- @weixin_44492824
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
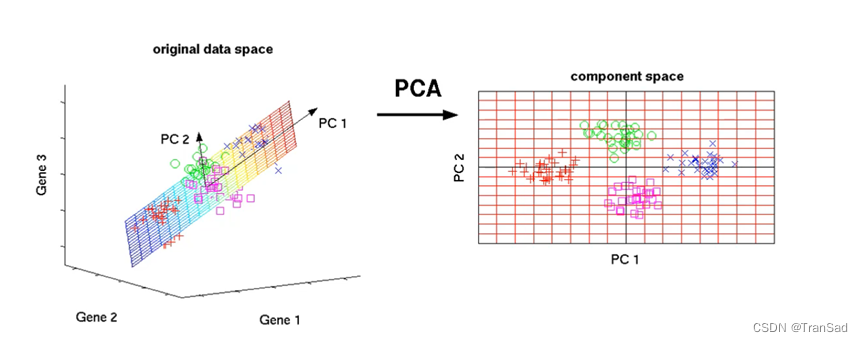
PCA全称是Principal Component Analysis,即主成分分析。它主要是以“提取出特征的主要成分”这一方式来实现降维的。介绍PCA的大体思想,先抛开一些原理公式,如上图所示,原来是三维的数据,通过分析找出两个主成分PC1和PC2,那么直接在这两个主成分的方向上就可以形成一个平面,这样就可以把我们三位的样本点投射到这一个平面上(如右图)。那么此时的PC1和PC2都不单单是我们的其
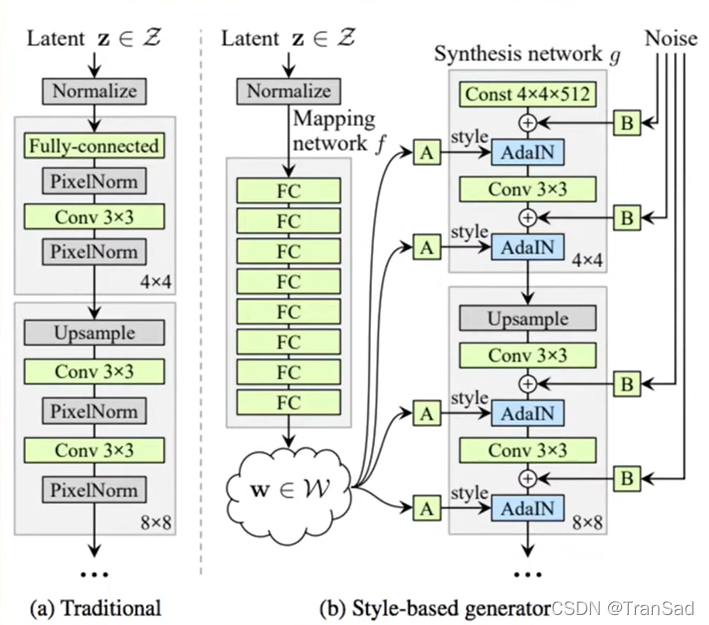
Stylegan的一个非常实用的人脸生成模型,它可以通过控制参数来控制人脸生成的样式,包括五官、发型乃至人种肤色。这篇文章大致总结一下Stylegan的一些原理和要点。下图(右边)是stylegan生成器的模型结构:映射网络Mapping Network从上图可以看到,传统的生成器的输入就是直接用高斯分布下512维的随机向量。而Stylegan中使用了8层全连接网络Mapping network来
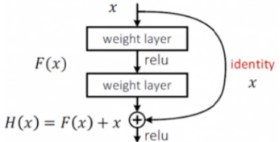
ResNet简单介绍ResNet是15年提出的经典网络了。在ResNet提出之前,人们发现当模型层数提升到一定程度后,再增加层数就不再能提升模型效果了——这就导致深度学习网络看似出现了瓶颈,通过增加层数来提升效果的方式似乎已经到头了。ResNet解决了这一问题。ResNet的核心思想就是引入了残差边。即一条直接从输入添加到输出的边。这样做有什么用处呢?可以这样理解:假如新加的这些层的学习效果非常差
