登录社区云,与社区用户共同成长
邀请您加入社区
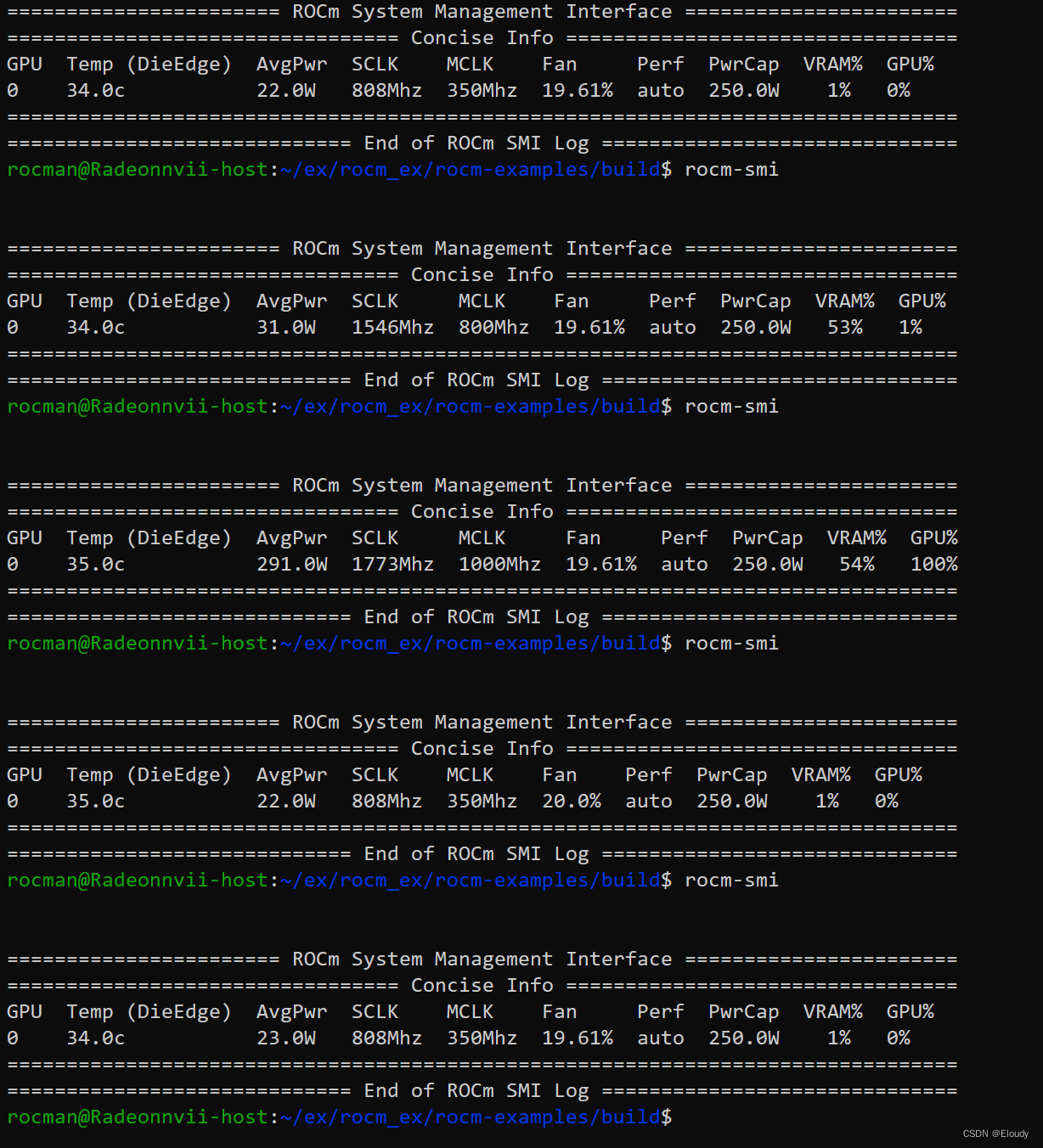
1. 压力方程求解器的选择与优化代数多重网格法(AMG)压力方程(泊松型)的求解通常占主要计算时间,AMG对这类椭圆型方程具有最优的收敛速度(接近O(n))。优先选用基于AMG的求解器(如Hypre、PETSc或开源库AMGCL)。调整AMG参数:粗化策略(Ruge-Stuben或PMIS)、平滑迭代次数(通常1-2次Gauss-Seidel)、循环类型(V-cycle比W-cycle更快)。Kr
本文主要研究测试abaqus-2022如何在Linux并行计算集群安装与简单使用。
本文详细介绍了生产级轻量Slurm集群的搭建流程。集群采用标准架构,包含控制节点、计算节点、登录节点和存储节点,支持x86_64架构的CPU/GPU节点。搭建过程分为七个步骤:1)存储节点搭建NFS共享存储;2)控制节点安装MySQL、Slurm核心服务并配置调度系统;3)计算节点部署slurmd服务;4)登录节点配置用户环境;5)集群功能验证;6)日常维护命令;7)生产优化建议。关键配置包括Mu
本文主要介绍,主流CAE仿真软件,如大型有限元分析软件ANSYS FLUENT、ANSYSMECHANICAL、ANSYSCFX、ANSYSLS-DYNA,ABAQUS、HFSS、NASTRAN、CST、STAR-CCM+、NUMECA、FEKO、COMSOL在HPC或Linux并行计算集群上如何使用pbs或slurm作业调度系统脚本提交作业以及如何使用软件在命令行提交作业,旨在帮助初入科研行业的
关于OpenLavaOpenLava是100%免费、开源、兼容IBM® Spectrum LSFTM的工作负载调度器,支持各种高性能计算和分析应用。伴随成千上万次的下载和安装,OpenLava的可扩展性和健壮性已经在拥有数十万个内核和和几百万作业的集群上得到了验证。由于OpenLava的命令行和文件格式与大多数LSF功能相兼容,因此用户和管理员都将非常熟悉OpenLava的操作。组织和
本文主要介绍Gaussian软件在Linux或HPC并行计算集群上安装与使用,Gaussian是做半经验计算和从头计算使用最广泛的量子化学软件,可以研究分子能量和结构、过渡态的能量和结构、化学键以及反应能量、分子轨道、偶极矩和多极矩、原子电荷和电势、振动频率、红外和拉曼光谱、NMR、极化率和超极化率、热力学性质、反应路径等。
本文主要介绍了分子动力学模拟软件GROMCAS的作用及特性,详细安装步骤等。
本文深入解析Dragonfly拓扑中UGAL路由算法的实战配置与调优,针对对抗性流量导致的网络性能问题,详细探讨了UGAL-G与UGAL-L的核心差异、虚拟通道配置、偏移常数T的动态调整策略以及缓冲区与信用延迟机制的协同优化。通过实际案例和配置示例,帮助网络架构师在高性能计算集群中实现负载均衡和性能提升。
工业仿真从来不是单兵作战——复杂模型的多方协作、海量数据的跨团队流转,才是研发场景的常态。为此,SimForge™平台推出「共享空间」功能,打破传统孤岛式研发模式,为仿真团队构建云端协同中枢,让数据流转与知识沉淀更安全、更智能。
GPT系列、BERT等AI大模型,以其在自然语言处理、计算机视觉等多个领域的卓越表现,成为了当今人工智能领域的焦点。这些模型通过海量的数据进行训练,能够学习到复杂的模式和语义信息,从而在各种任务中展现出惊人的泛化能力。要将这些大模型成功应用到实际场景中,从模型的训练到部署,每一个环节都面临着严峻的挑战。高性能计算HPC作为一种强大的计算手段,为解决AI大模型应用落地提供了可能。
