- @weixin_45695430
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定义样例类 OrderEvent,这是输入的订单事件流;另外还有 OrderResult,这是输出显示 的 订 单 状 态 结 果 。 订 单 数 据 也 本 应 该 从 UserBehavior 日 志 里 提 取 , 由 于UserBehavior.csv 中没有做相关埋点,我们从另一个文件 OrderLog.csv 中读取登录数据_大数据培训。...
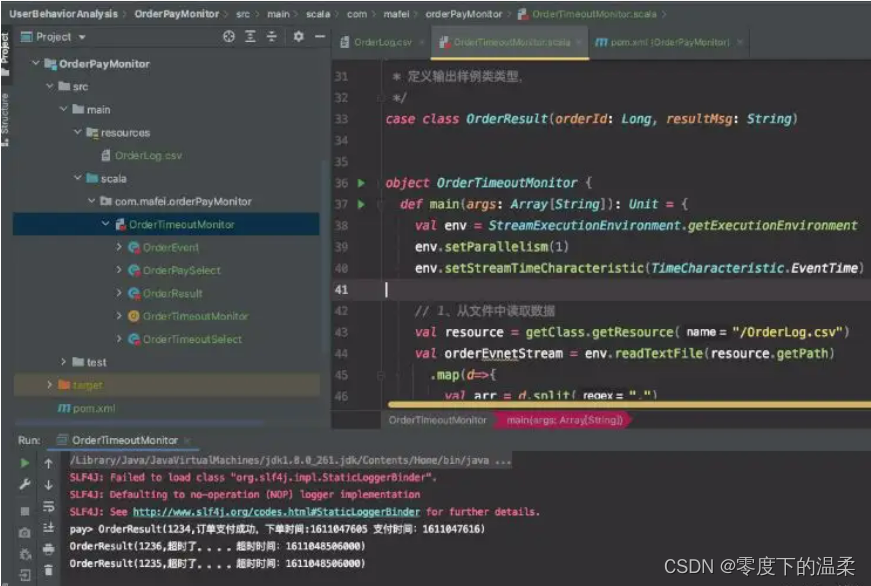
定时任务关闭超时订单是在创建订单之后的一段时间内未完成支付而关闭订单的操作,该功能一般要求每笔订单的超时时间是一致的。如果我们使用定时任务来进行该操作,很难把握定时任务轮询的时间间隔:时间间隔足够小,在误差允许的范围内可以达到我们说的时间一致性问题,但是频繁扫描数据库,执行定时任务,会造成网络IO和磁盘IO的消耗,对实时交易造成一定的冲击;时间间隔比较大,由于每个订单创建的时间不一致,所以上边的一
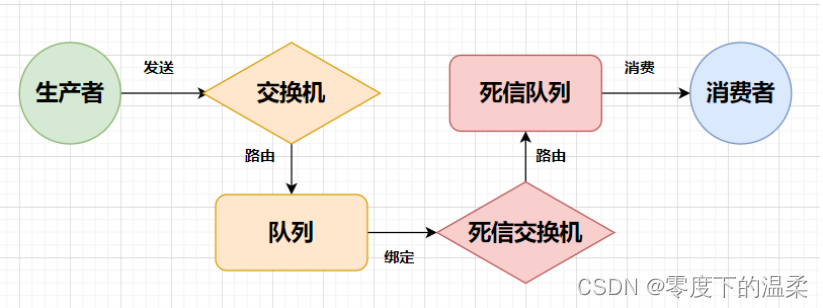
以下文章来源于涤生大数据1 Hive有哪些参数,如何查看这些参数Hive自带的配置属性列表封装在HiveConfJava类中,因此请参阅该HiveConf.java文件以获取Hive版本中可用的配置属性的完整列表。具体可以下载hive.src通过eclipse查看。全部属性有上千个吧,一般Hive的自带属性都是以hive.开头的,每个属性且自带详细的描述信息,其次Hive官网也有,但是属性不是特别

