




- @cndrip
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文为kaggle机器学习中级课程 第二部分 Missing ValuesMissing values happen.Be prepared for this common challenge in real datasets.缺失值的发生,为现实数据集中的这一常见挑战做好准备。本教程中,您将学习三种处理缺失值的方法。然后,您将在真实数据集上比较这些方法的有效性。
SHAP 值 (SHapley Additive exPlanations的首字母缩写)对预测进行分解,以显示每个特征的影响。你可以在哪里使用这个?一个模型说,银行不应该借钱给某人,法律要求银行解释每笔拒绝贷款的依据医疗保健提供者想要确定是什么因素导致每个病人患某种疾病的风险,这样他们就可以通过有针对性的健康干预措施直接解决这些风险因素在本次课程中,您将使用SHAP 值 来解释单个预测。

本文为kaggle机器学习中级课程 第七部分 Data Leakage --Find and fix this problem that ruins your model in subtle ways.在本教程中,您将了解什么是数据泄漏以及如何防止它。如果你不知道如何预防,泄漏会频繁出现,它会以微妙而危险的方式破坏你的模型。所以,这是数据科学家实践中最重要的概念之一。
本文为kaggle机器学习中级课程 第六部分XGBoost--The most accurate modeling technique for structured data.在本教程中,您将学习如何使用渐变增强构建和优化模型。该方法在许多Kaggle竞赛中占据主导地位,并在各种数据集上获得最先进的结果。
排列重要性非常重要,因为它创建了简单的数字度量来查看哪些特征对模型重要。这有助于我们轻松地比较特性,并且您可以向非技术人员展示结果图。但它并没有告诉你每个特性的重要性。如果一个特征具有中等排列重要性,那可能意味着它具有中等排列重要性对一些预测有很大影响,但总体上没有影响,或者所有预测的中等效应SHAP总结图可以让我们鸟瞰特征的重要性和驱动因素。我们将浏览一个足球数据的示例图:这张图由许多点组成。垂
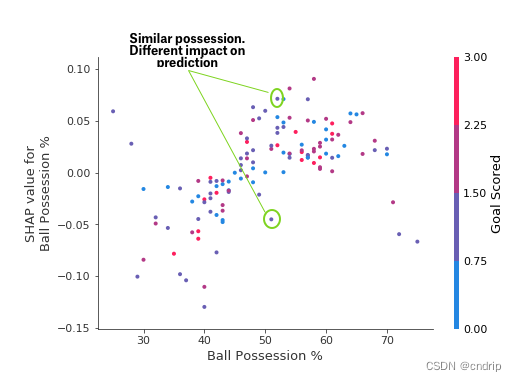
部分依赖图 --每个特征怎么样影响预测结果?像排列重要性一样,部分依赖图是在模型拟合后计算的。我们将使用拟合模型来预测我们的结果(他们的球员赢得“全场最佳球员”的概率)。但是我们**反复改变一个变量的值**来做出一系列的预测。如果球队只有40%的控球率,我们就能预测结果。然后我们预测,他们有50%的几率拿球,然后再预测60%,等等...... 我们追踪预测结果(在纵轴上),当我们从小的控球值移动到
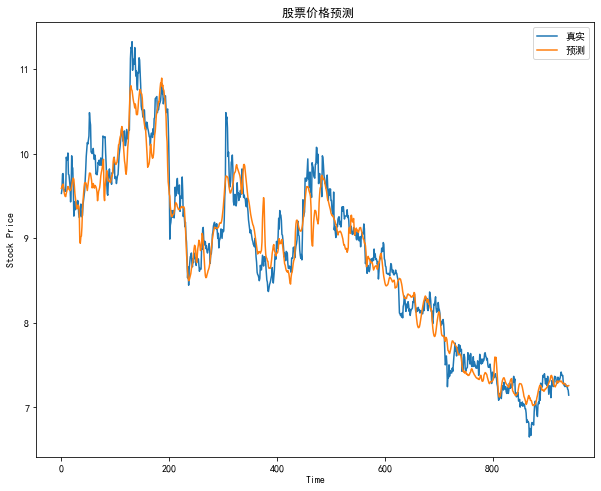
前一章节,已作随机森林来预测股票价格,也是一种比较常见的方法,本章基于深度学习算法来处理时间序列,来预测股票未来的价格。LSTM是一种特殊类型的循环神经网络(RNN),在自然语言处理和时间序列数据分析等任务中取得了显著成果。LSTM通过处理序列数据中的长期依赖关系,能够更好地捕捉时间序列数据的特征和模式。这使得它成为预测股票价格这类时间相关数据的有力工具。关于LSTM 在之前的文章中也略作介绍。我
本文 Keras 入门教程第四部分,本节利用卷积神经网络(CNN),对手写数字数据集 MNIST 做多分类建模。
前一章节,已作随机森林来预测股票价格,也是一种比较常见的方法,本章基于深度学习算法来处理时间序列,来预测股票未来的价格。LSTM是一种特殊类型的循环神经网络(RNN),在自然语言处理和时间序列数据分析等任务中取得了显著成果。LSTM通过处理序列数据中的长期依赖关系,能够更好地捕捉时间序列数据的特征和模式。这使得它成为预测股票价格这类时间相关数据的有力工具。关于LSTM 在之前的文章中也略作介绍。我
本文为kaggle 深度学习初级课程 第一部分 A Single Neuron --Learn about linear units, the building blocks of deep learning. 本节介绍什么是深度学习?以线性单位示例!你就要学会开始构建自己的深度神经网络所需的一切。