登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了SoC实验所需的软件安装方法,主要包括两部分内容:1)在Windows系统下安装Vivado 2019.2开发工具,详细说明了从官网或百度网盘下载安装包、解压安装、版本选择和配置参数的完整流程;2)在WSL2环境下安装Ubuntu 22.04.5操作系统,并建议配合VSCode的WSL插件进行代码编辑。文章提供了各步骤的界面截图和参考链接,帮助用户顺利完成实验环境的搭建。Vivado安装
本文针对国产操作系统(如银河麒麟KylinOS、统信UOS)下的Vim开发环境配置提供完整解决方案。主要内容包括:Vim基础安装与快捷键强化;.vimrc文件的定制化优化;信创开发必备插件的部署方法;国产编译器关联与多语言开发配置;以及批量操作、远程编辑等高效开发技巧。特别针对国产系统的架构差异(飞腾/鲲鹏/龙芯)和包管理机制进行了适配优化,解决了信创开发中常见的兼容性问题。通过本方案,开发者可快
2026智慧政务数字化服务平台建设项目整体实施方案随着数字中国建设进入全面深化落地阶段,2026年成为各地政务数字化转型的攻坚之年。根据国家互联网信息办公室、国家发展改革委、工信部2026年联合印发的《数字政府建设深化升级行动方案(2026-2028年)》明确要求,全国各级政务服务体系需完成“全流程数字化、全场景智能化、全覆盖便民化”的转型升级,彻底破除传统政务服务存在的流程碎片化、数据孤岛、线下
采用的方案:Windows 10 本机 + WSL2 Ubuntu-22.04 + PyCharm WSL 解释器。原因如下:Vision Mamba 官方环境给的是 Python 3.10.13、PyTorch 2.1.1 + CUDA 11.8,并要求安装 causal-conv1d 和 mamba-1p1p1;而 Mamba 官方依赖也明确写着主要要求是 Linux + NVIDIA GPU
综合评估:Kimi K3是否重新定义了“长文本AI助手”的边界?目标用户与适用场景推荐:最适合哪些人群和使用需求?未来展望:对Kimi模型系列技术演进方向的预测与期待。
