登录社区云,与社区用户共同成长
邀请您加入社区
2026年大城市职场竞争加剧,单一专业技能已难立足。CAIE注册人工智能工程师认证提供权威能力凭证,采用中英文双证体系,涵盖AI文案、数据分析等实用技能。认证分等级设置,零基础可报考一级,进阶二级学习企业级AI应用。课程性价比高,连报可获实战训练营和数据标注兼职机会。在智能化时代,掌握AI技能并获取权威认证,是突破职业瓶颈、增强竞争力的关键。
系统安装1,制作系统启动U盘,下载系统ubuntu-server 24.04lts.ios镜像。
Ai2 / Skylight 2026-07-15 在 Hugging Face Blog 发表《What building Shippy taught us about building agents》,公开了 Shippy 海事查询 Agent 的工程细节:Soul 与 Skills 打包为版本化 Docker 镜像,Config 切换 OpenClaw Harness 与当前 Claude
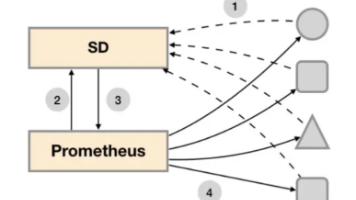
简介如图: SD模块是专门负责发现需要监控的target信息,prometheus去SD模块订阅该信息,有target信息会推送到Prometheus,然后Prometheus拿到target信息后通过pull http 协议去拉取该指标的数据。静态服务发现机制,配置简单,但是监控目标是写死在了配置文件中,如果要新增、修改、删除监控节点时,需要每次都去修改配置文件,然后再通知prometheus重
是Java集合框架中java.util包下的核心类,实现了Queue接口,它并非遵循“先进先出”的普通队列规则,而是根据元素优先级自动排序,每次取出的都是队列中优先级最高的元素。通过Comparator// 创建大顶堆(按Integer降序排序)// 出队(每次取最大值)// 8// 5// 2// 1自定义对象需通过Comparable或Comparator指定优先级规则,推荐使用Compara
这意味着,如果外界没有强引用指向这个 ThreadLocal 对象(比如我们把 ThreadLocal 变量设为了 null),下次垃圾回收时,这个 Key 就会被回收掉,于是 Map 里就出现了一个 Key 为 null,但 Value 依然存在的 Entry。这不仅是清理当前值,更重要的是它会清理掉整个 Entry,这是最有效、最安全的做法。这个 Value 是一个强引用,只要线程还活着(比如
官方定义kubeadm 是一个快速搭建 Kubernetes 集群的工具,提供 kubeadm init 和 kubeadm join 两个核心命令。核心功能│ kubeadm 核心功能 ││ ││ ├─ 初始化 Control Plane 节点 ││ ├─ 创建集群证书和配置文件 ││ ├─ 部署核心组件(etcd、API Server 等) ││ └─ 生成加入令牌 ││ ││ ├─ 加入 C
本文深入解析 Kubernetes 集群的服务发现系统 CoreDNS 部署、集群可用性验证方法以及节点管理全生命周期操作。详细剖析 DNS 解析原理、CoreDNS 插件架构、健康检查机制、集群扩缩容策略以及生产环境运维最佳实践。通过本文,读者将掌握 K8s 集群运维的核心技术与实战能力。关键词CoreDNS;服务发现;集群验证;节点管理;扩缩容;运维CoreDNS 架构原理与生产部署DNS 解
本文深入解析 Kubernetes 1.26 版本的重大技术变革与生产环境关键技术。涵盖 Dockershim 移除后的生态影响、CRI 容器运行时性能优化、kubelet 资源管理增强、API 服务器流控机制、安全策略演进以及生产环境升级实战。通过本文,读者将全面掌握 K8s 1.26 的核心技术要点与企业落地路径。关键词CRI;containerd;资源管理;APF;生产环境版本演进: CRI
灵茶山艾府贪心题单刷题记录 | 3074. 重新分装苹果 | 贪心入门题,优先用大箱子装苹果,排序后从大到小贪心即可 | Java 详解 + 思路分析 + 复杂度分析
/ 为 Informer 添加自定义索引if!ok {if!exists {// 注册索引})// 使用索引快速查询(O(1) vs 全量遍历 O(n))# 推荐使用 Kubernetes 官方推荐标签labels:app.kubernetes.io/name: mysql # 应用名称app.kubernetes.io/instance: mysql-prod # 实例名app.kubernet
本文解析一道高频机考题——“IP地址归属地查询”。给定大量可能重叠的城市IP段,针对查询IP找出包含该IP且区间长度最小的城市。若存在多层嵌套,需精确匹配最窄区间。本文将详解IP转整数技巧、全量扫描优化及贪心匹配逻辑,并提供生产级可用的 Java 和 Go 代码实现,助你在海量数据下依然保持毫秒级响应。
本文深入解析一道经典的内存分配算法题——“堆内存最佳适配”。在总空间固定为 100 字节的约束下,如何根据“优先紧接着前一块已使用内存,且分配空间足够且最接近申请大小”的原则,找到最优偏移地址?文章将拆解区间重叠检测、空闲块计算、贪心策略匹配三大核心步骤,并提供Java和Go两种语言的完整生产级代码。无论是应对机考还是理解操作系统内存管理原理,本文都将为你提供硬核支持。
