务调度机制,重点解决跨设备任务流转中的核心痛点问题。系统通过分布式任务管理层(distributedMissionManager)和流转管理器(continuationManager)协同工作,实现任务状态序列化、安全传输和设备间恢复。 关键实现包括: 任务生命周期管理:通过onContinue()序列化状态,经软总线传输后由onRestore()恢复 状态序列化机制:支持
摘要: 从GPT-4迁移到DeepSeekV4后成本降低80%,但遭遇API限流问题(429错误)。解决方案采用多Key负载均衡,通过One-API自动轮换多个DeepSeek账户Key,实现故障自动切换。改造后日均429错误从200+降至3次以内,并在官方宕机时保持服务稳定。作者搭建了稳定版服务(aicreditsapi.com),支持多Key自动容灾和实时监控,提供免费试用。
本文详解如何基于 AMD Instinct GPU 与 vLLM 构建高可用大模型推理服务。通过多副本部署、智能负载均衡及自动化故障转移策略,解决单点故障难题,确保生产环境稳定运行,打造坚实的 AMD 大模型推理服务架构。
在AI应用开发中,API网关作为连接客户端与后端服务的核心中间层,其核心价值在于统一接口、提升系统稳定性和可扩展性。其工作原理是通过接收标准化请求,进行认证、路由和协议转换后,转发至相应的后端服务,并将响应统一格式化返回。这一技术架构对于整合多源异构的大模型服务(如OpenAI、Claude及国内模型)至关重要,它能有效解决网络不稳定、厂商API差异和调用频率限制等工程难题。通过实现负载均衡与故障
文章摘要:随着大语言模型百花齐放,开发者面临多模型对接难题。AI API聚合平台应运而生,通过统一接口格式、计费体系和运维托管,将对接周期从数天缩短至数小时。该平台支持按场景智能选模,适用于SaaS集成、知识库等场景,正成为大模型时代的基础设施,让开发者专注应用创新而非对接工作。选型需关注模型覆盖度等五个维度。
本文对比了主流负载均衡方案的核心特性与适用场景。HAProxy作为专业负载均衡器,在四七层转发、会话保持和性能调优方面表现突出,尤其适合高并发HTTP/TCP服务。LVS凭借内核级转发在超大规模流量场景占据优势,但配置复杂且功能单一。Nginx作为多功能Web服务器适合中小型网站,而Envoy和Traefik更适配云原生环境,分别擅长服务网格和Kubernetes场景。硬件方案F5则适用于金融级高
NAT模式TUN模式DR模式RS操作系统不限支持隧道禁用arp调度器和服务器网络可跨网络可跨网络不可跨网络调度服务器数量服务器数量少多多RS服务器网关指向到调度器DIP指向到路由指向到路由LVS-NAT与LVS-fullnat:请求和响应报文都经由DirectorLVS-NAT:RIP的网关要指向DIPLVS-Fullnat:RIP和DIP未必在同一网络,但要能通信。
大模型线上服务高频遇到 429 限流、单账号配额打满问题,单纯重试、模型降级无法根治。本文从工程实战角度,讲解多账号负载均衡方案,通过同模型多账号配额叠加、轮询调度、429 自动剔除、冷却自愈机制,低成本解决常态化限流问题,附带极简可上线代码,适合 AI 工程落地参考。
混合专家模型(MoE)作为大语言模型的关键架构,通过稀疏激活机制在保持计算效率的同时大幅提升模型参数量。其核心原理是利用门控网络动态选择专家子网络处理不同输入,但这也带来了显著的负载均衡挑战。在工程实践中,MoE模型因专家激活的随机性导致硬件计算单元利用率波动,影响推理性能。时分复用(TDM)作为一种经典的资源调度技术,通过将时间划分为固定时隙实现多任务高效轮转。AMD MI500X创新性地引入T