本文介绍了Linux学习中常用的两类开发工具。首先讲解了软件包管理器(如yum/dnf、apt),重点说明其解决依赖关系的优势,并列出CentOS系统下dnf的常用命令。其次详细介绍了vim多模式编辑器的三种基础模式(命令/插入/底行模式)及其核心操作命令,包括模式切换、光标移动、编辑操作等,同时提及了vim的配置文件位置。全文强调Linux生态中软件来源的社区属性,指出丰富的软件仓库是衡量操作系
linux
对比维度Hermes Agent(爱马仕)OpenClaw(龙虾)定位设计思想偏向通用私人 AI 智能体,面向个人玩家、轻量化自动化、日常助手;强调长期记忆、个性化养成偏向任务自动化、工具调用、批量执行复杂工作流,更适合重度工具自动化、批量任务、爬虫类工作场景记忆系统✅原生持久记忆模块,开箱即用;长期记忆、对话记忆分层,能够记住长期偏好、历史任务,适合持续养成私人助手记忆能力偏弱,短期上下文为主;
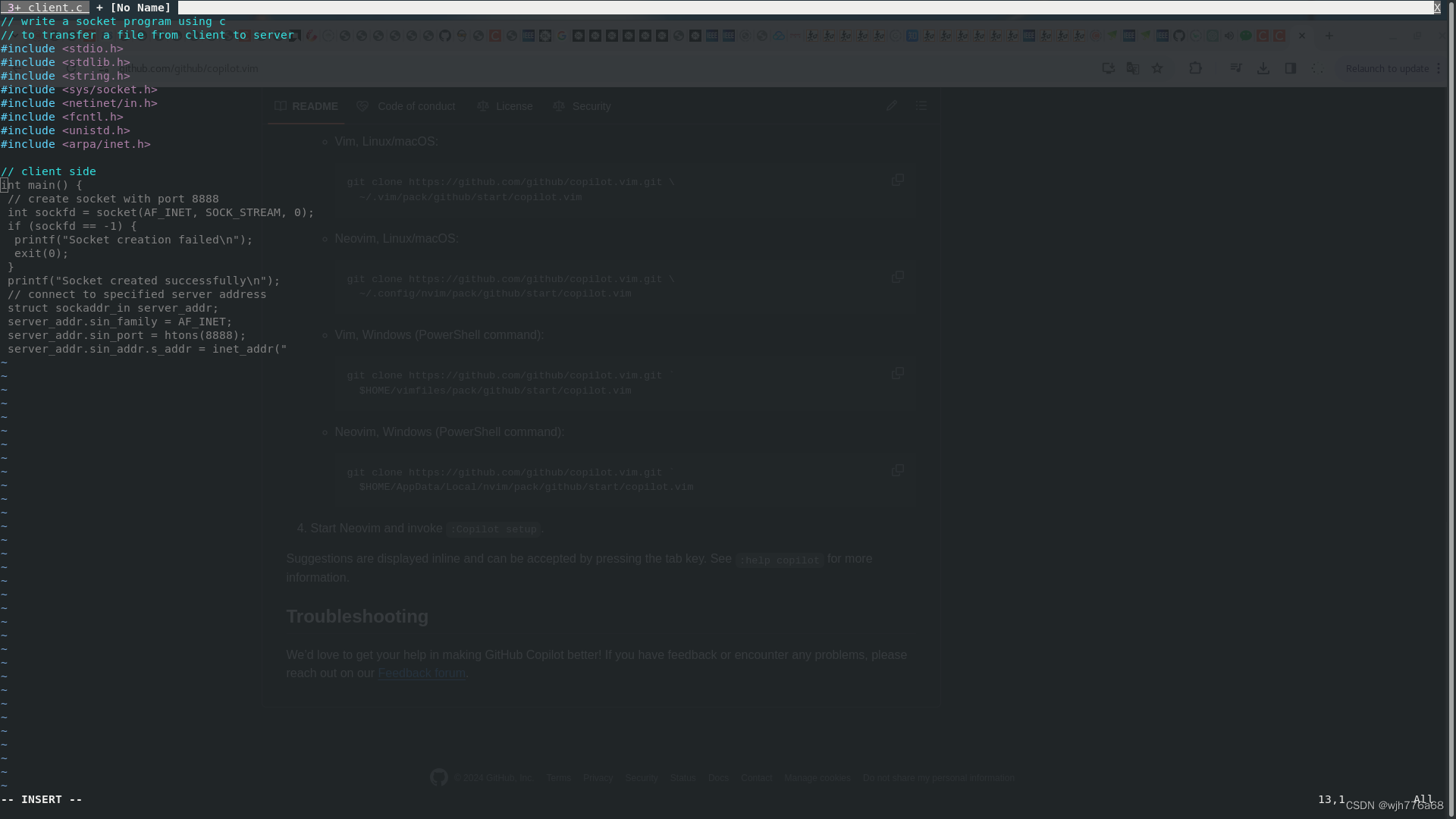
使用不熟悉的开发语言或函数库进行开发工作学习成本较高、效率较低。本文介绍vim Copilot代码补全插件的安装及使用过程
比如你有一堆配置文件需要按相同规则修改,可以先录一个宏(qa开始录制到寄存器a),执行一次操作,然后@a重复。当然,VS Code也有Vim插件(Vim extension),可以在VS Code里使用Vim的键位。这样既能享受Vim的高效编辑,又能用VS Code的丰富功能。"——如果你能说"我习惯用Vim+tmux在终端里开发,SSH到机器人上直接调试",面试官会觉得你很专业,特别是做嵌入式或
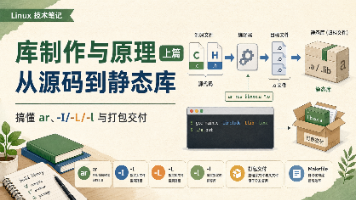
本文从一套可直接编译的源码出发,讲清头文件、源文件和目标文件之间的关系,并使用 gcc 与 ar 完成静态库制作。通过实际报错分析 -I、-L、-l 的作用,进一步介绍静态库的目录整理、Makefile 自动构建、打包交付、系统安装及 ldd 查看依赖等内容。
本文介绍了Vim编辑器在机器人开发中的实用技能。文章从面试失败案例切入,强调掌握Vim基本操作的重要性,详细讲解了Vim的三种模式切换、基础编辑命令、光标移动、文本操作等核心功能。针对机器人开发场景,特别说明了Vim在服务器配置修改、日志查看等方面的优势,并提供了基础配置建议。最后给出了循序渐进的学习建议:从vimtutor入门,先掌握核心操作,再逐步扩展技能,不必追求精通但需确保能完成基本编辑任
