登录社区云,与社区用户共同成长
邀请您加入社区
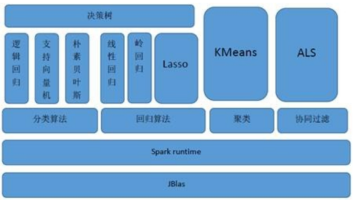
它提供了一组丰富的机器学习算法和工具,可以用于数据预处理、特征提取、模型训练和评估等任务。MLlib是基于Spark的分布式计算引擎构建的,可以处理大规模数据集,并利用分布式计算的优势来加速机器学习任务的执行。MLlib的设计目标是将机器学习算法与Spark的分布式计算框架无缝集成,以提供高性能和可伸缩性的机器学习解决方案。分类算法:MLlib提供了多种分类算法,如逻辑回归、决策树、随机森林、梯度
1.背景介绍机器学习是一种通过计算机程序自动化地学习和改进自身的过程,它可以应用于各种领域,如图像识别、自然语言处理、推荐系统等。Java是一种流行的编程语言,它的强大性能和丰富的生态系统使得Java成为机器学习开发的理想选择。本文将介绍如何使用Java进行机器学习开发,具体介绍MLlib和DL4J这两个主要的机器学习框架。1. 背景介绍1.1 MLlibMLlib是Apache ...
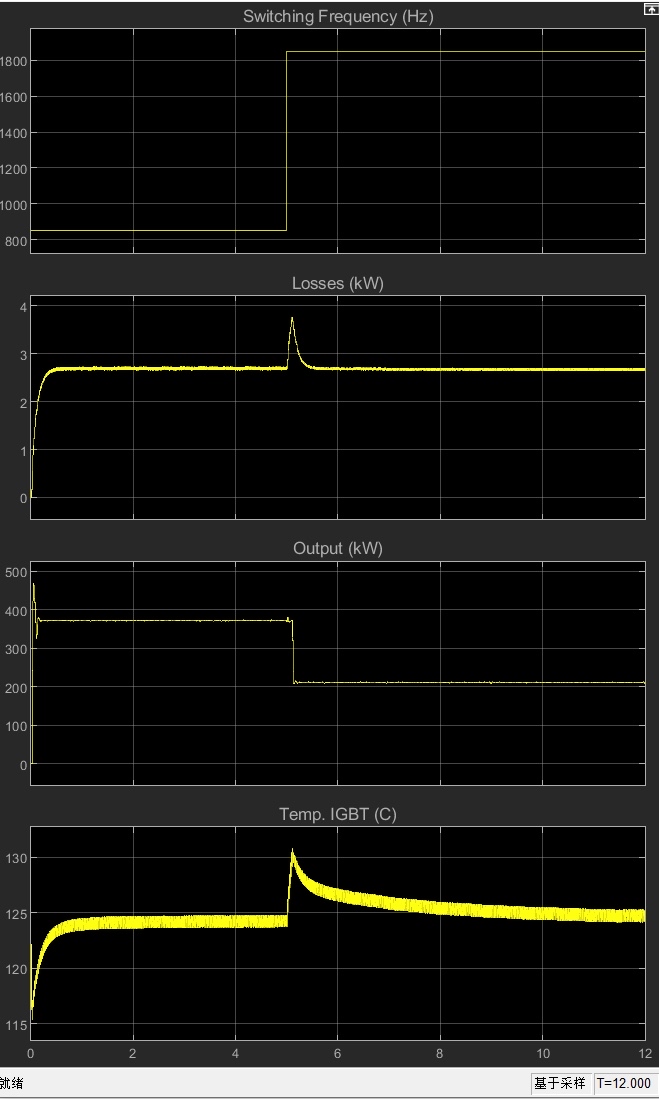
跑完仿真后,在MATLAB里画个三维曲面图,输出功率随开关频率的变化趋势一目了然。通过这种损耗-热耦合仿真,能提前发现哪些IGBT会成散热瓶颈,这对三电平拓扑的均流设计特别重要。后来改用分布参数模型,用thermal ports直接耦合损耗源,仿真结果明显更贴近红外热像仪的实测数据。之前掉过坑里,直接用datasheet的Eon/Eoff参数做计算,结果仿真和实测差了30%。最近在实验室折腾这个模
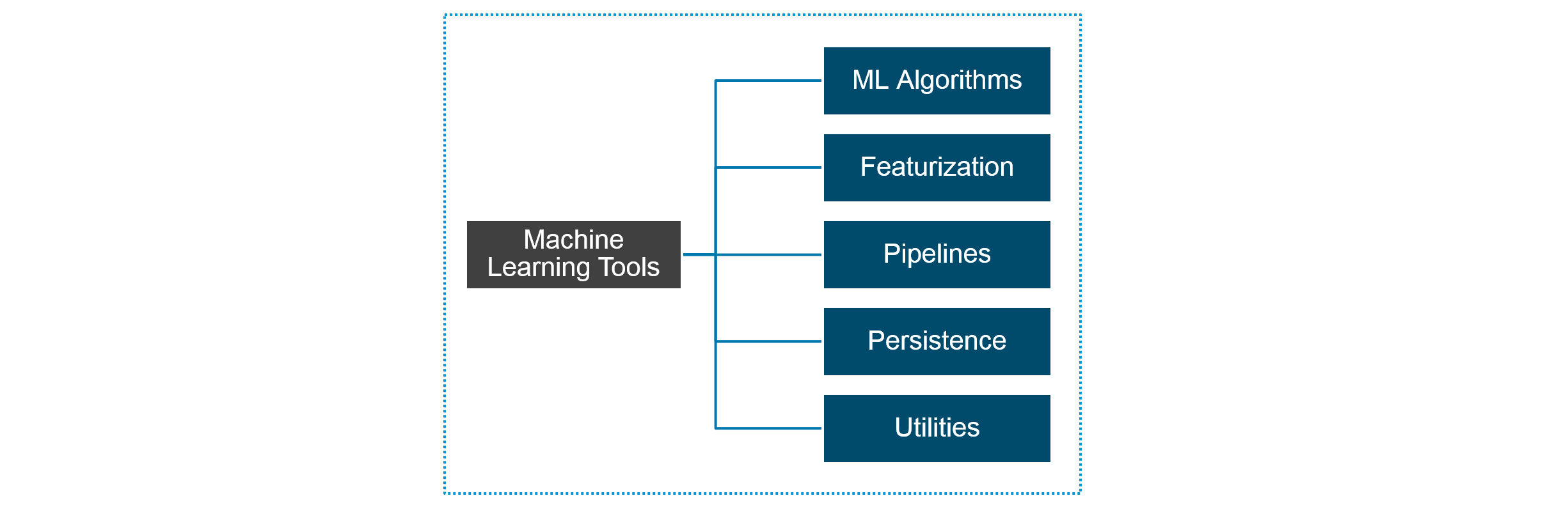