这篇只针对目标格式为yyyy-MM-dd HH:mm:ss的,有其它需求的就不用看啦~今天被提了个要求要统一爬取过来的某日期字段为yyyy-MM-dd HH:mm:ss格式。一看才发现原来存储的日期格式五花八门的,几乎什么样子的都有,所以下面我对不同情况用不同的方法去处理。发现所有数据主要就两大类,做个总结:一、原数据是其他五花八门的时间格式,如2021,2016-02-24,2016/02/24

方向导数接着偏导数的基础,我们可以引出方向导数。方向导数和偏导数的区别就是:方向不同。仅此而已。我们常说的偏导数无非就是对x轴求偏导,对y求偏导。而方向导数则是对x轴与y轴之间的某一新方向求导数。还是用一下上次的图,这里我在x轴和y轴之间的平面上自己画了一个方向,并且与x轴夹角为α。那么我们的z既然可以对x方向或y方向求偏导,自然也能对我新画的这个方向求“偏导”,这个“偏导”就是方向导数。设这个新
核函数是我们处理数据时使用的一种方式。对于给的一些特征数据我们通过核函数的方式来对其进行处理。我们经常在SVM中提到核函数,就是因为通过核函数来将原本的数据进行各种方式的组合计算,从而从低维数据到高维数据。比如原来数据下样本点1是x向量,样本点2是y向量,我们把它变成e的x+y次方,就到高维中去了。把数据映射到高维在我们直观上理解起来是很难的,其实也并不用深刻理解,因为做这些的目的只是为了让机器去
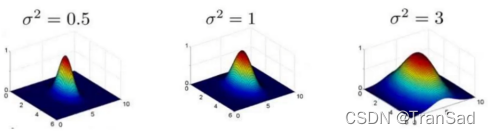
今天想分享一个人工智能中的中文屋论证(也叫汉字屋,Chinese room)。什么是中文屋论证呢,我们知道图灵测试是判断是机器否是人工智能的公认标准。我先说图灵测试,知道了图灵测试就很好理解汉子屋论证了。图灵测试非常简单,就是图灵提出来的,判断一个机器是不是具有智能,就是在你和机器对话以后(前提是你不知道他是机器),你分辨不出来他是真人还是机器——如果你无法判断,就说明这个机器可以算做人工智能。图