本文总结了Linux和Vim的基础操作指南,涵盖五个核心部分:1)Linux文件系统基础,包括目录结构和"一切皆文件"理念;2)常用Linux命令如ls、cd、rm等;3)Vim编辑器的三种模式、基本操作和快捷指令;4)inode概念及硬软链接区别;5)文件权限管理和chmod命令的使用方法。内容针对Linux初学者,重点介绍了日常操作中最实用的命令和技巧,特别强调了Vim作为
本文介绍了四种指针类型及其应用:1.二级指针(指向指针的指针),用于修改外部指针变量和指针数组传参;2.void指针(无类型指针),用于通用内存地址操作,需注意类型转换;3.volatile指针,防止编译器优化,确保每次访问内存;4.数组指针与指针数组的区别及应用,包括二维数组操作和字符串排序实现。通过代码示例详细说明了各种指针的使用场景和注意事项。
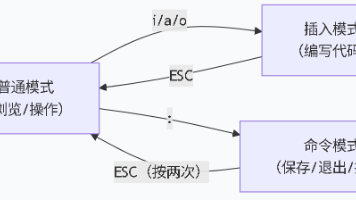
vim 的核心是模式切换,Esc 是返回命令模式的通用键,新手需先熟记模式切换方式;命令模式是 vim 的核心,dd/yy/p/u(删 / 复制 / 粘贴 / 撤销)和gg/G/0/$(光标跳转)是高频必记操作;末行模式的:wq/:q!(退出)、(全局替换)、:set nu(显示行号)是新手必备指令;新手可通过 Linux 内置的vimtutor命令,进入交互式教程,快速巩固基础操作。
一篇吃透 Linux 多用户机制:UID/GID、root 与普通用户区别、useradd/usermod/passwd/chmod/chown 等 15 条高频命令,配合用户组批量赋权技巧,告别“Permission denied”。另一篇聚焦 Vim 高效编辑:安装、三种模式切换、撤销/复制/删除/查找/替换快捷操作,附行号跳转与多窗口技巧,10 分钟把 Vim 变成 IDE。两文连贯,先搭好
打开 vim 先在命令模式,想写字切输入模式(按 i/a/o),想保存退出切底线命令模式(按:);不管在哪,按 Esc 能回到命令模式,这是 “救命键”;先记高频命令(比如 yy 复制、dd 删除、:wq 保存退出),用多了自然就熟了。刚开始可能会忘命令,没关系,把这篇文章存起来,用到的时候翻一翻,练个两三次就能上手了!