MLlib是Spark的机器学习(ML)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。它提供了常见的机器学习算法和工具,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
毕竟,数学模型的理想条件和实际工况之间,差着十个新手工程师的血泪史呢。跑完仿真别急着收工,盯着波形看三个点:负载突变时的恢复时间别超过5个开关周期,输出电压纹波得压在1%以内,最关键是动态响应不能有超调——这玩意儿搞电源的都懂,超调就意味着可能烧管子。这个模型直接暴露了被控对象的"脾气"——输入是占空比,输出是电容电压。从滤波器设计到建模,得到被控对象的传递函数,再根据传递函数设计pi调节器,最后
Apache Spark 已然成为大数据处理领域的一颗璀璨明星。它以其卓越的性能、易用性以及丰富的生态系统,吸引了无数开发者投身于大数据的浪潮之中。如果你正是一名向往大数据领域的开发者,或是已经涉足其中但希望更深入地掌握Spark技术,那么请跟随这篇指南,我们将以一种“糙快猛”的策略,高效开启你的大数据之旅。
摘要:本文介绍了使用Spark MLlib进行机器学习编程实践的过程。实验从adult数据集导入开始,通过PCA对6个数值型特征降维至3维,然后构建包含标签索引化、特征处理、逻辑回归和标签转换的完整机器学习流水线。实验展示了如何训练分类模型预测居民收入是否超过50K,并提供了模型评估方法。实验环境为Win10系统下的VirtualBox虚拟机运行Linux系统。
==================================================================8.1.1 什么是机器学习机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。机器学习利用数据或以往的经验,以此优化计算机程序的性能标准。机器学习强调三个关键词:算法、经验、性能从最小二乘法说起......
