




- @cf13572820587
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Milvus 是一个高性能的开源向量数据库 ,广泛应用于RAG系统向量检索。安装 Milvus 的方法有多种,包括和。本文主要讲基于docker的安装方法。
当用户发送一个问题到部署好的 vLLM 服务(如 Qwen3.5-27B)时,模型内部经历了一个从输入到输出的完整推理流程。
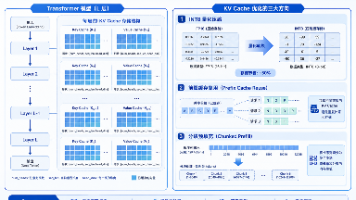
KV Cache 优化是 LLM 推理部署中最具性价比的优化手段。KV Cache 量化(INT8):显存减半,精度损失 <0.1%,vLLM 一行参数搞定前缀缓存(RadixAttention):多请求共享前缀,RAG 场景加速 3-5x分块预填充(Chunked Prefill):防止长请求阻塞短请求,P95 延迟降低 60%+在 A100 80GB × 4 卡的实测中,综合使用这三项优化后,
Claude Code 是 Anthropic 公司推出的命令行工具,让开发者能够通过终端与 Claude AI 模型进行交互。本文将为您提供在 Windows 系统上快速安装和配置 Claude Code 的完整指南,帮助您快速上手这个强大的 AI 开发工具。

KV Cache 优化是 LLM 推理部署中最具性价比的优化手段。KV Cache 量化(INT8):显存减半,精度损失 <0.1%,vLLM 一行参数搞定前缀缓存(RadixAttention):多请求共享前缀,RAG 场景加速 3-5x分块预填充(Chunked Prefill):防止长请求阻塞短请求,P95 延迟降低 60%+在 A100 80GB × 4 卡的实测中,综合使用这三项优化后,
Claude Code 是 Anthropic 公司推出的命令行工具,让开发者能够通过终端与 Claude AI 模型进行交互。本文将为您提供在 Windows 系统上快速安装和配置 Claude Code 的完整指南,帮助您快速上手这个强大的 AI 开发工具。
Claude Code 是 Anthropic 公司推出的命令行工具,让开发者能够通过终端与 Claude AI 模型进行交互。本文将为您提供在 Windows 系统上快速安装和配置 Claude Code 的完整指南,帮助您快速上手这个强大的 AI 开发工具。
这种追踪机制对于微服务架构尤其重要,可以帮助开发者理解复杂的请求流程。是追踪系统中的基本单位,代表一个操作或工作单元。
vLLM 是一个高性能的大型语言模型推理和服务库,具有以下特点:它支持多种模型(如 Llama、Mixtral 等)和硬件(如 NVIDIA GPU、AMD GPU 等),能够显著降低推理成本并提高资源利用率。Vllm一般适用于在linux上部署大模型,本文以ubuntu 24.02.2 系统、内存32G、显卡Nvidia、显存12G上部署为例讲解。A、硬件配制要求:CUDA 12.2。B、pyt
准确率是在模型预测为“相关”的结果中,实际为“相关”的比例。通俗的说,就是“找出的结果,有多少是对的”。举例:在问答系统中,如果模型从数据库召回了10个可能的答案,但只有三个是正确的,那么正确率就是30%。举例:在问答系统中,如果数据库中总共有5个正确答案,而模型只找出了3个,那么召回率就是60%。False Negatives(FN):模型没有检索出的相关结果(漏检)。True Positive