




- @heian_99
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了Kubernetes配置热更新的解决方案Reloader。它解决了ConfigMap/Secret更新后应用不自动加载的问题,通过监听配置变更并触发关联工作负载的滚动更新来实现配置生效。文章详细分析了env注入与volume挂载的差异,提供了Reloader的三种使用策略:自动更新、匹配更新和指定资源更新,并通过Nginx示例演示了配置变更触发滚动更新的完整流程。最佳实践建议根据业务场景
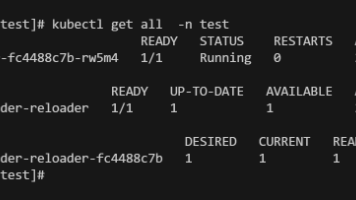
本文探讨了容器和Kubernetes环境中僵尸进程的危害及解决方案。僵尸进程会占用有限的PID资源,导致节点不稳定。由于容器内的PID 1通常不是传统init进程,无法回收子进程,使问题更严重。文章分析了Linux进程回收机制,提出三类Kubernetes解决方案:共享进程命名空间、使用轻量init(如tini/dumb-init)作为PID 1,以及运行时层启用init。其中推荐在生产环境中使用
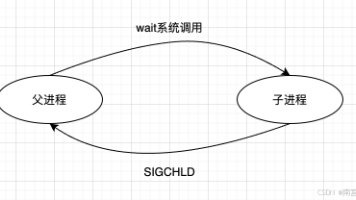
本文介绍了在生产环境中使用Grafana Loki搭建轻量级日志系统的实践方法。Loki通过仅索引标签而非日志内容的设计,显著降低了资源消耗和运维复杂度。文章详细讲解了Loki的核心优势、适用场景及数据流架构(GLP:Grafana+Loki+Promtail),并提供了Helm部署Loki、Grafana配置及Promtail采集日志的具体步骤。重点包括:单机模式Loki的快速部署、LogQL查
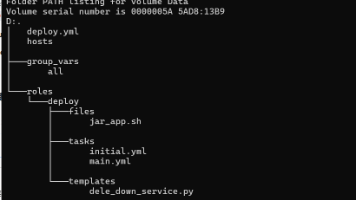
本文介绍了一个基于Ansible的Java应用部署方案,通过200行YAML和一个Shell脚本实现了幂等初始化、版本管理和服务生命周期管理。方案采用以下核心设计: 目录结构设计: 使用package、runtime、backup、rollback四个目录实现版本管理 通过权限分层(0755/0750)保障安全性 幂等性保障: stat检测+条件include实现初始化与更新的分离 lineinf
摘要:本文介绍了一个企业内部智能助手的落地实践,通过WebSocket+Claude Agent SDK构建,采用滚动摘要窗口解决上下文断裂问题,进程池优化冷启动延迟,热插拔工具系统实现低成本扩展。关键设计包括严格划定安全边界、量化评估指标(机器人接手率≥50%、回答可用率≥70%),以及权限分级管控。上线后使研发打断次数减少75%,工单响应时间从15分钟缩短至3分钟,验证了轻量级AI工具在提升内

摘要:本文介绍了一个企业内部智能助手的落地实践,通过WebSocket+Claude Agent SDK构建,采用滚动摘要窗口解决上下文断裂问题,进程池优化冷启动延迟,热插拔工具系统实现低成本扩展。关键设计包括严格划定安全边界、量化评估指标(机器人接手率≥50%、回答可用率≥70%),以及权限分级管控。上线后使研发打断次数减少75%,工单响应时间从15分钟缩短至3分钟,验证了轻量级AI工具在提升内
摘要:本文介绍了一个企业内部智能助手的落地实践,通过WebSocket+Claude Agent SDK构建,采用滚动摘要窗口解决上下文断裂问题,进程池优化冷启动延迟,热插拔工具系统实现低成本扩展。关键设计包括严格划定安全边界、量化评估指标(机器人接手率≥50%、回答可用率≥70%),以及权限分级管控。上线后使研发打断次数减少75%,工单响应时间从15分钟缩短至3分钟,验证了轻量级AI工具在提升内
本文介绍了一个适用于Linux和Windows环境的开发者配置方案,重点针对全栈工程师在TypeScript、Python和Go项目中的开发规范。配置强调安全优先、最小改动原则和简单性设计,包含代码风格、Git策略、验证流程等详细规则。特别注重跨平台兼容性,要求根据运行环境自动适配命令和路径格式。配置还制定了严格的提交规范、环境识别方法和服务进程管理策略,确保开发过程的可维护性和一致性。所有规则按
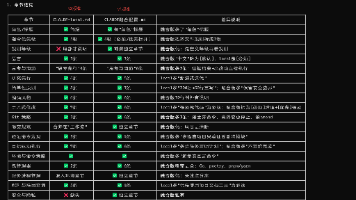
本文探讨了如何通过项目级配置提升AI编程助手的工作稳定性。文章指出,仅依靠临时Prompt会导致AI行为不一致,建议将项目规则、技术栈约束等沉淀为配置文件。推荐的项目目录结构包含CLAUDE.md主规则文件、本地偏好配置、hooks脚本等模块。核心配置原则包括:将CLAUDE.md写成可执行的行为约束而非愿景文档;强调简单性原则和手术式修改;明确Windows环境下的特殊要求;为不同技术栈制定局部

这是一个基于 Python 的 CSDN 博客数据可视化看板项目,通过爬虫采集 CSDN 博客数据,并以现代化的可视化界面展示博主的各项数据指标。该项目采用前后端分离架构,集成了数据采集、数据存储、API 服务和数据可视化等多个功能模块。