易于使用:提供了丰富的 API,支持 Scala、Java、Python 和 R 等多种编程语言。高度可扩展:可以处理海量数据,适用于大规模机器学习任务。丰富的算法库:支持分类、回归、聚类、降维、协同过滤等常用算法。本文详细介绍了 Spark MLlib 的功能及其应用,结合实例演示了分类、回归、聚类、降维、协同过滤等常用机器学习任务的实现过程。通过这些实例,我们可以看到 Spark MLlib
这类由Stewart平台演化而来的精密设备,每个支链都像相互纠缠的藤蔓,把六个伺服电机的转动耦合成了末端执行器的空间芭蕾。但正解才是真正的魔鬼——当六个电机停止转动时,末端的位姿就像被锁在六维迷宫里的宝藏。我们开发了基于运动连续的预测机制——用上一时刻的解作为当前迭代的初始猜测。真正玄妙的是残差函数的设计。六个约束方程不仅要描述支链长度与位姿的关系,还得处理万向节的运动约束。示教器屏幕上的位姿数据
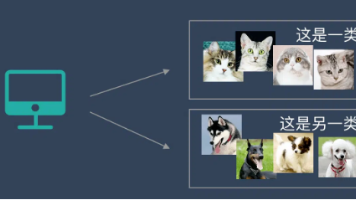
本文介绍了Unet语义分割的核心概念与应用。首先解释了语义分割的定义,即对图像每个像素进行分类并赋予语义标签,强调其与目标检测的区别在于实现像素级精确分割。重点阐述了语义分割原理:通过三维输出特征图表示不同类别位置,最后合成彩色分割图。文章还分析了语义分割的意义在于弥补CNN在位置敏感性上的不足,并列举了自动驾驶、医疗影像等典型应用场景,特别指出Unet在医学图像处理中的优势。最后提供了项目实现的
将10万张未标注的X光片输入初始模型进行预测,生成伪标签 (即模型预测的“正常”或“肿瘤”结果),仅保留模型预测置信度高的样本(例如预测概率>90%的5万张),作为“伪标注数据”加入训练集,其原理是假设模型对高置信度样本的预测基本正确,通过扩大数据量优化模型对肺部结构的理解。1000张已标注的X光片(如500张正常、500张肿瘤),用这些标注数据训练一个基础分类模型(如卷积神经网络),学习初步的肿
在处理文本数据,尤其是自然语言处理的场景中,hashingTF使用的比较多;Mllib使用hashing trick实现词频。元素的特征应用一个hash`函数映射到一个索引(即词),通过这个索引计算词频。这个方法避免计算全局的词-索引映射,因为全局的词-索引映射在大规模语料中花费较大。但是,它会出现哈希冲突,这是因为不同的元素特征可能得到相同的哈希值。为了减少碰撞冲突,我们可以增加目标特征的维..
先甩个Github地址(假装有),数据集用PeMS-BAY这种经典交通流数据,包含传感器节点和车辆速度时间序列。注意别让batch_size太大,否则显存分分钟爆炸(别问我是怎么知道的)。关键不是绝对精度,而是模型能在突发拥堵时(比如交通事故)比传统ARIMA方法更快响应——这得益于图结构的信息传递机制。这招把物理距离近的传感器强行组CP,但实际路况中可能存在"隔山打牛"的情况——这时候注意力机制
