- @2402_88472386
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
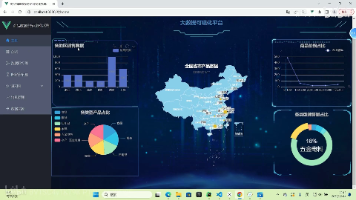
【摘要】本项目开发了一套基于DeepSeek-V3大模型的微博舆情智能分析系统,通过Django框架构建后端服务,采用Cursor工具进行AI辅助开发,并部署于Zeabur云平台。系统创新性地融合了AIGC技术与云原生架构,实现微博数据的深度语义分析(情感识别、主题抽取等)和智能可视化呈现(知识图谱、趋势图等)。项目兼具技术前瞻性与实用价值,为企业品牌管理、政府舆情监测提供实时、多维的决策支持,同
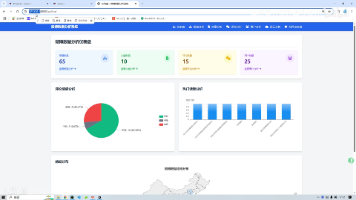
本文介绍了一个基于大数据和AI技术的智能农业分析系统。项目整合Spark、Hadoop和DeepSeek-R1等技术,构建了多模态数据处理平台,实现农作物产量预测和订单分析。系统采用TensorFlow深度学习框架,结合LSTM-GRU混合神经网络模型,并开发了动态可视化模块展示分析结果。创新点包括多模态数据融合和自适应可视化决策引擎,支持千万级数据实时处理。项目提供Web端交互界面,涵盖农产品分
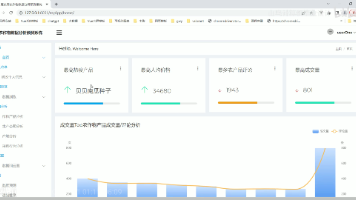
本文介绍了一个基于Python的微博舆情分析系统。项目采用Scrapy-Redis分布式爬虫采集数据,运用SnowNLP情感分析算法处理文本,结合Flask+Vue.js实现前后端分离架构。系统创新性地融合了规则引擎优化短文本分析,提供热词统计、地域分布等多维度可视化功能。开发过程遵循敏捷迭代,采用MySQL存储、Redis缓存等技术栈,确保系统高性能和可扩展性。项目资料包含完整源码、文档和教学视
前端技术:后端:数据库:MySQL、Hive可视化:Echarts推荐算法:基于用户协同过滤算法(User-Based Collaborative Filtering, UserCF)算法原理基于用户协同过滤算法的核心是通过寻找与目标用户兴趣相似的其他用户,将这些相似用户喜欢的物品推荐给目标用户。具体步骤包括:收集用户行为数据,计算用户之间的相似度(如余弦相似度),选取与目标用户最相似的用户集合,
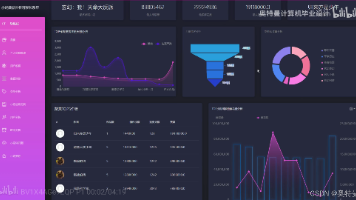
后端:Django大数据处理框架:数据存储:MySQL编程语言:Python自然语言处理:随机森林算法数据可视化:Echarts数据采集:Requests爬虫。
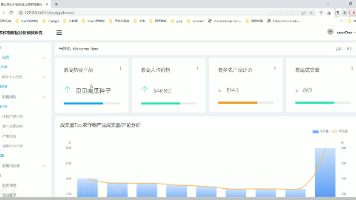
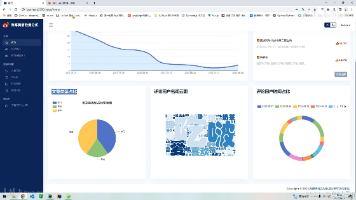
