- @pk3725069
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍在阿里云平台一键部署开源AI助手OpenClaw的全流程,包含四大核心内容:(1)云端部署相比本地部署的稳定性、维护便利性等优势;(2)轻量应用服务器选购建议及支付流程;(3)控制台配置三大关键步骤:端口放行、APIKey配置及WebUI测试;(4)QQ/飞书等主流IM工具的集成方法。通过标准化镜像部署和可视化操作,用户无需代码基础即可快速搭建7×24小时在线的AI助手服务。
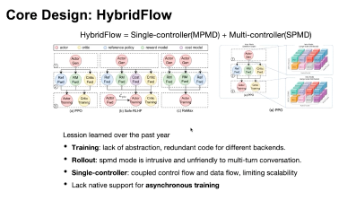
veRL框架:面向强化学习的高效混合编排系统 veRL是一个专为强化学习(RL)设计的创新框架,通过独特的Hybrid Flow架构解决了传统RL框架在多阶段异构工作流中的编排难题。该框架采用单控制器(Single-controller)与多控制器(Multi-controller)相结合的混合模式,实现了全局工作流编排与组件内分布式计算的高效统一。 核心架构包含四大组件:Model Engine
摘要:本文介绍在阿里云平台一键部署开源AI助手OpenClaw的全流程,包含四大核心内容:(1)云端部署相比本地部署的稳定性、维护便利性等优势;(2)轻量应用服务器选购建议及支付流程;(3)控制台配置三大关键步骤:端口放行、APIKey配置及WebUI测试;(4)QQ/飞书等主流IM工具的集成方法。通过标准化镜像部署和可视化操作,用户无需代码基础即可快速搭建7×24小时在线的AI助手服务。
摘要:本文介绍在阿里云平台一键部署开源AI助手OpenClaw的全流程,包含四大核心内容:(1)云端部署相比本地部署的稳定性、维护便利性等优势;(2)轻量应用服务器选购建议及支付流程;(3)控制台配置三大关键步骤:端口放行、APIKey配置及WebUI测试;(4)QQ/飞书等主流IM工具的集成方法。通过标准化镜像部署和可视化操作,用户无需代码基础即可快速搭建7×24小时在线的AI助手服务。
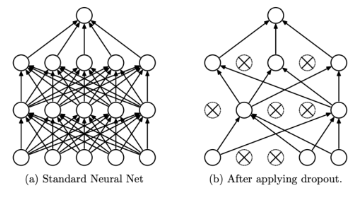
Dropout机制摘要 Dropout是一种有效的神经网络正则化技术,通过随机"丢弃"部分神经元(概率p)来防止过拟合。其核心原理包括:1)作为模型集成方法,训练多个子网络;2)减少神经元依赖,增强特征鲁棒性。训练时需引入1/(1-p)的缩放因子保持期望一致,但会增大方差。AlphaDropout通过仿射变换调整丢弃值,保持数据统计特性。这种机制简单高效,能显著提升模型泛化能力
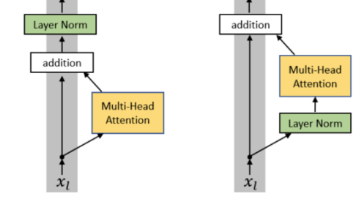
文深入探讨了神经网络中的归一化技术及其应用机制。首先指出强行归一化可能削弱模型表达能力,导致激活函数进入饱和区,引发梯度消失问题。随后详细对比了三种主流归一化方法:BatchNorm(按特征维度归一化)、LayerNorm(按样本内部归一化)和RMSNorm(仅计算均方根),通过数学公式和表格示例阐明其计算差异。
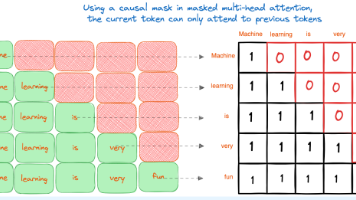
摘要:Transformer解码器在自回归语言建模中,通过KV缓存机制优化推理效率。当前token的Query(Q)实时计算,而Key(K)和Value(V)则缓存历史信息,确保模型仅基于已生成内容预测下一token。这种设计避免了重复计算,将时间复杂度从O(t²)降至O(t),同时保持因果性——通过掩码防止未来信息泄露。KV缓存使GPT等模型能高效生成连贯文本,每次只需计算当前Q与历史K的点积,
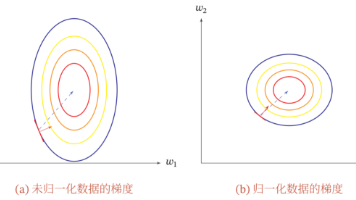
摘要 归一化技术在Transformer等深度学习模型中起着关键作用,它通过将不同特征缩放到相同尺度来解决梯度消失和训练不稳定的问题。本文通过房价预测的实例,生动解释了未归一化数据导致的问题:特征尺度差异造成梯度更新失衡,大数值特征更新剧烈而小数值特征更新缓慢,形成椭圆形损失等高线,严重影响收敛效率。同时分析了梯度下降原理,展示了未归一化数据如何使激活函数进入饱和区,引发真正的梯度消失。最后阐明归
模型参数初始化是神经网络训练的重要第一步,直接影响模型性能和收敛速度。固定权重初始化可能导致收敛缓慢,而固定方差初始化需要平衡方差大小以避免梯度消失或信号消失。Xavier初始化根据神经元数量和激活函数类型自动调整方差,保持数据在传播过程中的稳定性。Kaiming初始化则针对ReLU函数的特性进行优化。不同激活函数(如Tanh、Sigmoid)需要不同的方差补偿策略。预训练权重(如BERT)通过大
本章系统性地解析了Transformer模型的核心架构与关键机制,揭示了其作为现代大语言模型基石的深层原理。Transformer由谷歌于2017年在《Attention Is All You Need》论文中提出,凭借其完全基于注意力机制的创新设计,彻底改变了自然语言处理领域的格局,成为BERT、Llama等主流模型的核心组件。