后来找了个注册表文件,双击运行就能删图标。虽说文件备注是“删除夸克网盘图标”,但实际试了下,其他网盘的图标也能删掉。打开资源管理器侧边栏,选中要删的网盘图标,点【删除选中的驱动器图标】,侧边栏的图标就能清掉,跟前面那个工具搭配用刚好互补。但我装完发现,移动云盘在“我的电脑”里硬生生多了个图标,翻遍客户端设置也没找到取消的地方,看着就碍眼。今天要说的这款“删除我的电脑网盘图标”工具,专门解决安装网盘
一、MLlib简介MLlib是一些常用的机器学习算法和库在Spark平台上的实现。MLlib是AMPLab的在研机器学习项目MLBase的底层组件。MLBase是一个机器学习平台,MLI是一个接口层,提供很多结构,MLlib是底层算法实现层。MLlib中包含分类与回归、聚类、协同过滤、数据降维组件以及底层的优化库。MLlib底层使用到了Scala书写的线性代数库Breeze,Breeze底层依赖n
本系统是一套运行于MATLAB环境下的说话人识别解决方案,核心采用梅尔频率倒谱系数(MFCC)进行语音特征提取,结合高斯混合模型(GMM)实现说话人身份建模与匹配,最终完成“多选一”式说话人辨认任务。系统遵循“数据预处理-特征提取-模型训练-识别匹配”的经典机器学习流程,支持多说话人语音数据的批量处理,可输出可视化的特征图谱与量化的识别正确率,适用于语音识别技术研究、生物认证原型开发等场景。Mat
在分布式机器学习中,框架选型需综合考虑任务类型、性能、易用性、资源管理等因素。以下是对 MLlib、TensorFlow On YARN 和 Horovod 的详细对比,帮助您根据实际需求做出决策。分析基于开源框架的公开文档和社区实践,确保真实可靠。通过以上对比,您可根据数据规模、硬件环境和任务类型做出优化选择。实践中,结合基准测试(如训练时间、资源利用率)进一步验证。以下从核心维度进行逐步分析,
摘要:本文探讨了迪拜短信接口在中东市场的关键作用,分析了当地运营商对URL审核、阿拉伯语编码和营销短信的严格限制。文章推荐了从测试到生产环境的完整接入流程,包括注册测试、网页群发工具模拟和API自动化发送,并强调了UTF-8编码、短链优化和频率控制等技术细节。最后指出迪拜短信接口需要"可控、可测、可扩展"的特性,建议开发者通过互亿无线平台快速验证和部署。
