- @AggressiveYu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在深度强化学习(Deep RL)的浩瀚星空中,算法多如牛毛:DQN、DDPG、A3C、SAC......但如果你问任何一位资深的算法工程师:“如果我只想快速把一个新环境跑通,或者要做 RLHF(人类反馈强化学习)来训练大语言模型,我该选哪个算法?”答案几乎永远是同一个:PPO (Proximal Policy Optimization)。
最后,再来一轮 RL。但这次不仅是为推理(Math/Code),还加入了对齐人类偏好(Helpfulness/Harmlessness)。只看最后的 Summary 有没有用。检查整个 CoT 和 Summary 也就是所谓的安全性检查。
大型语言模型(如GPT-4)已经能够通过“思维链”的方式进行多步推理。然而,它们仍然经常在推理过程中犯下不易察觉的逻辑错误(即“幻觉”)。一个最终答案正确,但推理过程错误的解决方案是不可靠的。

它挑战了西方哲学长久以来“重精神、轻肉体”的传统。
混合精度训练(Mixed Precision Training)是现代深度学习(特别是大模型训练)的基石。如果不理解它,就无法真正理解为什么现在的显卡(如 H100, A100)要这样设计,也无法理解大模型训练中的显存优化技巧。
当前的基座模型其实已经足够聪明。它们在预训练阶段就吞噬了人类几乎所有的知识。强化学习(RLHF)及其变体,本质上并不是在教大模型‘学习新知识’,而是像一个极其高明的采访者,把模型脑子里本来就有的东西,以人类最喜欢的格式、最严密的逻辑‘引诱’出来。因此,在很多场景下,我们并不总是需要盲目追求更大参数的模型。参数少不等于性能弱!一个参数量适中、但经过极高标准优化(如 KTO、PRM 或极致的规则驱动
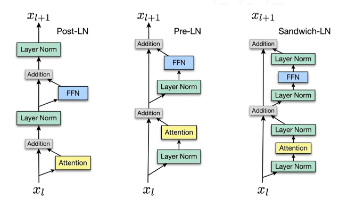
对比分析 Layer Norm、RMSNorm、DeepNorm 的数学原理与核心差异,并探讨 Post-Norm、Pre-Norm 与 Sandwich-Norm 对深层网络训练稳定性的影响。
在进入 EM 算法之前,我们必须先把脚下的土地踩实。这就意味着我们需要回到概率模型、极大似然估计这些最基本的概念,然后亲眼看看,为什么隐变量的出现会让原本优美的数学框架突然变得棘手。你将会发现,正是这个「和对数」的障碍,才催生了 EM 算法那巧妙的策略。
LangChain 是一个开源框架,专门用于帮助开发者更轻松、高效地构建基于大型语言模型(LLMs)(如 ChatGPT、Gemini、Claude 等)的应用程序。如果把大语言模型比作一个非常聪明但被关在房间里的大脑(它拥有海量的静态知识,但无法获取实时信息,也不能直接操作电脑),那么 LangChain 就是为这个大脑装上“眼睛”、“手脚”和“记忆”的工具箱。
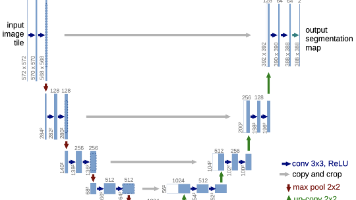
U-Net 是一个非常经典且极其重要的卷积神经网络(CNN)架构。它最初是为了生物医学图像分割而设计的,但由于其特别的设计,如今已经成为各种图像分割任务乃至 AI 图像生成模型(如 Stable Diffusion)的核心组件。