打开vim,默认我们处在命令模式,此模式下输入的所有东西都会被视作命令,有的同学第一次打开vim直接开始写代码却没有反应的原因也是如此。退出Shell之后再重新登录不能再撤销历史命令,历史命令储存再Shell进程的PCB中,Shell进程没了,储存的历史命令被释放了。在命令模式下按i可以进入插入模式,插入模式用于输入和编辑文本,是最接近普通文本编辑器的模式,也是我们以后使用最频繁的模式。Vim和V
Vim的强大功能和高度定制化的特性使得它成为许多开发人员钟爱的工具,能够极大地提升编辑效率,使用户能够更加专注和迅速地完成任务。然而,一旦掌握了Vim的基本知识和编辑技巧,它将成为一个高效且强大的编辑器,能够大幅提升开发人员的生产力。Vim在Linux社区中的广泛应用源于它与Linux系统的天然契合,强大的编辑功能以及开源自由的特性,使得许多Linux用户将其作为首选编辑器,并在日常工作中充分发挥
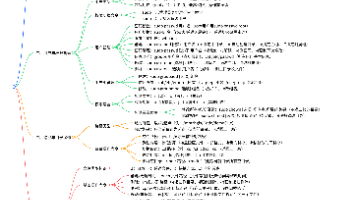
2.1 安装软件的三种方式2.2 生态问题【使用者视角】【提供者视角】【生态的最终考量】三、yum相关操作3.1 查看软件包3.2 安装和卸载软件3.3 软件源基本软件源(base)扩展软件源(epel)3.4 yum本地配置四、lrzsz软件包五、Linux 编辑器 ——vim六、vim的多种模式6.1 命令模式命令集6.2 底行模式命令集七、vim配置。
Linux软件管理与vim编辑器摘要 软件包管理: yum是Linux下常用包管理器,类似应用商店,可自动处理软件依赖关系 基本操作:yum list查看软件包、yum install安装、yum remove卸载 注意事项:需要网络连接和sudo权限,安装时需按顺序执行 vim编辑器: 三种主要模式:命令模式(移动光标/删除)、插入模式(文本输入)、末行模式(保存/搜索) 常用操作:i进入插入模
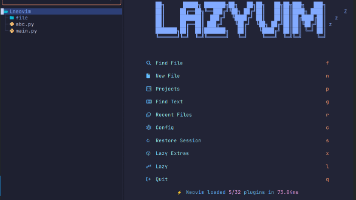
Neovim + LazyVim 现代化配置摘要 本文详细介绍了如何配置现代化的 Neovim 开发环境: 核心准备: 必须安装 Nerd Fonts 字体支持图标显示 需要基础工具如 ripgrep、fd、git 等 安装步骤: 安装 Neovim 0.9.0+ 版本 备份旧配置后克隆 LazyVim starter 仓库 首次启动会自动下载插件 核心功能: 文件导航:<leader>
如果某个运维人员或者某个运维团队需要编写大量的脚本,那么,统一shebang和注释可能会是一个比较规范的做法,比如,脚本创建时间,谁创建的,脚本的介绍这些信息如果能够自动生成,将会非常的nice例如如下图所示,创建一个新的以sh结尾的文件,会自动添加下面所示的shebang和注释:
本文梳理了 Linux 体系结构、核心 shell 命令、编译工具链三大模块,涵盖内核、系统调用、文件目录操作、编译调试、Makefile 及静态 / 动态库等关键知识点。
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。
本文详细介绍了在MongoDB中批量插入文档的多种方法。首先展示了在MongoDB Shell中使用insertMany命令的基本操作步骤,然后分别提供了Node.js、Python和Java三种编程语言的实现方案。每种语言都包含完整的代码示例,从安装驱动、建立连接到执行批量插入操作。文章还特别说明了Java环境下的依赖配置和编译运行方法。这些跨平台、多语言的实现方案,为用户提供了灵活选择,能够满
本文介绍了Linux开发运维中的三大基础技能:Vim编辑器、GCC编译器和tar打包解压命令。重点讲解了Vim的三种模式(普通、插入、命令)及基本操作,GCC编译的四个阶段(预处理、编译、汇编、链接),以及tar命令的打包与压缩/解压操作。文章还提供了常用命令速查表,包括Vim编辑、GCC编译和tar打包解压的核心命令参数说明,帮助开发者快速掌握Linux环境下的基本开发流程。
本文详细介绍了在MongoDB中删除索引的多种方法,包括使用Shell、Node.js、Python和Java四种方式。主要内容包括:通过索引名称或键删除特定索引、删除所有非_id索引的操作步骤,以及每种语言环境下的具体实现代码。文章还提供了获取索引信息、验证删除结果等实用技巧,帮助开发者在不同环境中有效管理MongoDB索引,优化数据库性能。适用于需要清理或调整MongoDB索引结构的开发人员。