基于LQR最优控制算法实现的轨迹跟踪控制,建立了基于车辆的质心侧偏角、横摆角速度,横向误差,航向误差四自由度动力学模型作为控制模型,通过最优化航向误差和横向误差,实时计算最优的K值,计算期望的前轮转角实现轨迹跟踪,仿真效果良好,有对应的资料,包运行和。在自动驾驶领域,实现精准的轨迹跟踪控制是关键任务之一。今天来聊一聊基于LQR(线性二次型调节器)最优控制算法达成这一目标的相关内容,顺便带大家看看具
从像素级的简单操作到语义级的智能理解,图像处理技术的演进深刻地改变了我们的视觉世界。未来,随着算法的不断精进和算力的持续提升,图像处理技术必将进一步模糊物理世界与数字世界的边界,为我们带来更加沉浸和智能的视觉体验。当今的图像处理技术早已超越了“识别”的范畴,进入了“创造”的阶段。这一时期的技术是基础性的,它赋予了计算机“看见”世界的能力,但这种“看见”还停留在表层,缺乏对图像内容的深层理解。此时的
stm32f4 +dp83848 modbustcp+modbusrtu以太网驱动程序稳定版工程用的armfly例程里的tcpnet 改进加了网线断线重连 端口断开重连打包发送…可串口以太网同时通讯可最高开20个socket 例程里已开4个可以参考连续实测24小时以上上百万帧无错误dp83848 phy芯片是汽车级 工业场合要比dm9161 lan8720…更稳定可靠 客户实测像w5500这类芯片
实测下来,DMA模式比轮询稳定至少三成,特别是在电机转起来的时候。注意GP2D12的有效检测范围是10-80cm,别傻乎乎地相信8cm的标称值,那区域数据跳得跟蹦迪似的。这招够狠:先采7个值,排序后掐头去尾,中间三个取平均。先看硬件接线,三根线简单到哭:VCC接3.3V,GND接地,信号线随便找个ADC通道怼上。红外测距传感器GP2D12与STM32单片机程序,滤波算法,设计步骤和代码流程清晰非常
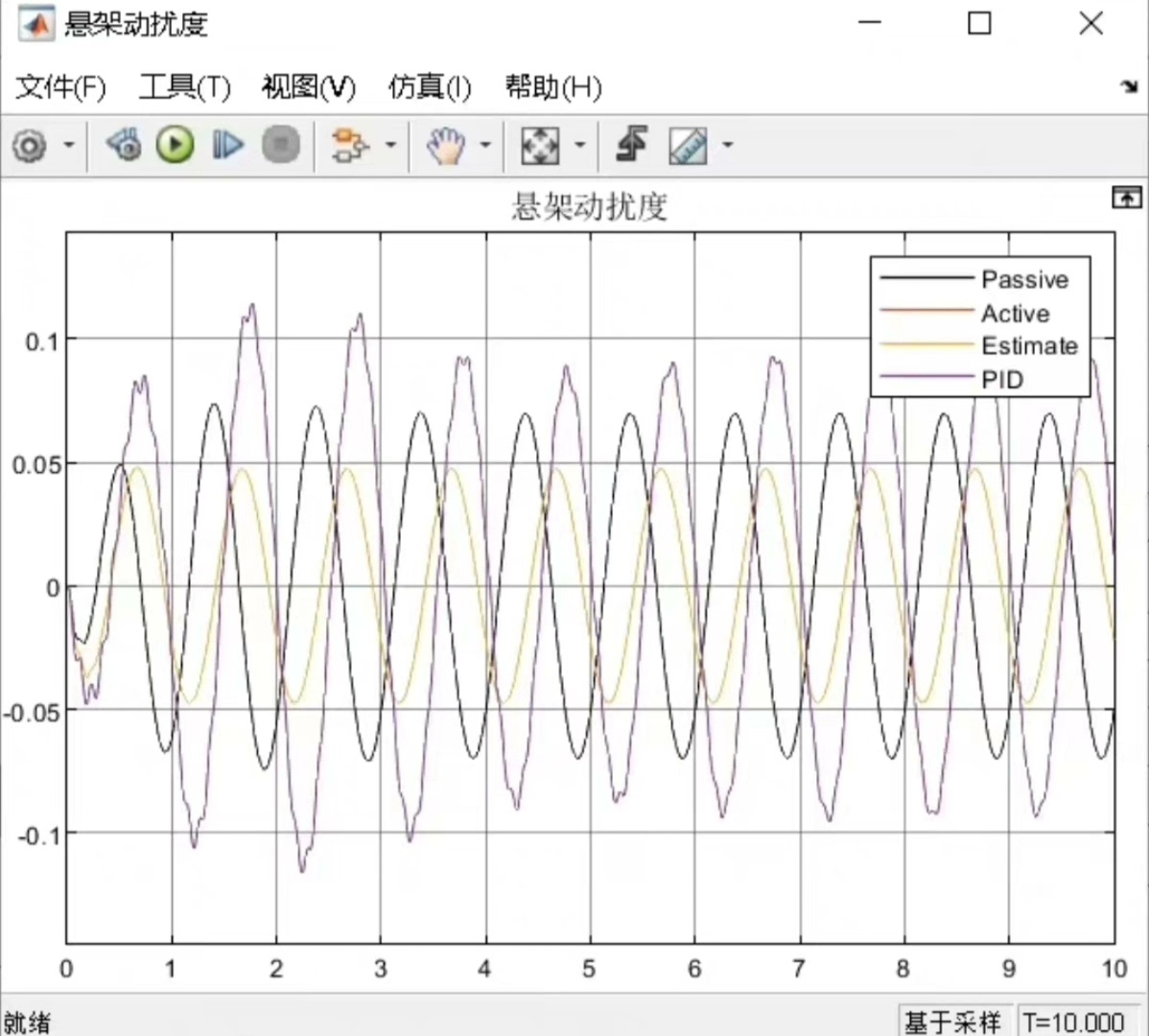
matlab/simulink半车主动悬架建模:基于ADRC(自抗扰控制)的主动悬架控制,主体模型为半车主动悬架,tt3采取ADRC控制。输出为车身加速度,悬架动挠度,轮胎动变形。默认输入为正弦路面输入。有与pid控制的效果对比。在汽车悬架系统的研究中,主动悬架能够显著提升车辆的行驶舒适性和操纵稳定性。今天咱们就来聊聊基于 Matlab/Simulink 的半车主动悬架建模,主角是自抗扰控制(AD
其实就像90年代末和2000年初,组装计算机甚至安装操作系统一样。那时候这些都是需要有点专业技术的人去完成的。但是随着技术的发展,不需要组装了。也预制了操作系统。这些工作就退出了市场、退出了历史。我们这些现在也是在做同样的事情。随着发展以后一定会想QQ和微信一样普及,哪怕在田间种地还是在交通通勤都可以方便的使用。而我们能在茶余饭后说,当时我们是第一批做XXXX的人。你知道那时候是怎么做的吗?