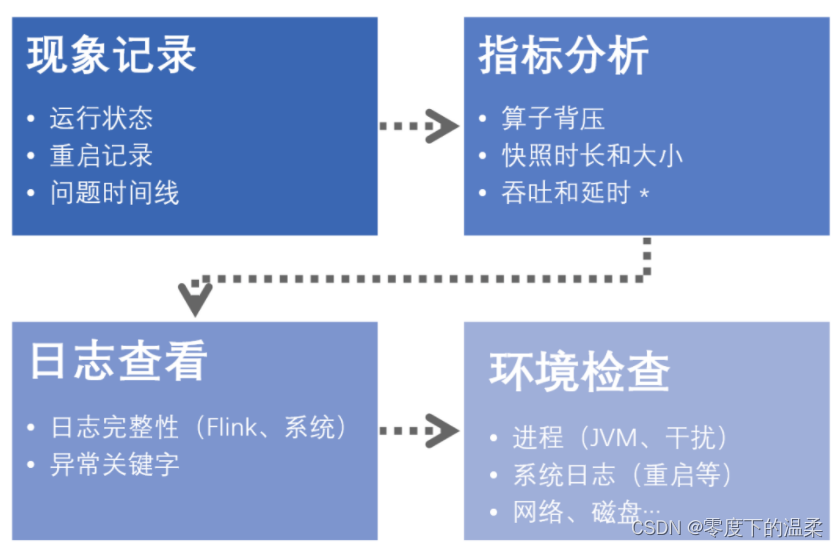
一、问题分析概览流计算作业通常运行时间长,数据吞吐量大,且对时延较为敏感。但实际运行中,Flink 作业可能因为各种原因出现吞吐量抖动、延迟高、快照失败等突发情况,甚至发生崩溃和重启,影响输出数据的质量,甚至会导致线上业务中断,造成报表断崖、监控断点、数据错乱等严重后果。本文会对Flink 常见的问题进行现象展示,从原理上说明成因和解决方案,并给出线上问题排查的工具技巧,帮助大家更好地应对 Fli
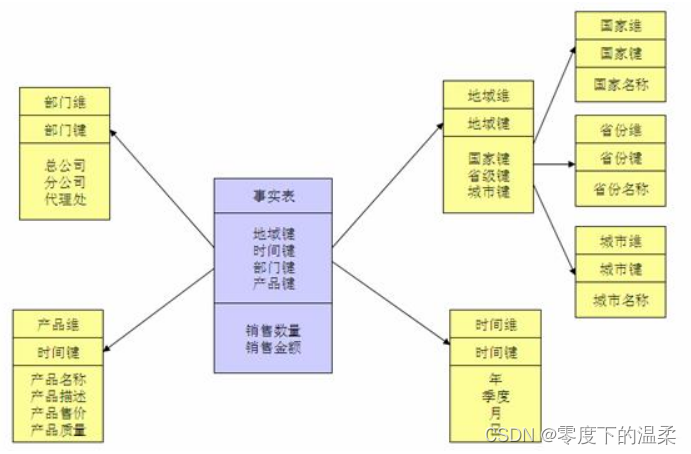
我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如 Teradata ),抑或是基于传统 Oracle 、MySQL 、SQL Server 关系型数据库的数据仓库,其实都面临如下问题:怎么组织数据仓库中的数据?怎么组织才能使得数据的使用最为方便和便捷?怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?Kimball 维度建模理论很好地回答和解
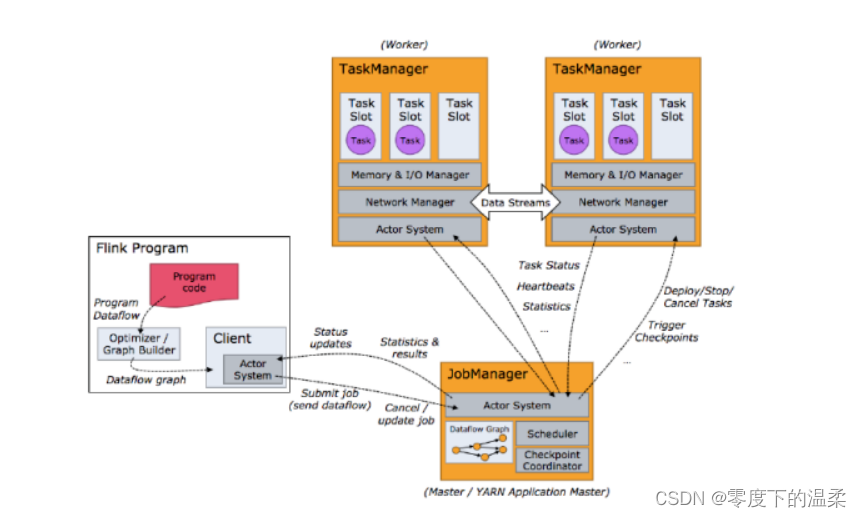
前言这篇文章应先以了解flink组件为开始,再以简单模式Local 和 Standlone 正式进入正题。本篇主要是以Yarn 方式下三种模式展开细讲,当然还有Kubernetes方式(本篇不细说)。组件在了解提交模式之前,先了解一下Flink组件与组件之间的协作关系。资源管理器(Resource Manager)(1)主要负责管理任务管理器TaskManager的插槽slot。(2) 当作业管理
