




- @weixin_51589123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
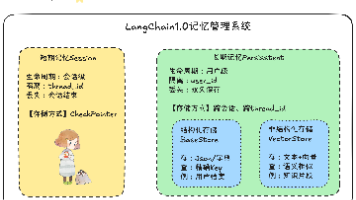
第一章:【Agent】大模型在线API接入基础入门第二章:【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)第三章:【Agent】LangChain 1.0架构Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain
深度学习基础,利用mnist数据实现前反馈神经网络、卷积神经网络和自编码神经网络
第一章:【Agent】大模型在线API接入基础入门第二章:【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)第三章:【Agent】LangChain 1.0架构Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain
第一章:【Agent】大模型在线API接入基础入门第二章:【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)第三章:【Agent】LangChain 1.0架构Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain
SDK(Software Development Kit,软件开发工具包)。SDK 是对 API 的封装,让开发者不需要手写复杂的 HTTP 请求,而是用简洁的代码就能调用 API。
自然语言处理(Natural Language Processing)简称NLP,是一种利用计算机为工具对人类特有的书面形式和口语形式的自然语言的信息进行各种类型处理和加工的技术。
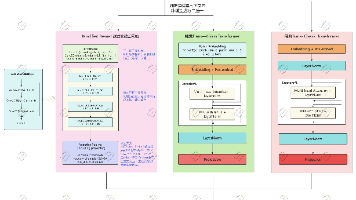
多模态大模型(Multimodal Large Model)是一种能够处理和理解多种模态数据的人工智能模型。模态指的是数据的表现形式,例如文字、图像、音频、视频等。多模态大模型通过结合不同模态数据的特性,利用深度学习技术和大规模的训练数据,构建一个统一的框架来实现跨模态的感知、理解和生成能力。例如,一个多模态大模型可以同时处理文本描述和对应的图片,完成图像生成、描述生成、跨模态检索等任务。这种模型
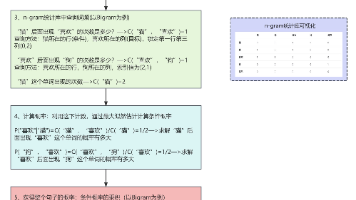
对于L来说,计算L,对于一对(vt,vc)来说,需要计算b次点积(b是词向量的特征个数:n-dim),复杂度为O(b),对于一对(vt,vc)来说,需要计算k个负样本的概率值,也就是计算k次,总时间复杂度为O(kd)—>O(1)。但是此时的Lbound下界是一个得分,但我们最终要计算的是一个概率,那就需要给这个L得分套上一个sigmoid激活函数,再取对数值,起到一个放大差异的作用,最终我们需要有
重点了解正向传播中的递归中的数据流向,反向传播的梯度更新。输入数据格式为:(seq_len, batch_size, input_dim) 。二、RNN情感分类任务情感分类(Sentiment Classification),是自然语言处理(NLP)中的一个经典任务,旨在对文本进行情感分类,通常包括将文本氛围“正面”、“负面”或“中性”等情感类别。IMDb数据集是情感分类任务的著名数据集,包含来自
提示:持续更新。