




- @m0_58966968
简介
首个存内计算开发者社区,基于知存科技领先的存内技术,涵盖最丰富的存内计算内容,以存内技术为核心,史无前例的技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003;
擅长的技术栈
可提供的服务
暂无可提供的服务
其次,初始化RLHF数据流中的模型并分配虚拟资源池;在这个游戏中,小鸟充当智能体,动作是让小鸟用力向上飞一下或者保持不动,状态包括小鸟的位置、高度、速度等,奖励是获得的积分,回报是获得的奖励的总和,策略是小鸟选择避开水管而飞得更远的依据。基于 Ray 的分布式编程,动态计算图,异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效

2023年,OpenAI推出GPT-4,实现了多模态大语言模型的进一步突破,参数量达到了1.76万亿,与GPT-3相比,GPT-4展示了更强的多模态处理能力,能够处理文本、图像等多种数据形式[11]。在MLLM领域,存内计算技术可以在MLLM训练和推理时提供显著的计算加速,由于神经网络巡礼和推理的核心是大规模的矩阵乘法和卷积操作,存内计算可以在存储单元中直接进行矩阵乘加运算,并在进行大量并行计算时

内存计算(IMC)的主要优势在于减少或抑制数据移动,从而提高了能效。减少数据移动的方法有多种,其中主要包括近内存计算、基于静态随机存取存储器(SRAM)的内存计算以及利用新兴的非易失性存储器(NVM)技术进行内存计算。下面将详细介绍这些技术及其优势。
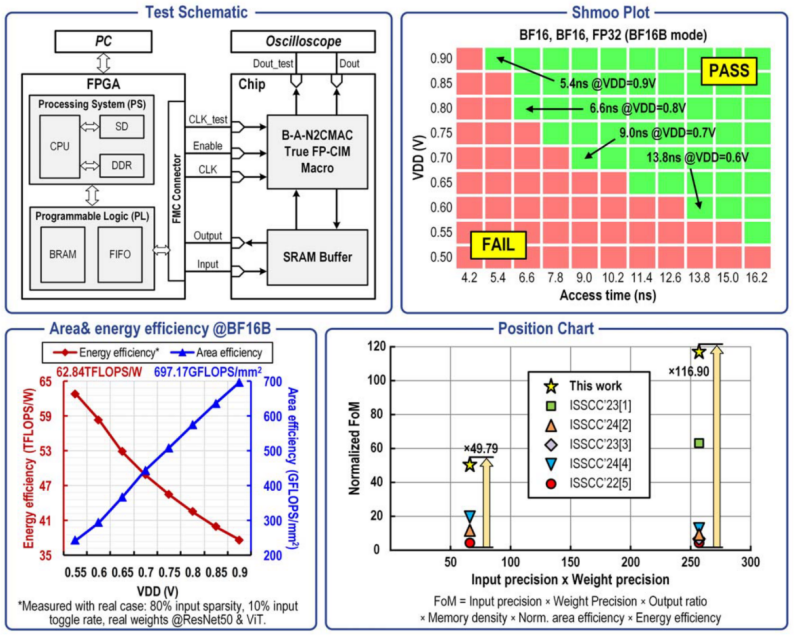
东南大学司鑫教授团队在ISSCC 2025上发表了一篇关于存内计算(CIM)的论文,提出了一种新型的广播对齐非二进制补码浮点存内计算宏(B-A-N2CMAC FP-CIM)。该研究针对高精度和高能效边缘AI芯片的需求,解决了传统浮点计算中的精度损失、性能损失和面积开销问题。通过创新的广播输入、嵌入式区域高效自适应对齐方案和格式混合的N2CMAC,该芯片在28nm工艺下实现了64kb的B-A-N2C
存内计算技术是一种新兴的计算范式,其核心理念是将存储和计算功能集成在同一硬件单元中。这种技术的优势在于能够在存储单元内部直接进行计算操作,从而减少数据在存储器和处理器之间的传输,提高计算效率。存储与计算的集成:存内计算技术通过在存储单元内部集成计算逻辑,实现了存储和计算的紧密结合。这允许在存储单元内部直接进行计算操作,而不需要将数据传输到外部处理器。减少数据传输:由于计算操作在存储单元内部进行,存

其次,初始化RLHF数据流中的模型并分配虚拟资源池;在这个游戏中,小鸟充当智能体,动作是让小鸟用力向上飞一下或者保持不动,状态包括小鸟的位置、高度、速度等,奖励是获得的积分,回报是获得的奖励的总和,策略是小鸟选择避开水管而飞得更远的依据。基于 Ray 的分布式编程,动态计算图,异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效
相较于传统的卷积神经网络,深度可分离卷积具有如下四个优势:1,更少的参数:可减少输入通道数量,从而有效地减少卷积层所需的参数;2,更快的速度:运行速度比传统卷积快;3,更加易于移植:计算量更小,更易于实现和部署在不同的平台上;4,更加精简:能够精简计算模型,从而在较小的设备上实现高精度的运算。

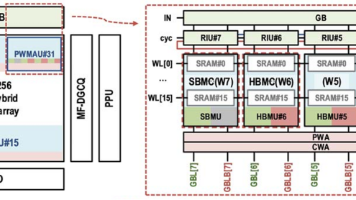
东南大学司鑫团队在ISSCC2025提出了一种创新的混合存内计算宏芯片,采用位旋转特征输入方案、嵌入式符号位处理技术和多比特融合双粒度协同量化器,有效解决了传统混合存内计算的精度损失、性能损失和面积开销问题。该芯片在28nm工艺下实现了67.8TOPS/W的高能效,在图像分类、视觉Transformer和自然语言处理等AI任务中精度损失均低于2%。与现有方案相比,该设计在硬件综合性能指标上提升显著
东南大学司鑫教授团队在ISSCC 2025上发表了一篇关于存内计算(CIM)的论文,提出了一种新型的广播对齐非二进制补码浮点存内计算宏(B-A-N2CMAC FP-CIM)。该研究针对高精度和高能效边缘AI芯片的需求,解决了传统浮点计算中的精度损失、性能损失和面积开销问题。通过创新的广播输入、嵌入式区域高效自适应对齐方案和格式混合的N2CMAC,该芯片在28nm工艺下实现了64kb的B-A-N2C
cosmos是一个用于加速物理AI开发的平台,可以预测与生成未来虚拟世界物理感知视频的神经网络,以帮助开发者进一步构建未来机器人与自动驾驶应用。WFM如大语言模型,属于一个基础性模型,WFM 通过学习大规模视频数据集中的物理规律和自然行为,能够生成与现实世界具有一定相似性的3D高清视频场景。同时通过扩散模型和自回归模型,对预训练的 WFM 进行微调,可以使其适应特定的物理 AI 任务。对于当下的具