MongoDB聚合管道中的$match阶段用于文档过滤,类似于SQL的WHERE子句。本文通过Node.js示例演示了三种常见过滤操作:1)筛选amount>100的订单;2)查找status为shipped且amount<200的订单;3)查询customerId=2或amount在100-200之间的订单。示例包含数据插入和聚合查询完整代码,并展示了Python(PyMongo)的
的模板 SQL,再通过参数绑定填充动态值,最后执行。是处理「动态参数」「二进制数据(BLOB/TEXT)」的标准方式,也是防 SQL 注入的最佳实践。MySQL 数据类型可分为「普通类型(文本 / 数值)」和「二进制大对象(BLOB)」两大类,读写逻辑的核心差异在于「数据存储形式」和「内存处理方式」。MySQL C API 提供两种核心 SQL 执行方式,分别适配「静态固定 SQL」和「动态参数
在Linux终端中,命令行可以正常显示中文,但使用Vim打开文件时,中文内容变成乱码(如���或��),或者Vim启动时报错E749: Empty buffer。这通常是因为Vim的编码配置不正确,或者配置文件包含了不可见字符。
一、read。
本文为嵌入式 Linux 入门系列笔记,可以一起学习,一起成长!适合零基础初学者快速掌握等必备基础,为嵌入式开发打下系统使用根基。
最实用的 vi 常用命令大全 linux 回归基本功
场景类比手机应用商店华为应用商店、小米应用商店、App StoreLinux 包管理器yum(CentOS)、apt(Ubuntu)以下操作以CentOS为例包管理器就是Linux 上的应用商店,你可以:yum searchyum removevim 是 Linux 系统自带的文本编辑器它是vi 的增强版后端程序员必须掌握(线上环境编辑配置文件、写代码)问题答案是什么?Linux 上的应用商店,包
摘要:本文全面讲解Linux系统管理的核心技能,涵盖Vim编辑器、用户/组管理和文件权限控制。Vim部分详细介绍三大模式切换、高频操作命令及查找替换技巧;用户管理重点讲解用户分类、创建/修改/删除用户及密码设置;文件权限部分解析权限基础、查看修改方法及特殊权限(SUID/SGID/SBIT)的应用。所有命令均提供可直接复用的实例,适合Linux初学者、运维人员和应试者快速掌握系统管理核心技能。(1
本文介绍了Vim编辑器的基本概念和操作指南。主要内容包括:1) Vim的三种模式:命令模式、插入模式和底行模式;2) 基本操作如文件打开、模式切换(i/a/o插入、Esc返回命令模式、:进入底行模式)和保存退出命令;3) 命令模式下的高效操作:光标移动(hjkl/G/$/^等)、文本编辑(删除x/dd、复制yy/p、替换r/R、撤销u)、查找跳转(/、?、nG)等;4) 底行模式功能:设置行号(s
本文介绍了Linux开发中两个基础工具Vim和GCC的常用操作。Vim部分涵盖模式切换、文本编辑、光标移动、代码格式化等核心功能;GCC部分详细说明了从预处理到链接的完整编译流程,包括分步编译和一步编译两种方式。通过本文,读者可以快速掌握在Linux环境下使用Vim编写代码和用GCC编译程序的基本技能,为后续开发工作打下基础。建议通过编写简单程序实践这些操作,加深理解。
vim是Linux中一个较为常用的编辑器,也是Linux中上手难度最大的编辑器之一。有的同学可能知道vi这个编辑器,其实vim就是vi的增强升级版。只要我们学会了如何使用vim,那Linux下的其他编辑器就可以说是到手就顷刻炼化了。
本文介绍了Git版本控制系统的核心操作指南。首先讲解了全局身份配置方法,包括用户名和邮箱设置。然后详细说明了本地库的基础操作流程:从创建/编辑文件、添加到暂存区到提交至本地库的全过程。进阶部分涵盖了文件修改后的重新提交、版本差异对比(工作区/暂存区/本地库)、版本回退等实用技巧。最后讲解了分支管理的关键操作,包括创建、切换、合并分支等并行开发必备技能。全文通过具体命令示例,帮助开发者掌握Git本地
学会了装软件,下一步是编辑代码。Linux 服务端没有图形 IDE,日常编写代码、改配置都依赖终端编辑器。vim 是 vi 的增强版,支持语法高亮、多级撤销、插件扩展等。它最大的特点——或者说门槛——是。
vim
——vim
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区
 AI编程社区
AI编程社区




 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵

 葡萄城开发者空间
葡萄城开发者空间