- @Python_0011
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
导读 本文将分享 AIAgent 在电商平台中的探索。主要内容包括:LLM 在电商的价值位Agent 解决方案应用架构介绍AI 创新范式预期与规划问答环节分享嘉宾|王卓隽 1688 AI创新产品及应用负责人出品社区|DataFun01LLM 在电商的价值位首先来介绍大模型所赋予电商领域的一些新特性,AI 在电商模式下的应用,以及 1688 对 AIAgent 的探索。1. 大模型赋予的新特性在电商
Cursor 是一款新兴的代码编辑器,它的开发背景与人工智能的快速发展紧密相关。在当下,开发者对于更智能、高效的代码编写工具需求日益增长,Cursor 应运而生。它由一支专注于将 AI 技术融入开发工具的团队打造,旨在通过人工智能辅助,提升开发者的编码体验和效率。在作用方面,Cursor 不仅具备常规代码编辑器的基本功能,如语法高亮、代码补全等,更重要的是它集成了强大的 AI 能力。
白皮书后面还会涉及多Agent架构、高并发架构设计、安全等模块,稍微有些泛泛而谈,而我们今天定位如果是入门级内容的话就不去涉及了。最后还是总结一下,这份Agent白皮书全面梳理了 AI Agent(智能体)技术架构的核心要素,他本身包含一部分实践技巧,但有点卖自己云服务的嫌疑,我们这里就不涉及了。
AI Agent技术正从“炫技”走向“实用”,成为开发者延伸能力的重要杠杆。无论是AutoGen通过对话实现的动态协作,还是LangGraph通过图编排提供的精密控制,都在推动AI从“被动问答”走向“主动执行”。技术的本质是延伸人的能力。Agent延伸的,正是我们规划、协调与执行的综合能力。选择适合的框架,从小处着手,你可以构建出能自动处理邮件、监控日志、生成报告甚至管理项目的数字员工。你现在最希
要理解智能体的运作,我们必须先理解它所处的任务环境。在人工智能领域,通常使用PEAS模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)。以上文提到的智能旅行助手为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。表 1.2 智能旅行助手的PEAS描述在实践中,LLM智能体所处的数
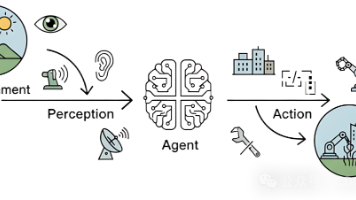
这类是 Agent 入门时首先要理解的核心概念,直接决定系统的协作模式与应用场景。
由于企业知识、应用、业务需求的千差万别,以及大模型自身的不确定性,Agents项目要强调可控性的原因,来让AI按照人类确认过的工作流程来完成任务。
如果把“To B软件的AI化”比作汽车自动驾驶技术的发展,那么2023年LLM的推出,就相当于把To B软件应用的自动化程度从L1阶段提升到了L2阶段;而AI Agent的到来,则让自动化程度更上一层楼,从L2阶段升级到了L4阶段。▲人类与AI协同的三种模式随着AI Agent自主性的不断增强,它将会逐渐取代越来越多的重复性工作。但从To B软件的角度来看,AI最终要解决的核心问题仍然是。
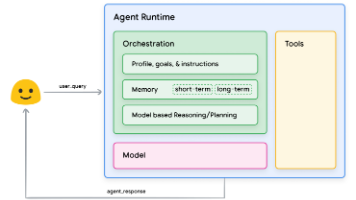
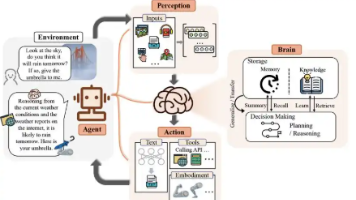
AI Agent(智能体)自主感知:能够理解当前环境和任务需求自主决策:能够制定执行计划并动态调整自主执行:能够调用工具完成实际任务用一句话总结:Agent = LLM(大脑) + 工具(手脚) + 记忆(经验) + 规划(智慧)一个工具的标准结构。
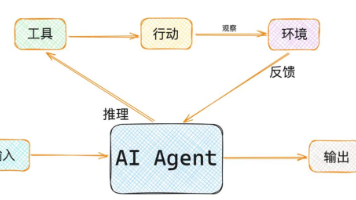
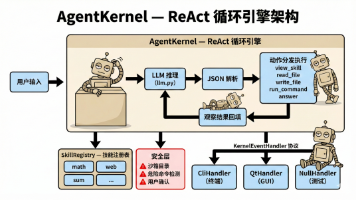
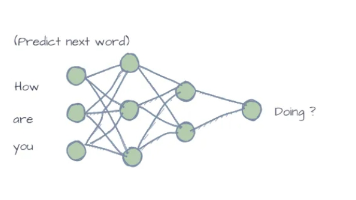
在开始之前,让我先说清楚 Agent不是什么:• 它不是一种新的 AI 模型。它底层用的就是 GPT、Claude、DeepSeek 这些你已经在用的大语言模型。• 它不是什么"具身认知架构"。它就是一个 Python 程序。• 它不需要任何 Agent 框架。LangChain 有 3000+ 个文件,而我们的核心引擎只有 500 行。那 Agent 到底是什么?Agent = LLM + 循环