大模型API调用已成为AI开发的核心环节,其计费策略直接影响项目成本控制。本文从分布式系统负载均衡原理切入,解析主流平台免费额度的技术实现差异,包括令牌桶算法、QPS限制等底层机制。针对多模型协同场景,提供基于Python的动态路由方案和Prometheus监控体系,帮助开发者在GPT-5、Claude-4等大模型间实现智能配额分配。特别针对Anthropic对话次计费、Gemini动态限流等典型
缺点是它的伸缩能力有限, 当服务器结点数目升到 20 时,调度器本身有可能成为系统的新瓶颈,因为在 VS/NAT 中请求和响应报文都需要通过负载调度器。LVS/NAT 的优点是服务器可以运行任何支持 TCP/IP 的操作系统,它只需要一个 IP 地址配置在调度器上,服务器组可以用私有的 IP 地址。,支持 3 节点、多资源、多种模式(主备、双主、多实例),可以管理 VIP、Apache、NFS、数
模型路由(ModelRouter)与负载均衡(LoadBalancer)存在本质区别。负载均衡关注的是流量分发和服务器资源分配,而模型路由解决的是智能决策问题,即根据任务特性选择最适合的大模型(如DeepSeek、通义千问等)。模型路由需要理解请求内容、评估模型能力、成本和延迟,并实现故障切换等智能调度功能。在AI时代,企业更需要模型路由提供的模型选择、成本优化和智能决策能力,而不仅仅是流量分发。
本文详细探讨了如何使用 Nginx 代理 Ngrok 服务实现负载均衡的技术实践与优化方案。首先通过 Flask 构建了一个简单的 API 服务,并结合 Ngrok 提供的公网隧道功能进行测试,发现 Ngrok 对 Host 头部有严格校验,必须与隧道域名完全匹配。文章对比了两种代理配置方案:单层代理:直接通过 Nginx 配置代理到 Ngrok 隧道,但存在硬编码问题,难以支持多域名扩展。分层代
为了防止黑客攻击,提高服务器的安全性,我们可以伪装或者隐藏真实的服务器环境。
随着技术的不断发展和生态系统的不断完善,WebAssembly将在未来的Web开发中发挥越来越重要的作用,为用户提供更加丰富和高效的Web体验。例如,Emscripten是一个流行的C/C++到Wasm的编译器,Rust语言也提供了对Wasm的原生支持。与JavaScript相比,Wasm代码在执行时可以接近原生代码的性能,特别适合处理复杂的计算任务,如图像处理、音频处理、游戏开发等。例如,未来可
常规的web服务器一般提供对于静态资源的访问,比如说:图片、web样式网站提供的大部分交互功能都需要web编程语言的支持,而web服务对于程序的调用,不管编译型语言还是解释型语言,web服务同将对于应用程序的调用递交给通用网关接口(CGI)。CGI 服务完成对于程序的调用和运行,并将运行结构通过CGI接口返回给web服务,由web服务生成响应报文。此时在web服务的领域内,引入了LAMP等较为知名
keepalive+nginx
在地理信息系统(GIS)领域,GeoServer作为一个强大的开源服务器,能够发布各种地图服务,包括瓦片地图服务。为了提高服务的可用性和扩展性,结合Tomcat和Nginx实现负载均衡成为了一个有效的解决方案。本文将详细介绍如何通过GeoServer发布瓦片地图,并使用Tomcat和Nginx实现负载均衡。GeoServer瓦片地图发布技术路线1. GeoServer安装与配置安装GeoServe
微服务本地调试优化方案 在微服务开发中,针对本地调试需启动全套环境的问题,提出了一种优化方案: 核心思路:通过自定义负载均衡规则,仅让本地浏览器请求进入本地服务 实现方式: 浏览器请求添加Prefer-Lb-IP头指定本地IP Gateway通过GlobalFilter获取请求头并存入ThreadLocal 自定义LB规则优先选择指定IP的服务 技术实现: 使用ModHeader插件添加请求头 通
Nginx选择事件驱动模型而非多线程,本质上是CAP理论中在高并发场景下的架构权衡。使用perf top分析事件循环热点通过扩展复杂逻辑监控的waiting指标定期进行sysbench压力测试理解这一设计哲学,将帮助Java工程师在微服务架构中做出更合理的组件选型决策。