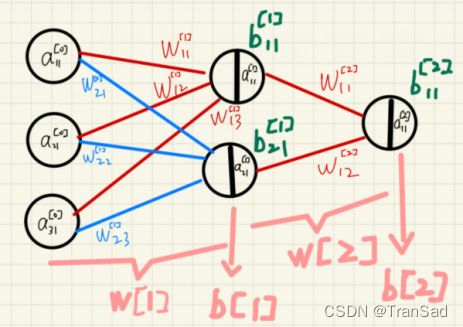
我们都知道神经网络中每一个隐层都有参数w和b,输入x首先要乘以w再加上b,最后传入激活函数就会得到这个隐层的输出。——但是,具体w是什么形状、它和x怎么乘、加上的b是在哪里之类的一直不是很清晰,因为在一些算法讲义里这一块一讲起来就容易用各种符号,看起来很复杂(虽然它并不难),而且这方面细节也并不耽误我们去定义和使用神经网络,所以就似懂非懂了。但后来在学习推荐系统、word2vector之类的时候,
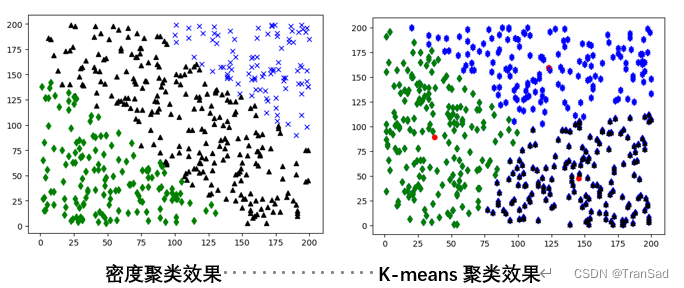
密度聚类,也被称为CFDP(Clustering by fast search and find of density peaksd)。密度聚类的作用和Kmeans聚类差不多,可以将一堆数据分成若干类。“密度聚类”,顾名思义其实就是根据点的密度进行归类,比如说某一处点特别密集,那么这一块会偏向归为一类。这篇文章就具体整理一下密度聚类的原理与实现。假设在一个二维平面中有若干个点,我们想要对这些点进行
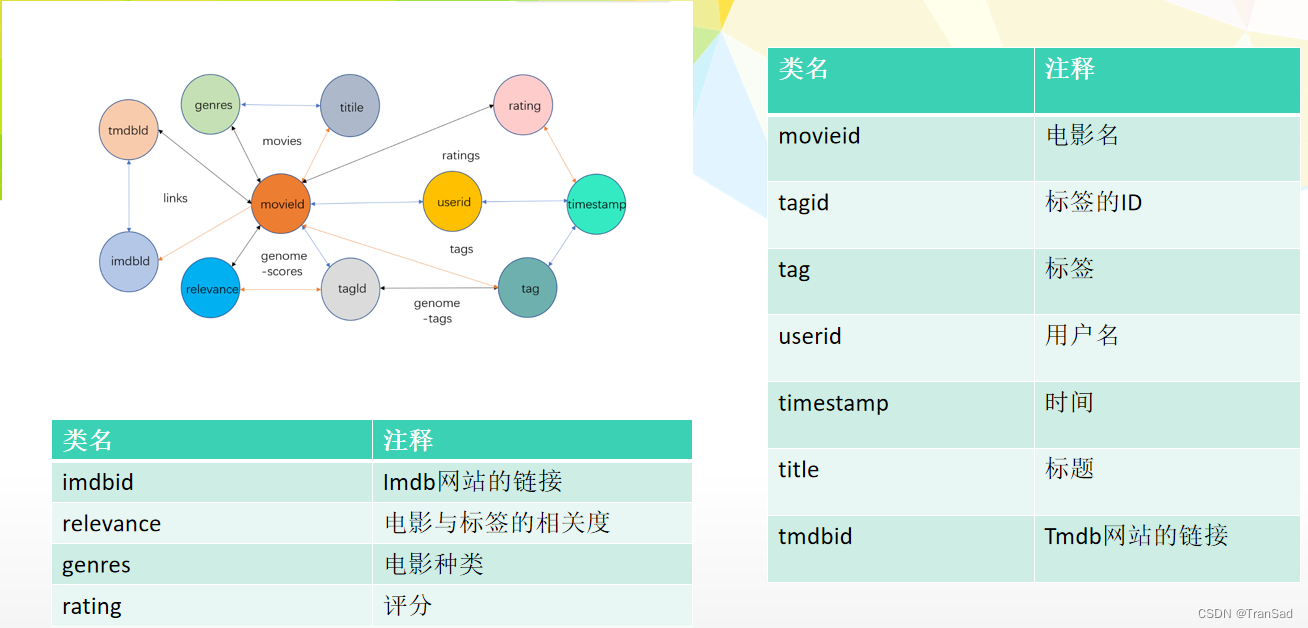
这篇文章记录一下我之前做过的通过Spark与Hive实现的基于协调过滤的电影推荐。这篇文章只能提供算法、思路和过程记录,并没有完整的代码,仅尽量全面地记录过程细节方便参考。数据集是从下面这个地址下载的,数据集主要内容是关于用户对电影的评分、评价等。免费数据集下载(很全面)_浅笑古今的博客-CSDN博客_数据集下载网站图1.1 数据获取我选取的几个数据集表格如下:图1.2 数据表格图1.3 rati