本文深入解析华为 OD 机考中的经典题目“木材切割收益最大化”。题目要求将一根长度为 X 的木材切割成若干段正整数长度的木头,使得各段长度的乘积最大,且在收益相同的情况下,切割次数最少。本文将从数学规律入手,介绍贪心算法的核心思路(尽量切分为 3,其次是 2,避免 1),并提供 Java 和 Go 两种语言的完整实现代码。
Node Affinity 是 Kubernetes 中用于控制 Pod 调度到特定节点的机制。它通过或字段来定义节点标签匹配规则。例如,可以指定 Pod 只能运行在带有标签的节点上。在之前的版本中,PV 的是只读的,只能在创建时定义,不能在后续修改。这导致了上述提到的各种问题。Kubernetes v1.35 引入的是一个非常实用的功能,尤其适用于需要动态调整存储策略的场景。通过这项改进,我们可
RBAC 是一种安全机制,帮助我们根据用户的角色管理权限。它确保只有授权用户才能访问或修改 Kubernetes 中的资源。Role− 定义可以在哪些资源上执行哪些操作。− 将 Role 分配给用户或组。− 适用于整个集群的 Role。− 将 ClusterRole 授予用户或组。使用编辑器,创建一个名为role.yaml的文件并添加以下内容:kind: Rolemetadata:rules:应用
本文介绍了在现有Kubernetes集群中启用Calico eBPF数据平面的两种方案。方案一适用于kubeadm集群,通过Tigera Operator自动完成配置;方案二适用于所有兼容集群,需手动配置API Server直连和禁用kube-proxy。文章详细说明了前置条件、兼容性检查、API Server地址配置方法以及kube-proxy处理方式,并提供了各主流Kubernetes发行版的
Operator SDK是Kubernetes Operator开发框架,属于Operator Framework核心组件,已获7.6k+ Star。该开源工具通过高级API、代码生成和扩展机制,简化复杂有状态应用在K8s上的自动化管理。提供三种开发模式:Go(深度定制)、Ansible(低代码)和Helm(兼容现有Chart)。支持多平台运行,采用Apache 2.0许可,拥有活跃社区。注意:相
Caffeine: A High-Performance Java Cache Caffeine is a modern Java in-process cache library featuring: W-TinyLFU eviction: Combines LRU and LFU with a window (1% capacity) for burst traffic and adaptiv
计算资源的 limits 总和是否会超过节点上资源总和?答案:可能会。假设 node可用MEMORY为1G。每个pod内存 requests是256M,limit是512M。创建5个pod,pod实际占用内存也为256M(有可能小于256M)。node上大概可以创建4个pod,而此时的limits总和是2G。当计算资源的limits总和超过节点上资源总和时,kubernetes如何处理?对于 cp
Kubernetes 和 containerd 升级前,不要先改包源或重启服务。本文把升级前最容易漏掉的检查压缩成 12 条命令,覆盖版本、节点状态、CRI endpoint、containerd 配置、cgroup、日志和备份路径,并给出正常现象、异常判断和下一步处理建议,适合作为生产灰度升级前的执行清单。
我们在使用 Kubernetes 中过程中面临的问题:如何监控 node 计算资源使用情况?如何监控 pod 计算资源使用情况?如何根据 pod 计算资源使用情况,自动扩展?node 和 pod 计算资源使用情况。Metrics Server 是 Kubernetes 内置自动缩放管道的可扩展、高效的容器资源指标来源。
在生产环境部署 Kubernetes 之前,必须先做好架构选型(如 kubeadm vs 二进制)、节点规划、网络模型选择以及硬件和操作系统层面的前置检查,避免后续踩坑。
组件主要管理对象主要出现阶段解决的问题KubesprayLinux 机器上的 Kubernetes 组件与集群配置集群部署和维护怎么把一批机器安装成 Kubernetes 集群KubernetesNode、Pod、Service 以及 CPU、内存、GPU 等资源长期运行容器放在哪里,运行状态怎么维持KubeRayRayCluster、RayJob、RayService 及其 Kubernetes
本文提供了四种经典算法(动态规划、贪心算法、分治算法和回溯算法)的完整Java实现。动态规划部分展示了斐波那契数列和零钱兑换问题;贪心算法解决了活动选择问题;分治算法实现了归并排序;回溯算法求解了N皇后问题。每个实现都包含详细注释,并分析了时间复杂度,代码结构清晰,可直接运行测试。这些算法覆盖了计算机科学中的核心问题解决方法,适用于不同场景的最优化需求。