epoll模型的高性能源于其精妙的内核设计,理解其核心原理对架构高并发系统至关重要。使用观察系统调用通过perf top分析热点函数监控了解TCP状态定期进行ab -k测试保持连接掌握这些技能,你将能设计出真正支撑百万级并发的系统架构。
在8.6MySQL服务器上,查看在图形化软件上创建的数据库和表。在xshell上再次连接代理服务器,实际连的是web1。安装并连接navicat for mysql(图形化)配置4层负载均衡,发布内部服务器的ssh和mysql。修改代理(8.7)的配置文件,添加负载均衡功能。经过max_fails失败后,服务的暂停时间。max_conns同一ip最大连接数。在web2(8.6)安装mysql。在8
写一个配置类,添加@Configuration注解,在配置类中添加一个路由,在后端添加一个header,response添加一个返回header。applocation.yaml设定nacos地址启动loadbalance。项目启动后在nacos查看到网关服务和后端服务。,header中有666 成功!依赖,pom.xml参考。
负载均衡的例子,我记得阿里云也有自带的负载均衡的操作,只要简单的购买部署就行了。刚刚好我看到一个项目和已有的项目有些相似就自己部署一下可能往后有用呢!宝塔准备几个网站,或者几个服务器,前者一台服务器就可以,成本更低。在相同的情况下部署才不会丢失文件或者重复登录等等奇怪问题。解析到 80端口,建议只做转发不做项目部署。负载均衡,简单来说就是一份代码多次部署。1,数据库是否相同一个如mysql。这里只
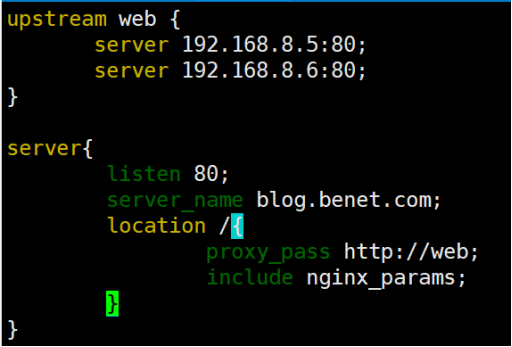
使用upstream定义后端服务器集群。配置负载均衡算法:轮询、最少连接或 IP 哈希。配置健康检查机制,确保故障服务器不会接收到流量。配置代理请求头,转发原始客户端信息到后端服务器。负载均衡不仅能提高网站的可用性和扩展性,还能帮助减轻单台服务器的负载。在高可用性和高流量场景下,Nginx 是一个强大的负载均衡解决方案。
分层防御:边缘限流->应用限流->业务限流动态调整:基于后端负载自动调节阈值精准控制:用户/业务/接口多维度限流容错设计:避免雪崩效应,保障核心业务生产环境始终启用nodelay参数burst大小设置为正常QPS的20%-50%监控限流触发情况并设置告警定期压测验证限流效果这些经验在应对淘宝双11、抖音春晚红包等场景中得到了充分验证,是构建高可用系统不可或缺的核心能力。
本文详细介绍了Nginx的安装配置与负载均衡实现方法。主要内容包括:1)Nginx的编译安装步骤,包括依赖安装、配置参数说明;2)Nginx配置文件结构解析,包括全局块、events块、http块等核心模块;3)负载均衡实现方案,包括轮询、加权轮询、IP哈希等策略;4)动静分离配置方法;5)虚拟主机配置,涵盖基于域名、IP和端口的三种实现方式。通过多个具体示例,展示了Nginx作为反向代理服务器的
nginx负载均衡入门
在网关中配置工具域名来进行路由转发,测试发现并未生效,原因是nginx转发请求会丢失域名信息,需要在nginx的server块配置文件gulimall.conf中配置中重设请求头域名信息,配置如下。更好的方式是nginx将请求转发给网关,由网关实现路由转发和负载均衡。这种配置方式允许Nginx作为一个反向代理服务器,将请求分发到不同的后端服务。在conf.d目录下的gulimall.conf做如下