1. 通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别(1)spark把运算的中间数据(shuffle阶段产生的数据)存放在内存,

在 src/main/目录下,可以看到已有的默认源文件目录是 java,我们可以将其改名为 scala。将数据文件 UserBehavior.csv 复制到资源文件目录 src/main/resources 下,我们将从这里读取数据_大数据培训。

1. 简单介绍一下FlinkFlink是一个面向流处理和批处理的分布式数据计算引擎,能够基于同一个Flink运行,可以提供流处理和批处理两种类型的功能。 在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流。2. Flink的运行必须依赖Hadoop组件吗Flink可以完全独立于Hadoop,在不依赖Hadoop组件下运行。但是
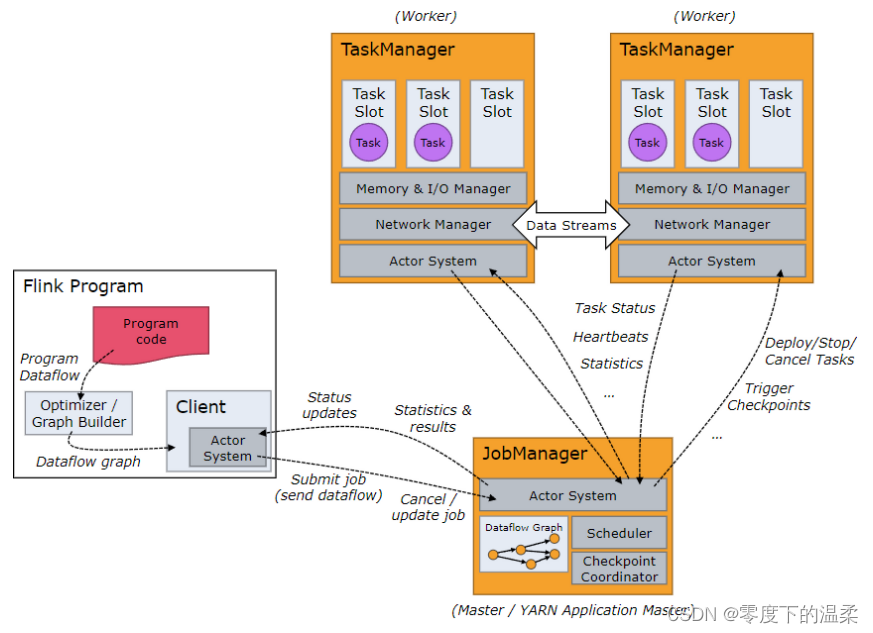
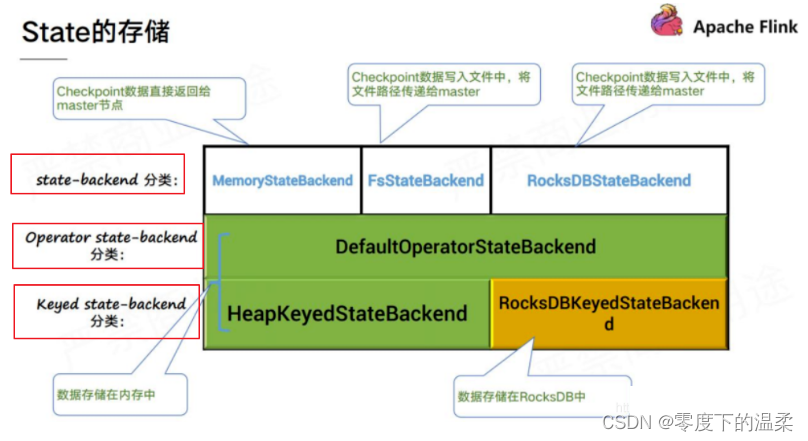
用户在配置 rocksdb 时,会使用 RocksdbKeyedStateBackend 去管理状态;用户在配置 memory,filesystem 时,会使用 HeapKeyedStateBackend 去管理状态。因此就有了这个问题的结论,配置 rocksdb 只会影响 keyed-state 存储的方式和地方,operator-state 不会受到影响_大数据培训。...