C++标准库(STL)提供了丰富算法,主要包括:排序算法(sort/stable_sort)、查找算法(find/binary_search)、数值计算(accumulate/transform)和序列操作(copy/remove_if)等。这些算法位于<algorithm>和<numeric>头文件,通过迭代器操作容器,时间复杂度从O(n)到O(nlogn)不等。使用时需
摘要:LeetCode 455题"分发饼干"要求用给定尺寸的饼干满足尽可能多的孩子。贪心算法通过将饼干和孩子按大小排序,优先用大饼干满足大胃口孩子来实现最优解。代码先排序两个数组,然后从后向前遍历,匹配满足条件的饼干和孩子,统计最大满足数量。示例输入g=[1,2,3],s=[1,1]时输出为1。
首先按照绝对值大小对数组进行排序,然后遍历数组将值为负数的元素进行翻转,最后检查K是否为0。如果K为偶数,可以直接返回数组之和,如果K为奇数,将最后一个元素翻转后累加返回即可。以这种方式修改数组后,返回数组。可以多次选择同一个下标。
情况二:rest[i] = gas[i]-cost[i]为一天剩下的油,i从0开始计算累加到最后一站,如果累加没有出现负数,说明从0出发,油就没有断过,那么0就是起点。情况三:如果累加的最小值是负数,汽车就要从非0节点出发,从后向前,看哪个节点能把这个负数填平,能把这个负数填平的节点就是出发节点。情况一:如果gas的总和小于cost总和,那么无论从哪里出发,一定是跑不了一圈的。,如果你可以按顺序绕
我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。找到相同字母对应的最远区间,然后进行分割即可。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是。返回一个表示每个字符串片段的长度的列表。
合并重叠区间,首先对数组进行左或右排序,判断边界是否重叠,如果重叠,就合并区间的左右端点。如果不重叠就直接添加进结果容器中。区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。表示若干个区间的集合,其中单个区间为。请你合并所有重叠的区间,并返回。
本文介绍了贪心算法的基本概念和应用。贪心算法是一种在每一步选择中都采取当前最优局部选择的策略,希望通过局部最优达到全局最优。文章通过压岁钱选择问题生动解释了贪心思想,即将大问题分解为多个小问题,每次选择当前最优解。文中提供了C++代码示例,展示了如何用贪心算法解决具体问题,并给出了排队接水问题作为练习题。最后强调贪心算法虽然简单有效,但并不适用于所有问题,建议多练习以掌握其应用场景。
模拟算法是指按照问题的描述或规则,一步步模拟真实过程,最终得到结果的算法。它通常不涉及复杂的数学优化,而是直接模拟问题的执行流程。
大部分题解......
本文介绍了贪心算法的定义、特点、适用场景及局限性。贪心算法通过局部最优选择希望达到全局最优,适用于具有贪心选择性质和最优子结构的问题如最小生成树、最短路径等。文章以NOIP2018提高组铺设道路题目为例,展示了贪心思路和代码实现,并推荐了洛谷贪心题单。贪心算法虽高效但不保证所有问题全局最优,需正确性验证。
贪心算法(Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优(局部最优)的决策,从而希望导致全局最优解的算法策略。其核心思想是通过局部最优解的累积逼近全局最优解,但需要注意贪心算法并不保证总能得到全局最优解,需结合问题特性分析。
假设有ABCD四个人,两个水龙头,总时间 = A的时间 + B的时间 + C的时间 + D的时间,而不是看谁最晚结束的时间。在最少的时候这种情况下,抽象到整个问题,第一次打水的r个人不需要排队,所以总时间就是他们的和,从第r+1个人开始就需要排队,排队时间就是前面的人的打水时间,这一个人的打水总时间即 T[i] + T[i-r] ,最后再把所有人的时间加到一起就是答案了。可以看出如果先让打水时间少
本文研究了字符串分割问题,给定一个长度为n的字符串s和整数k,要求将s分割为k+1段连续非空子串,计算所有可能的分割价值。价值定义为各子串极长颜色段数之和。通过分析字符串的特征分界点,推导出最小和最大可能价值,并给出计算两种极端情况的公式。最终答案即为可能价值区间的大小。当无法分割时输出0。该解法通过贪心策略确定边界,时间复杂度为O(n),适用于大规模数据。
https://blog.csdn.net/he_zhidan/article/details/144618103?sharetype=blogdetail&shareId=144618103&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
贪心算法
——贪心算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



 智能体开发者社区
智能体开发者社区

















 openEuler 社区
openEuler 社区

 AI硬件创业社区
AI硬件创业社区
 AI Agent技术社区
AI Agent技术社区










 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