摘要:Nginx反向代理通过接收客户端请求并转发至后端服务器(如Tomcat、Node.js)实现请求中转,隐藏真实服务器。配置需在nginx.conf中设置proxy_pass指向后端地址,并保留原始请求头信息。Nginx还支持负载均衡功能,提供轮询、最少连接数等策略,将请求智能分配到多台后端服务器,提高系统性能与可用性。其中轮询为默认策略,最少连接数则按服务器当前负载动态分配。通过upstre
可观测性优先:每个-s操作必须配套完整的监控指标渐进式变更:遵循"先验证、后灰度、再全量"的原则设计容错:任何单点操作都要预设回滚方案配置差异比对变更影响预测自动回滚机制全球同步能力记住:最优秀的工程师不是让reload从不失败,而是当失败发生时,用户完全感知不到。
我来拆开解释一下sglang里为什么还要一个 sgl-router,即使在 Kubernetes 里本身就有 Service 的负载均衡机制。
在配置nginx作为反向代理和负载均衡,同时配置python脚本接收文件上传参数的情况下,可以在nginx.conf文件新增一个server。具体操作和步骤如下。
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。通常不允许不同源间的读操作。如果两个页面的协议,端口(如果有指定)和域名都相同,则两个页面具有相同的源。
负载均衡
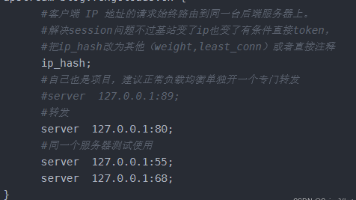
Nginx提供了多种负载均衡策略,包括轮询、加权轮询、最少连接、IP哈希、响应时间优先(Nginx Plus专属)和随机算法。配置方法简单,通过upstream模块定义后端服务器群,支持权重设置、健康检查、备份服务器等高级功能。不同策略适用于不同场景:加权轮询适合常规Web应用,IP哈希保持会话一致,最少连接优化长连接服务。建议结合健康检查、性能监控和日志分析,根据实际需求选择最佳策略,并注意解决
在企业级微信应用(如客服系统、营销机器人、消息中台)中,常需对微信API进行高频调用(如每秒数百次消息发送、用户信息同步)。单机部署易因网络延迟、限流(如access_token获取频率限制)、GC停顿等问题导致失败率上升。通过集群化部署与合理负载策略,可显著提升吞吐量与容错能力。通过无状态设计、共享缓存、分布式锁、服务注册发现与多层负载均衡,Java后端服务可在高并发微信API调用场景下实现高可
以下是一个完整的 Nginx 配置示例,实现反向代理与负载均衡功能。假设需要将请求分发到三个后端服务器(块定义了后端服务器组,默认使用轮询策略。),并采用轮询(round-robin)负载均衡策略。指令确保后端服务器能获取原始请求信息。保留客户端真实 IP,
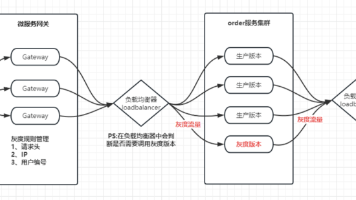
在请求进入网关时开始对是否要请求灰度版本进行判断,通过Spring Cloud Gateway的过滤器实现,在调用下游服务时重写一个Ribbon的负载均衡器实现调用时对灰度状态进行判断。存取请求灰度标记Holder(业务服务也是使用的这个)使用ThreadLocal记录每个请求线程的灰度标记,会在前置过滤器中将标记设置到ThreadLocal中。/*** 标记是否使用灰度版本* 具体描述请查看 {
本文介绍了如何在星图GPU平台上自动化部署🌿 Phi-3 Forest Laboratory | 森林晨曦实验室镜像,实现高效的多卡推理负载均衡。该方案特别适用于处理128K长上下文的AI对话任务,通过A10G/A100显卡集群的智能分配,显著提升并发处理能力和响应速度,满足高负载场景下的性能需求。
——负载均衡
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台
 AI编程社区
AI编程社区
 智能体开发者社区
智能体开发者社区


 AtomGit AI 社区
AtomGit AI 社区
 openEuler 社区
openEuler 社区



 DeepSeek技术社区
DeepSeek技术社区