




- @qq_22973811
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
hadoop单机版安装
文章目录说明分享资料优势代码实例DataFrame和DataSet的区别总结说明本博客周五更新本文记录spark 分布式数据类型DataSet的基本原理和使用方法。DataSet是Spark1.6添加的分布式数据集合,Spark2.0合并DataSet和DataFrame数据集合API,DataFrame变成DataSet的子集。DataSet继承RDD优点,并使用Spark SQL优化的执行引擎
文章目录说明分享大数据计算引擎批处理MapReducetez流批处理Flinkspark总结说明本博客每周五更新一次。介绍过大数据平台的搭建、应用和存储,本期分享下大数据计算。分享大数据博客列表大数据计算引擎什么是计算引擎?计算引擎就是一种计算规则的高度抽象聚合体,使用者按照指定的方式编写对应接口代码,然后执行就能得到需要的结果(前提没有bug)。大数据计算场景分为两个种:批处理(历史文件)和流处
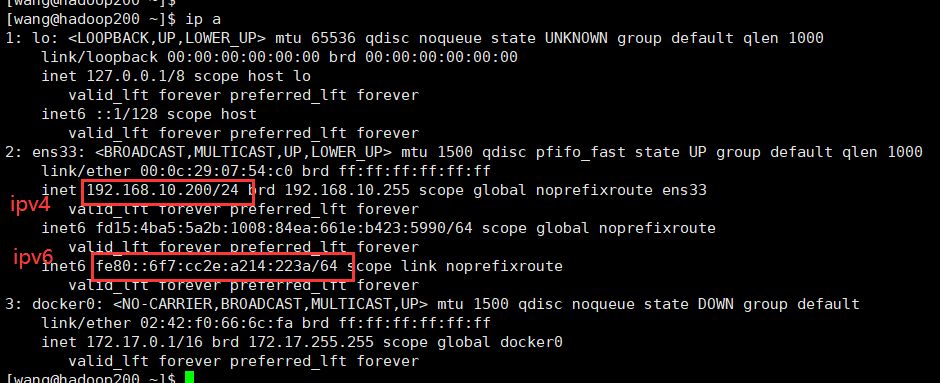
vmware虚拟机配置ipv6网络
文章目录说明分享资料字段类型各类型说明字符串数值型浮点型范围数值类型时间类型binary类型array类型object类型ip类型mapping属性enabledindexindex_option_sourcenormsalldoc_valuefielddatastorecoercemultifieldsdynamicdata_detectionanalyzerboostfieldsignore_
文章目录术语TableRowColumn Family(列簇或列族)ColumnColumn QualifierCellTimestamp标识设计要点hbase与关系型数据库对比设计时考虑因素设计要点行键rowkey设计列簇设计列簇属性总结术语TableHbase的table由多个行组成。Row一个行在Hbase中由一个或多个有值的列组成。Row按照字母进行排序,因此行键的设计非常重要。这种设计方
文章目录说明分享资料服务主页安装普通方式安装系统配置安装软件软件配置elasticsearch.ymljvm.options启动并验证安装kibana用户认证开启x-pack验证创建内容用户访问测试设置密码忘记密码kibana关联账号和密码https加密传输层加密添加证书ElasticSearch开启httpsElasticsearch与Kibana 加密连接Kibana 开启https建议总结说
文章目录说明运行环境搭建步骤下载安装包配置安装配置server.properties说明启动启动zookeeper启动kafkakafka脚本脚本说明脚本使用kafka功能测试端口说明创建topic主题创建生产者创建消费者kafka版本兼容性总结说明本博客每周五更新一次。本片博文主要介绍win10安装kafka过程,官方脚本说明和数据生成、接受测试,实践性强。运行环境jdk 1.8kafka 2.