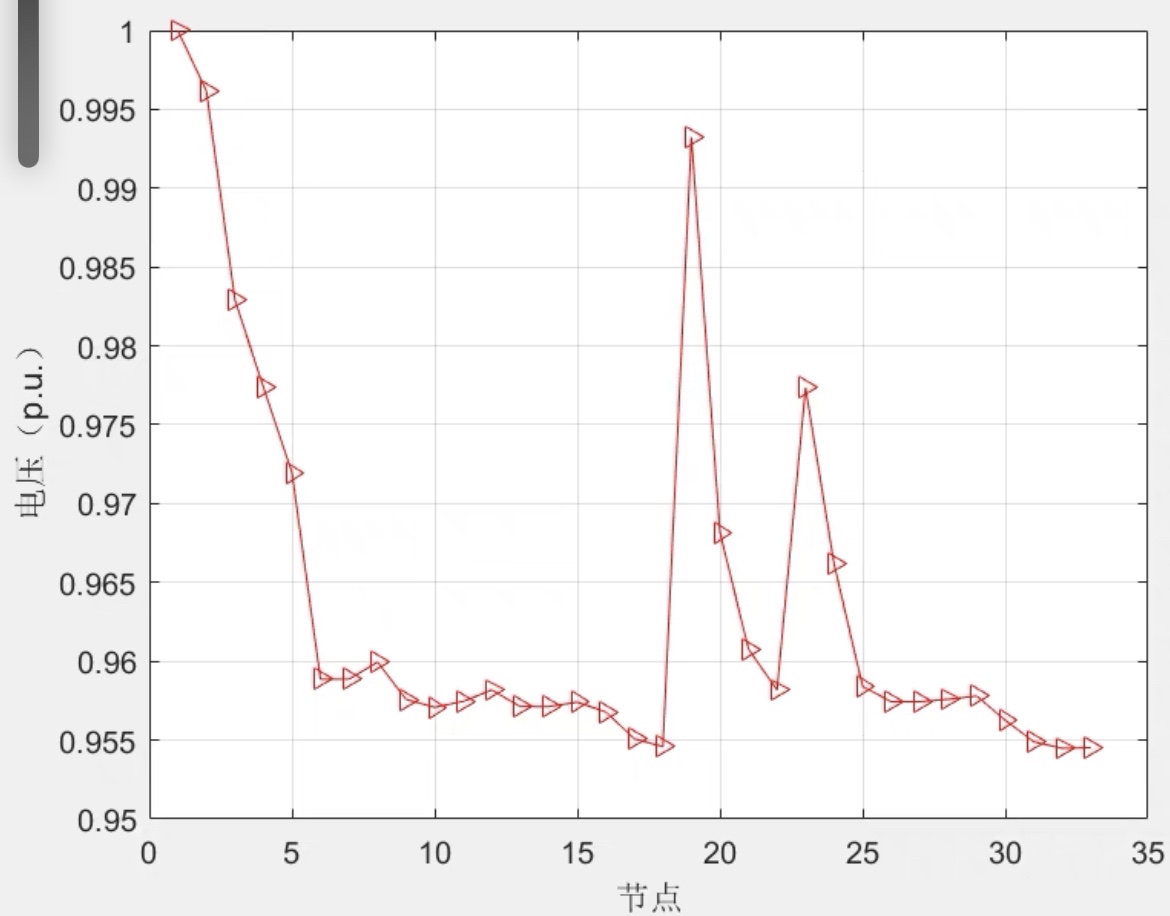
配电网故障重构matlab 二阶锥编程方法:matlab+yalmip(cplex为求解器)基本内容:以33节点为研究对象,编制配电网故障重构模型,采用图论知识保证配电网的连通性和辐射性,以网损和负荷损失作为目标函数,包括潮流约束、电压电流约束、sop约束、辐射性约束等,程序运行稳定,不,代码行行注释在电力系统研究中,配电网故障重构是一个至关重要的环节,它旨在故障发生后迅速恢复供电并优化网络运行。
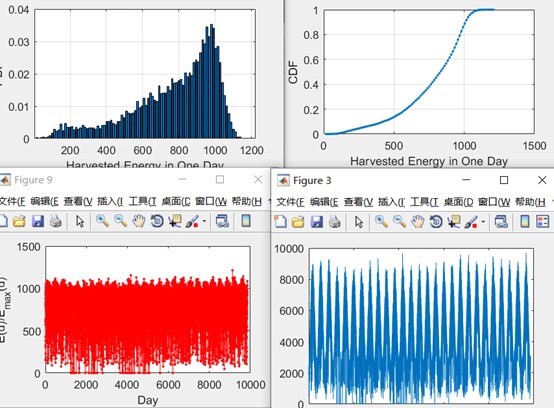
主要内容:代码主要做的是如何利用预测光伏电站太阳能辐射量的问题,利用人工神经网络对对其内太阳辐射量进行预测,并对无云天气以及多云天气进行了分别讨论,与线性模型相比该模型具有更好的性能,除此之外,代码还研究了太阳能的分配问题,采用离线优化算法和四种在线启发式算法分别进行分配策略的优化,并利用太阳辐射数据评估了算法的性能。通过缺失模式编码、在线 Bayes 校准、边缘友好压缩等工程化手段,兼顾了云端精
摘要:本文探讨嵌入式通信与端侧AI中的安全传输方案,重点分析TLS协议在资源受限设备上的轻量级实现。文章首先介绍对称加密(如AES、ChaCha20)和非对称加密(如RSA)的原理及适用场景,详细对比不同加密算法的性能特点。随后深入解析TLS 1.2/1.3握手流程及安全机制改进,并推荐专为嵌入式设计的MbedTLS库,其具有模块化、可裁剪等特点。最后强调在物联网设备激增和边缘计算发展的背景下,采
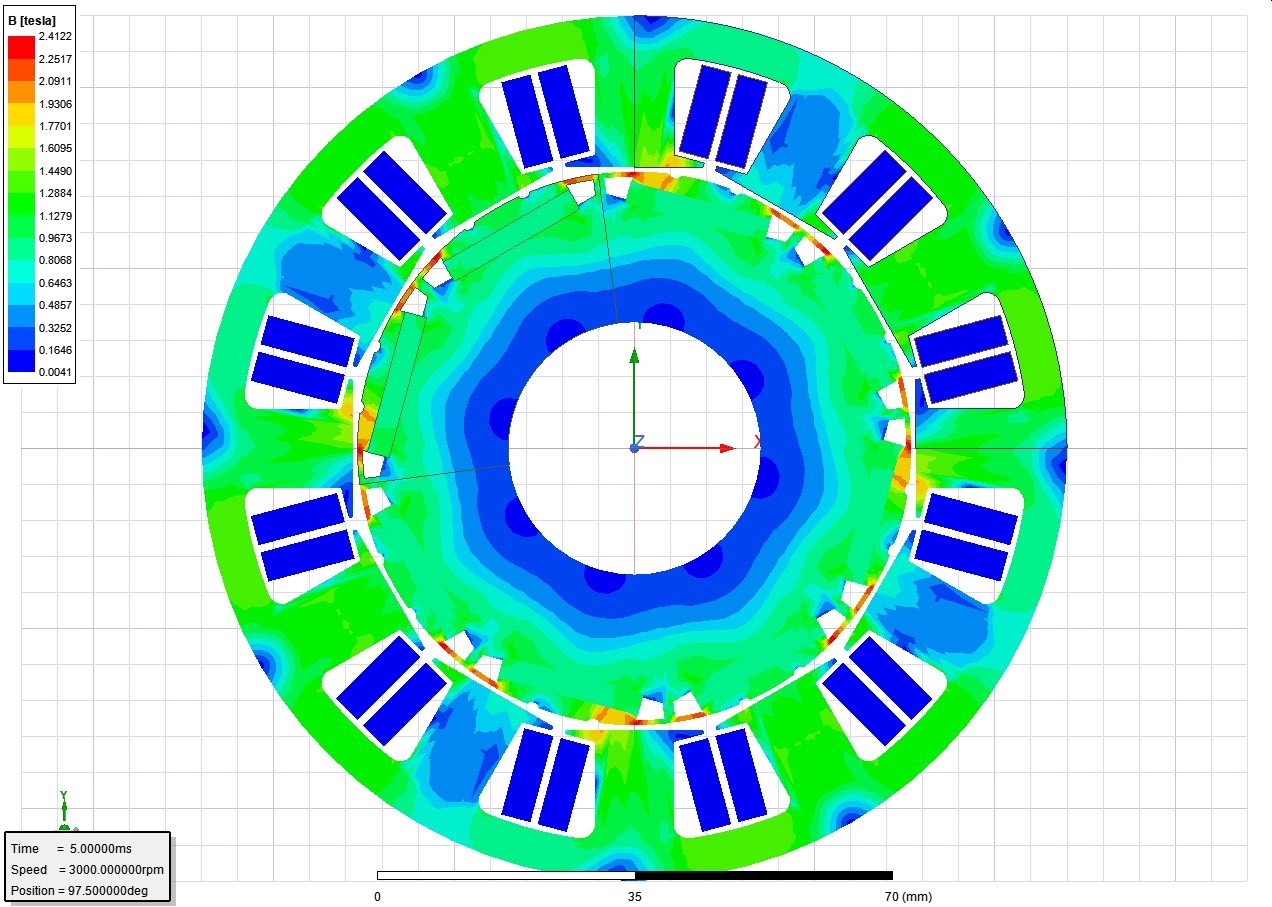
基于rm建模,Maxwell建立一字型的 8极12槽 外径120mm内径78 25mm轴向长度3000rpm 转速功率800W 转矩2.5Nm 直流母线48V 永磁同步电机极其设计模型 (PMSM和BLDC),特点转子开辅助槽、定子齿不均匀气隙。在电机设计的奇妙世界里,基于RM(磁路法)建模来构建特定规格的永磁同步电机及其设计模型,是一项充满挑战与乐趣的任务。今天咱们就来聊聊基于RM建模,利用Ma
