




- @llg___
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
服务等级目标,指的是设计可用性,其意思即为设计该产品时。:服务等级协议,指的是整个。,其定义了服务类型、质量。

举个例子,摆宴席,云计算可以让你不用自己支架子架锅,即云基础设施IaaS,而自己做饭的这套设施,只能你自己用,即私有云,而你做完了,这个锅别人也可以用,即公有云。首先考虑用物理服务器,如此,需要自己建机房、买服务器、开发系统、专人维护服务器。,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算机资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供。入住以后,你

基于数据库实现配置管理和定时任务启停
在一个分支修改代码后,还没commit提交,不想要这些修改了,想回到刚开始的样子。在一个分支修改代码并commit到了本地仓库,但没push到远程仓库,想回到刚开始的样子。最近一次的push我不要了

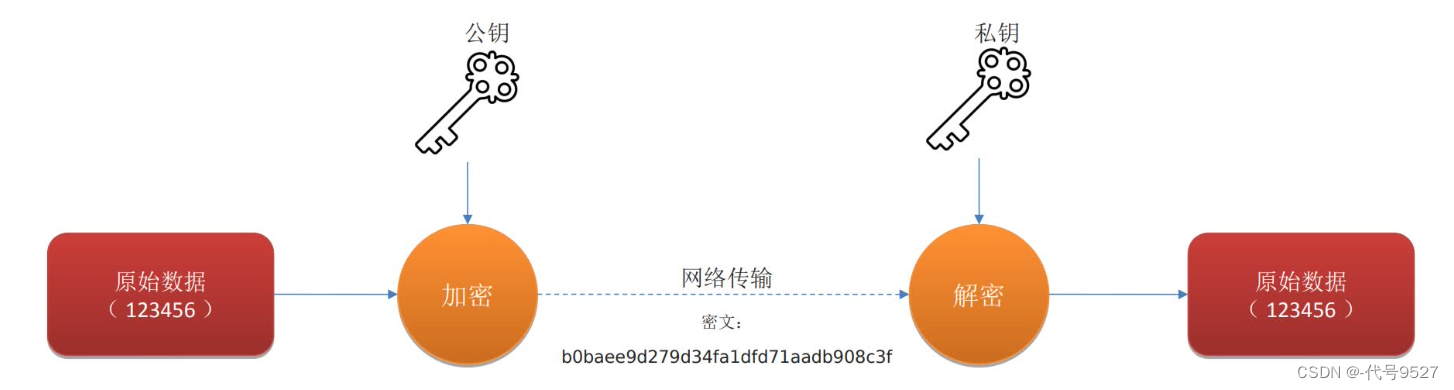
针对以上要加密的数据,用户密码处理的流程图如下:修改注册后端接口,用户注册时,提交密码,前端用公钥对密码进行加密后,传到后端服务器。对邮箱名、手机号等信息,可非对称加密,也可使用AES对称加密,实现加密传输,加密落库则可有可无,如果选择了加密落库,可能会影响到之前的userList接口等等,总之明文、密文别转换叉了。修改后端登录接口,登录时,前端传来的密码,解密后传到SpringSecurity框
发现是docker的overlay2目录占用了大量空间。

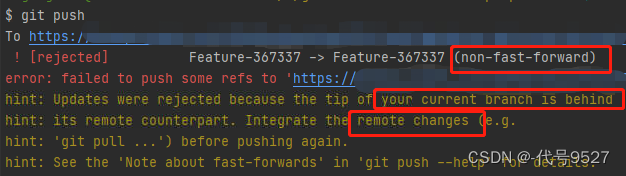
git push报错rejected:no-fast-forward。对于这个改变,你没有拉取到本地,而你又添加了一下新代码。此时你push到远程仓库,检测到你之前从远程仓库拉取时仓库的状态,和现在仓库的状态不一样了。报错中其实已经说明逻辑:the remote changes ⇒ your current branch is behind ⇒ non-fast-forward ⇒ push re
此时,考虑你Dockfile里的基础镜像,它的架构也要对应上。不能做amd下的镜像,但基础镜像却是arm下的。比如我之前使用JDK的镜像,Dockerfile共用一个

服务等级目标,指的是设计可用性,其意思即为设计该产品时。:服务等级协议,指的是整个。,其定义了服务类型、质量。
举个例子,摆宴席,云计算可以让你不用自己支架子架锅,即云基础设施IaaS,而自己做饭的这套设施,只能你自己用,即私有云,而你做完了,这个锅别人也可以用,即公有云。首先考虑用物理服务器,如此,需要自己建机房、买服务器、开发系统、专人维护服务器。,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算机资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供。入住以后,你