- @nobigdeal00
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
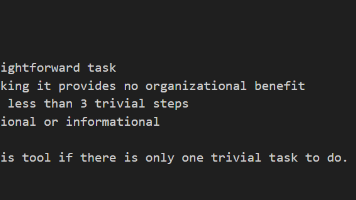
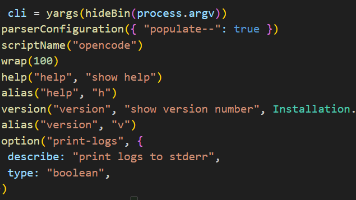
本文分析了OpenCode项目中的链式调用配置模式,重点解释了yargs库的配置方法。文章首先介绍了scriptName()、wrap()等基础配置项的作用,随后深入剖析了链式调用的实现原理——每个方法返回this以支持连续调用。通过Builder模式示例对比了链式与非链式写法差异,指出链式调用的声明式优势。最后列举了CLI构建、DOM操作等典型应用场景,强调链式调用本质是通过return thi
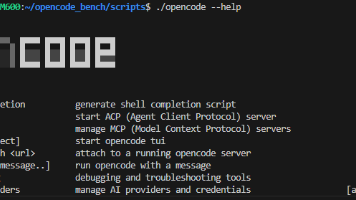
本文深入解析了命令行工具中--分隔符的设计原理与应用场景。通过OpenCode项目的yargs配置实例,阐述了populate--: true的作用:将--后的参数存入argv["--"]数组而非作为当前命令选项解析。文章对比了有无分隔符时opencode run --help的差异,指出该机制能有效解决多级命令间的参数歧义问题,并以git log和bun run为例说明其在参数透传中的关键作用。
本文分析了AI系统中的Slash Command(斜杠命令)与Bash命令的区别与联动关系。Slash Command是封装复杂提示词的高级快捷指令(如/review),用于触发AI特定工作流;而Bash命令(如git status)是直接操控操作系统的原生指令。二者通过!前缀实现联动——Slash Command可内嵌Bash命令(如/commit-push-pr包含!git add步骤),形成
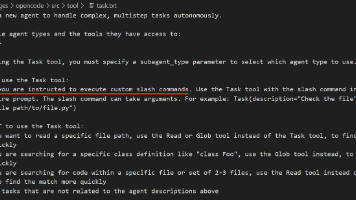
本文分析了OpenCode项目中的Skill工具设计特点。该工具用于加载特定领域技能,但目前运行时环境无可用技能(list.length=0)。核心机制包括:1)触发条件需AI精准匹配任务特征;2)按需加载设计,通过Skill.fmt(list, {verbose: false})仅展示技能简略清单,调用工具后才会注入详细指令(含XML/HTML标签块),有效节约Token;3)参数name为必填
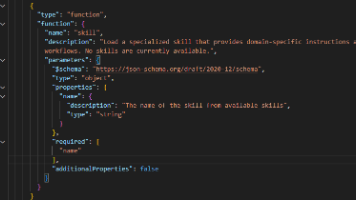
本文分析了OpenCode项目中的Skill工具设计特点。该工具用于加载特定领域技能,但目前运行时环境无可用技能(list.length=0)。核心机制包括:1)触发条件需AI精准匹配任务特征;2)按需加载设计,通过Skill.fmt(list, {verbose: false})仅展示技能简略清单,调用工具后才会注入详细指令(含XML/HTML标签块),有效节约Token;3)参数name为必填
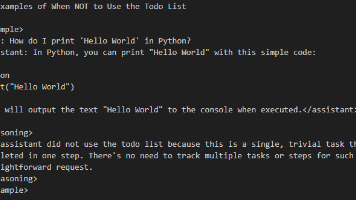
本文分析了OpenCode项目中TodoWrite工具的两个"不适用"示例。在"Hello World"案例中,AI直接输出单行代码,推理显示该任务满足单一、琐碎、单步特性,无需任务管理;在"git status解释"案例中,AI识别到这是纯知识查询请求,属于信息获取而非工程执行,因此直接调用知识库回答而非启动工具。两个案例共同体现了AI对任务性质的精准判断能力,能够区分简单任务与复杂工程需求,避
本文分析了TodoWrite工具的多个应用场景,重点探讨了其在复杂任务处理中的核心机制。文章首先回顾了重命名需求案例,展示了AI如何通过"先搜索后决策"模式动态调用工具,并详细解析了内部推理流程,包括任务边界评估、复杂度阈值触发和一致性保障机制。随后针对电商功能开发案例,阐述了显式指令识别、认知负荷拆分和全局进度管理三大特性。在性能优化案例中,突出了AI"先分析后判断"的工程纪律,以及如何将抽象问
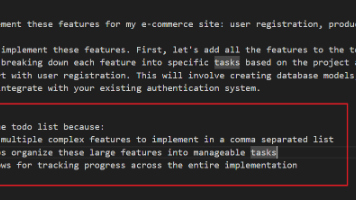
本文分析了两则AI编程工具的案例,展现了其系统化工程思维:第一例重命名需求中,AI先全局搜索15处引用再拆分任务清单,确保修改全覆盖;第二例开发电商功能时,AI自动将用户需求分解为数据库、API等可执行模块,并严格串行开发。两案例共同体现了AI的架构意识(分层设计)、动态决策(基于复杂度触发工具)和工程纪律(单线程执行),其通过结构化清单管理任务边界和依赖关系,有效规避了代码重构和系统集成中的常见
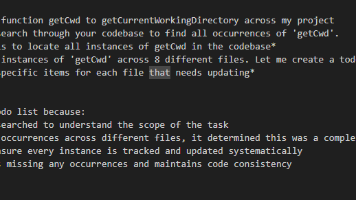
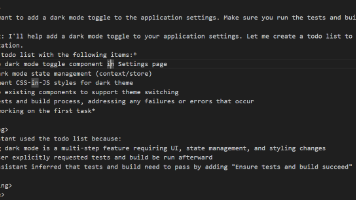
本文分析了AI助手在处理"添加Dark模式"需求时的工程思维,重点展示了其架构设计能力和需求解析逻辑。AI通过三点判断触发TodoWrite工具:1)识别该任务涉及UI、状态管理和CSS样式三个技术领域;2)明确用户要求的测试构建指令;3)主动推断出未明说的错误处理需求。在任务拆解中,AI展现出关注点分离思维,将任务结构化分为界面组件、全局状态、样式实现、集成测试四个维度,并补充了错误处理环节,形
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除。