CMMLU是针对中国背景下的大型语言模型的知识和推理能力的评测,由MBZUAI、上海交通大学、微软亚洲研究院共同推出,包含67个主题,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU是一个涵盖自然科学、社会科学、工程和人文学科等多个学科的综合性中国基准。是国内两大权威评测之一。
在当今数字化时代,智能城市的发展正以前所未有的速度推进,而深度学习技术作为人工智能的核心力量,正在为智能城市的建设带来新的突破和创新。从交通管理到能源优化,从公共安全到环境监测,深度学习的应用正在逐步提升城市的智能化水平和居民的生活质量。本文将探讨深度学习在智能城市中的创新应用,并展望其未来的发展趋势。
通过这个模型可以对输入对象的特征向量预测或对对象的类标进行分类。2、从通信的角度讲,如果使用 Hadoop 的 MapReduce 计算框架,由于是通过heartbeat 的方式来进行的通信和传递数据,会导致非常慢的执行速度,而 Spark 具有出色而高效的 Akka 和 Netty 通信系统,通信效率极高。线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分
Mllib的数据格式
数据集:下载Adult数据集(http://archive.ics.uci.edu/ml/datasets/Adult),该数据集也可以直接到本教程官网的“下载专区”的“数据集”中下载。//获取训练集测试集(需要对测试集进行一下处理,adult.data.txt的标签是>50K和50K.和
