- @qq_36671160
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今日候选池 91 篇,硬过滤 + LLM 打分后通过评估 16 篇,精选 Top-10,另列 6 篇速览

今日候选池 85 篇,硬过滤 + LLM 打分后通过评估 11 篇,精选 Top-10,另列 1 篇速览

今日候选池 89 篇,硬过滤 + LLM 打分后通过评估 13 篇,精选 Top-10,另列 3 篇速览

多智能体 LLM 往往靠自然语言通信,虽然直观,但会带来额外 token 生成、prefill 开销和 KV cache 内存负担。本文提出 TFlow(Thought Flow),将发送方的隐藏状态编译为接收方专属的瞬时低秩 LoRA 权重扰动,而不是写入上下文。该方法在推理时实现实例级适配,不永久改模也不扩展文本上下文。用 3 个 Qwen3-4B agent 实验显示,TFlow 相比单一接

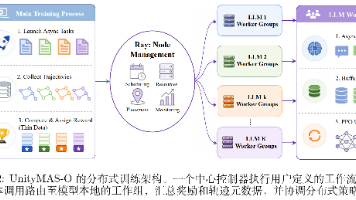
现有 RL 框架(verl、OpenRLHF 等)本质上还是面向具体的策略模型做优化,工作流编排被当作环境搭建的一部分,使得每个多智能体系统都需要手工编排,训练难度较大,不同系统也难以做公平比较。UnityMAS-O 实现了一套真正面向多智能体工作流的训练流程,支持自定义的角色设置、模型拓扑结构,在多种任务和实验设置下都拿到了显著提升
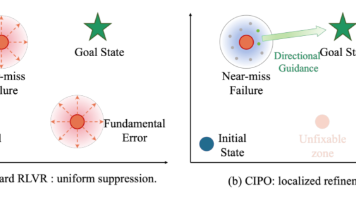
RLVR 中失败轨迹被统一惩罚是巨大的信息浪费。CIPO 通过纠错重放,让模型在看到自己错误的条件下重新生成答案,天然区分不同失败模式并提供差异化学习信号,无需任何外部标注
对 Claude Code 泄漏源码的深度分析

多智能体 LLM 往往靠自然语言通信,虽然直观,但会带来额外 token 生成、prefill 开销和 KV cache 内存负担。本文提出 TFlow(Thought Flow),将发送方的隐藏状态编译为接收方专属的瞬时低秩 LoRA 权重扰动,而不是写入上下文。该方法在推理时实现实例级适配,不永久改模也不扩展文本上下文。用 3 个 Qwen3-4B agent 实验显示,TFlow 相比单一接
本文提出嵌入式语言流 ELF(Embedded Language Flows),将 diffusion/flow 模型直接用于连续 embedding 空间的语言生成。与主要在离散 token 上运作的现有 DLM 不同,ELF 几乎全程停留在连续空间,仅在最后一步借助共享权重网络映射为离散 token,因此能较容易迁移图像 diffusion 中成熟技巧,如 classifier-free gu

结合预训练的规模优势与强化学习的决策优势