




- @2401_84059420
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
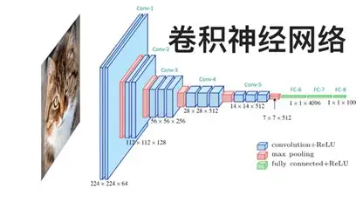
摘要:本文介绍了卷积和池化的基本原理。卷积操作涉及卷积核、步长、填充和通道四个属性,通过核矩阵与输入图像的数值相乘求和实现特征提取。池化分为最大池化和平均池化两种,能降低计算量并增强模型鲁棒性,反池化则用于数据恢复。池化层具有增大感受野、抑制噪声、减少计算量、防止过拟合和提高位置鲁棒性等五大作用。(150字)
Milvus是一款专为AI场景设计的向量数据库,用于高效存储和检索非结构化数据转换后的嵌入向量。文章首先对比了Milvus与MySQL的区别:Milvus擅长处理高维向量相似度检索(如图像识别),支持GPU加速和多种索引方式;MySQL则适用于结构化数据管理。接着详细介绍了Milvus的核心概念(Collection/Field)、5种检索算法(FLAT/IVF_FLAT/IVF_PQ/HNSW等
本文介绍了Neo4j图数据库的基本概念、安装配置及Cypher查询语言的使用。主要内容包括:1)Neo4j作为开源NoSQL图数据库的特点和版本差异;2)Java环境配置和Neo4j安装步骤;3)Cypher语法详解,涵盖节点/关系的创建(CREATE/MERGE)、查询(MATCH)、删除(DELETE)等操作;4)常用字符串函数和聚合函数;5)索引的创建与管理。文章通过具体示例演示了如何操作图

本文详细介绍了Ollama本地部署及Qwen2-32B模型安装过程。首先指导用户下载并解压Ollama 0.17.5版本,通过环境变量配置监听地址和端口,解决服务启动参数不兼容问题。随后介绍Windows环境下安装Ollama客户端,下载Qwen2.5-32B模型的方法。最后讲解如何通过Docker部署OpenWebUI界面,包括端口映射调试和常见错误排查。整个流程涵盖Linux/Windows双

本文介绍了在本地部署Dify平台并连接Ollama大模型的完整流程:1)安装Dify和Ollama服务,配置模型供应商;2)搭建工作流并创建API密钥;3)通过修改YAML文件配置端口映射,将API服务暴露给外部访问;4)测试API接口可用性。整个过程涉及服务部署、网络配置、API调试等关键步骤,最终实现通过本地Dify平台调用大模型服务的目标。

本文介绍了Linux服务器固定IP地址和启动LLM服务的操作指南。第一部分详细说明了固定IP的必要性及图形化配置步骤:先通过命令获取网段、网关等关键信息,然后在网络设置中手动配置IP地址、子网掩码、网关和DNS。第二部分讲解如何启动已部署的LLM服务:先确认ollama版本,可选设置显卡绑定,通过环境变量指定监听地址和端口启动服务,最后测试服务并查看本地模型。全文提供了完整的操作流程,帮助用户实现

本文介绍了vllm的安装部署流程:1)创建Python3.10虚拟环境,安装vllm和PyTorch(需验证CUDA可用性);2)安装flash-attn解决长序列处理的性能问题,并提供测试脚本验证安装;3)演示如何使用modelscope下载Qwen1.5-1.8B模型(支持git lfs管理大文件),并说明删除方法。整个过程涵盖环境配置、依赖安装和模型部署等关键步骤,为高效运行大语言模型提供完

本文详细介绍了Ollama本地部署及Qwen2-32B模型安装过程。首先指导用户下载并解压Ollama 0.17.5版本,通过环境变量配置监听地址和端口,解决服务启动参数不兼容问题。随后介绍Windows环境下安装Ollama客户端,下载Qwen2.5-32B模型的方法。最后讲解如何通过Docker部署OpenWebUI界面,包括端口映射调试和常见错误排查。整个流程涵盖Linux/Windows双
针对现有 NLP 学术知识图谱实体与概念割裂、无法支撑复合型学术问答,且构建标注成本高的痛点,本文提出 NLP-AKG 少样本构建框架。作者限定从摘要、引言与核心实验表提取信息,设计包含 15 类实体、29 种关系的本体,将引用细分为 "直接使用" 与 "任务相关" 两类,仅用少量标注训练轻量模型完成质量校验。在此基础上提出 "子图社区摘要" 方法,通过语义社区划分引导 LLM 分阶段推理。

本文介绍了vllm的安装部署流程:1)创建Python3.10虚拟环境,安装vllm和PyTorch(需验证CUDA可用性);2)安装flash-attn解决长序列处理的性能问题,并提供测试脚本验证安装;3)演示如何使用modelscope下载Qwen1.5-1.8B模型(支持git lfs管理大文件),并说明删除方法。整个过程涵盖环境配置、依赖安装和模型部署等关键步骤,为高效运行大语言模型提供完