




- @shebao3333
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Spring AI为AI提供了统一接口。它将LLM当作数据库来对待——你可以连接它、查询它,并将它抽象化。关键优势提供商可移植性:编写一次代码;通过更改属性文件即可从OpenAI切换到Azure或本地Ollama实例。Spring原生:它感觉就像Spring。如果你了解Service和,你已经掌握了Spring AI的80%。

大多数智能体的记忆问题不如策略问题严重。它们要么在回合之间什么都不记住,要么试图记住所有内容,然后把所有内容都塞回提示中,希望模型能够理清头绪。这导致交互感觉通用,从嘈杂的上下文中产生幻觉,并增加延迟和成本。人类的工作方式明显不同。在当下,我们携带丰富的上下文,比如谁说了什么,房间里的气氛,以及我们的感受。随着时间的推移,这些细节会消失,剩下的是对发生了什么、对方喜欢或不喜欢什么的粗略总结,以及下

有时一个小模型就能解决问题。而且你并不总是需要 GPU。有理由直接在 CPU 上运行"工具"任务。有时你根本无法拥有 GPU。或者你想保持数据本地化。或者只是想保持架构简单。这就是发挥作用的地方。它使你能够在想要的地方运行模型:如果有 GPU 就用 GPU,没有就用 CPU。所有这些都不需要更改一行代码。在这篇文章中,我将展示它如何工作,包括在上托管你的模型。你可以在存储库中找到所有示例代码。

在这篇文章中,你将(没有 LangChain,没有框架),使用一个真正有效的。

Claude Code 2.1 的发布标志着我们对 AI agent 开发思考方式的根本转变。表面上看来,这个版本带来了三个增量功能:技能热重载、生命周期勾子和分叉子代理;但实际上,它代表的意义更为深远。这让 Claude Code 从一个复杂的终端代码助手转变为一个完整的。这不是夸张。在 2.1 版本中,开发者可以仅使用 Markdown 文件、YAML 前置元数据和 shell 脚本来构建。无

在过去,我广泛撰写了各种新技术,这些技术已经开始重塑今天的劳动力,提供了前所未有的自动化潜力,威胁的工作比我们几年前预期的要多。如果您回想起过去一两年,以下是一些此类技术,当然还有来自主要科技公司或创新初创公司的更多技术。计算机使用(Computer Use)在大约两年前就开始了,并且能够在沙盒环境中自主地运行整个计算机来完成您在 PC 上可以完成的任何任务。当时令人难以置信(感觉像 10 年前)

如果你每月为五个不同的 AI 订阅支付 20 美元,一年就是 1200 多美元,而在底层技术每天都在变得更便宜的情况下,这很难证明其合理性。搜索"免费 AI 工具"的问题是,结果通常会指向有限的陷阱,那些网页应用会让你生成两张模糊的图片后索要你的信用卡信息。但这并不是这个清单的内容。下面的工具是与 ChatGPT Plus、Midjourney 和 ElevenLabs 等软件的合法替代品。它们之

今天,越来越多的人在网上搜索东西时使用 AI 聊天机器人,而不是"谷歌一下"。超过 30% 的 Z 世代和千禧一代用户现在更喜欢使用 ChatGPT、Gemini、Perplexity 和 Google AI 概览等 AI 工具进行研究 和决策,而不是传统的搜索引擎。这不是典型的 SEO。人们称之为生成引擎优化,或简称为 GEO。GEO 是构建在线内容结构,使其能够被 AI 驱动的搜索引擎发现、引

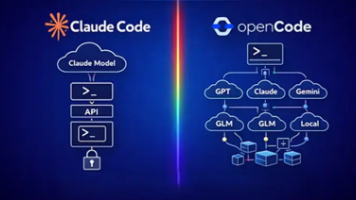
大多数 OpenCode 和 Claude Code 之间的比较都错过了重点。讨论通常集中在哪个工具写更清晰的代码,哪个更快,或者哪个终端体验感觉更好。这些是表面层面的差异。真正的差异在下面。Claude Code 是一个紧密集成的系统。它提供精心策划的体验,具有强大的默认值、原生订阅支持和可预测的行为。一切都在单个生态系统中工作。OpenCode 采取了根本不同的路径。它将代理与模型层解耦。它将
BIM 建筑师的角色已经发生了转变。在 2026 年,问题不再是是否应该使用 AI,而是如何在不干扰建筑信息建模所需精度的情况下集成它。当今最有效的工具并不是试图取代建筑师;相反,它们自动化摩擦点 - 可视化、文档编制、场地分析和可行性 - 允许 BIM 模型保持单一事实来源。本指南评估了五种成熟的 AI 工具,它们自然地融入专业 BIM 工作流程,从实验性技术转向可靠的日常驱动程序。