文章目录1. DenseVector、SparseVector2. DenseMatrix3. SparseMatrix4. Vector 运算5. 矩阵运算6. RowMatrix学自:Spark机器学习实战https://book.douban.com/subject/35280412/环境:win 10 + java 1.8.0_281 + Scala 2.11.11 + Hadoop 2.
感知器算法是一种用于二进制分类的监督学习算法,可以预测数字向量所表示的输入是否属于特定的类。在机器学习的术语中,分类被认为是监督学习的实例,即,其中可观测得到正确识别的训练集,可将之用于训练学习。在训练过程中,发现可能是因为由 make_classification 生成的数据集太理想,在学习率固定为 0.01 ,通过随机梯度下降进行 1个 epoch 的训练,即可得到非常好的效果,事实上,在 e
北京时间7月27日凌晨,全球将进入巴黎奥运时间一睹赛事盛况。在本届奥运会上,中国黑科技将大放异彩。笔者于赛前获悉,包括阿里云、商汤科技、高巨创新、艾比森等在内的中国科技公司将把其前沿的“黑科技”带上奥运舞台。从每秒500次识别的芯片足球、搭载智能芯片的运动垫、炫目的LED地板屏,到巴黎夜空的奥运烟花以及1100架无人机编队的精彩演出,再到云计算替代卫星成为奥运直播的主要方式、机器人服务员和无人驾驶
mllib
——mllib
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵









 全球具身智能开发者社区
全球具身智能开发者社区

 脑启社区
脑启社区

 腾讯云开发者社区
腾讯云开发者社区



 AtomGit开源社区
AtomGit开源社区

 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区



 九章云极普惠算力
九章云极普惠算力
 AI硬件创业社区
AI硬件创业社区
 龙虾开发者社区
龙虾开发者社区


 魔乐社区
魔乐社区