本文介绍了一个基于Django框架的智慧旅游分析推荐系统。该系统整合MySQL数据库、Scikit-learn机器学习库和数据可视化技术,实现了旅游数据的多维度分析、个性化推荐和直观展示。系统包含用户交互、数据管理、分析可视化和智能推荐四大功能模块,通过协同过滤算法提供个性化景点推荐,并运用地图、词云等可视化方式呈现数据。创新点在于技术融合、推荐与分析协同、可视化呈现和功能场景设计,既满足游客需求
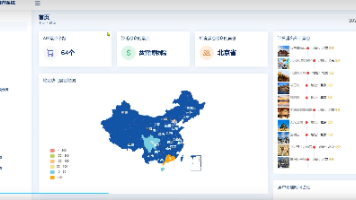
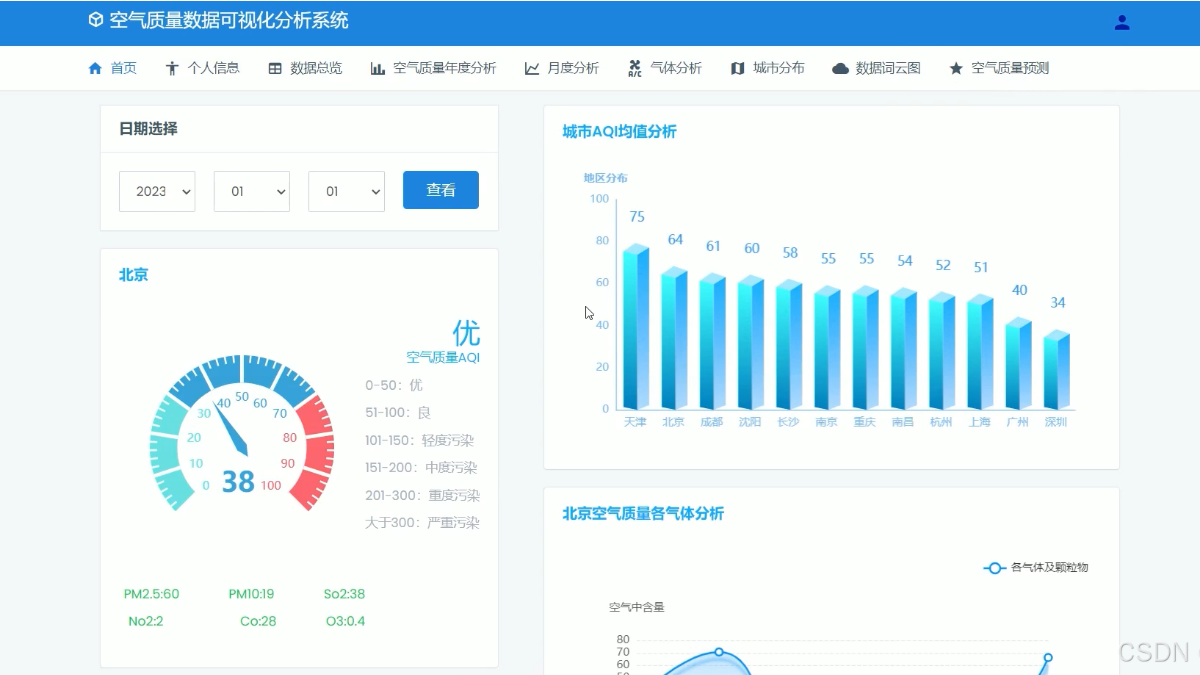
二、数据分析方法创新 采用多种数据分析方法,如时间序列分析、空间分析、关联分析等,全面深入地挖掘空气质量数据的潜在信息。从多个数据源(如空气质量监测站、气象部门、污染源企业等)采集空气质量相关数据,包括空气质量指标(如 PM2.5、PM10、SO₂、NO₂ 等)、气象数据(如温度、湿度、风速、风向等)和污染源数据(如工业排放、交通尾气等)。基于历史数据和分析结果,建立空气质量预测模型。分析空气质量
摘要:本项目构建了一个基于Spark、Hadoop和Hive的二手交易平台大数据分析与推荐系统。通过JS逆向技术采集咸鱼平台数据,利用Hadoop分布式存储和Hive数据仓库处理PB级异构数据。系统采用Spark进行多维度数据分析,并基于协同过滤算法实现个性化商品推荐。创新点包括JS逆向数据采集、Spark分布式计算优化以及针对二手商品特点的特征工程。项目提供完整的大数据全栈解决方案,涵盖数据采集
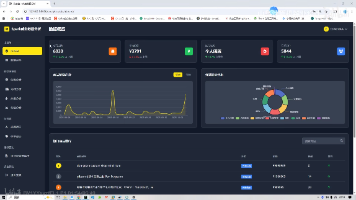
本文介绍了一个基于Spark+Hive的大数据招聘分析系统,主要包含数据采集存储、预处理、分析预测、智能推荐和可视化展示等功能模块。系统运用多元线性回归算法进行岗位需求预测,采用ItemCF协同过滤算法实现个性化职位推荐,通过Spark框架进行高效数据分析。该项目能提升企业招聘效率,优化人才规划,并为求职者提供精准职位匹配。开发技术包括Django后端、MySQL数据库和Echarts可视化等。文
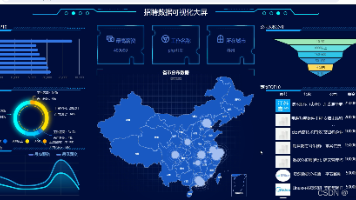
采用Stacking集成学习策略,分层融合时序模型与树模型的优势:LSTM神经网络:捕捉销量序列的长期依赖关系,通过门控机制过滤噪声,适应促销活动的滞后效应。XGBoost模型:处理结构化特征(价格、品类、竞品数据),挖掘特征间非线性关系与高阶交互效应。Prophet模型:解析节假日、平台大促等外部事件影响,内置变点检测适应突发波动。元模型层:使用线性回归动态加权基模型输出,通过交叉验证确定最优权