是由法国数据分析公司QuantStack主导维护的一套现代 C++ 数值计算生态开源组织,对标 Python NumPy、MATLAB、Eigen,但更侧重现代 C++、向量化 SIMD、零开销抽象、跨平台、高性能科学计算。官网:https://github.com/xtensor-stack把 Python 式简单易用的数组语法,搬到高性能 C++,兼顾易用性 + 极致性能。
prerequisite 中也有操作;
作为年度活动,Future.Industry 始终致力于打造全球科技创新者的思想盛宴。通过与全球行业先锋和知名企业高管共同探索仿真、人工智能、数据分析和高性能计算等前沿领域的技术突破与商业实践,我们持续推动行业迈向智能化未来。
是数值线性代数与高性能计算领域的杰出青年学者,目前担任布拉格查理大学数学与物理学院数值数学系副教授。她于2025年荣获数值分析领域最高荣誉之一的。:数值线性代数、混合精度算法、通信避免算法 (s-step Krylov 方法)、Krylov 子空间方法的数值稳定性。的计算趋势,核心是设计能适应当代多精度、异构硬件架构(如 GPU、AI 芯片)的数值算法。资助领导 InEXASCALE 项目。以下是
IDAES(Institute for the Design of Advanced Energy Systems)是美国能源部(DOE)旗下、由国家能源技术实验室(NETL)主导开发的开源过程系统工程(PSE)平台,2016年正式启动,核心用于先进能源系统的多尺度建模、仿真与优化。定位:填补商用模拟器(如Aspen)与通用代数建模语言(如Pyomo)之间的空白,专注复杂能源/化工过程的设计、强化
(Huawei Zürich Research Center)计算系统实验室的研究科学家与专家(Research Scientist and Expert)[[2]][[8]]。博士是一位专注于高性能计算与并行编程模型研究的计算机科学家,目前担任。
还在用 scontrol 和 sinfo 手动查集群状态?SlurmInsight 是一款专为 Slurm 调度系统打造的 Web 可视化监控平台。从仪表盘到节点热图,从作业队列到历史趋势,让 HPC 集群管理像看仪表盘一样简单。即将开源,敬请关注!
MPI Sessions 是MPI-4.0 新一代并行执行模型,彻底替代传统全局初始化模型,专门解决多物理场耦合、多求解器独立运行、动态资源划分、异构GPU/CPU分区、FSI液固耦合等复杂场景。结合你之前学的MPI Partitioned分区通信、CUDA-aware GPU通信,本文一次性讲清原理、API、标准流程、FSI双向流固耦合完整工程实现。模块作用FSI耦合用途独立MPI环境流体/固体
NVIDIA HPC-X 并不是一个孤立的 MPI 变体,而是一个由 NVIDIA (原 Mellanox) 提供的高性能通信软件工具包。[1, 2]它通过将开源组件与专有加速技术“打包”并进行深度调优,为基于 InfiniBand 网络的集群提供极致性能。[3, 4]
欧洲超算 CFD 旗舰:把传统CFD推向百亿亿次工业+学术双驱动:兼顾基础算法与工程应用全链路覆盖:代码→算法→硬件适配→工业验证开源开放:所有改进回馈社区,可直接用于你的相变/沸腾/冷凝研究欧洲CFD全面上Exascale:5大旗舰代码GPU化+千万核+低能耗相变/多相流工业化沸腾/冷凝/凝固从实验室走向百亿亿次工程开源回馈:所有优化合并回主线工业落地:6大领域达TRL 4–5,直接用于航空、能
FrontISTR 是日本开源、大规模并行非线性结构有限元求解器,主打超算/集群高效并行,适合大模型、非线性、高算力需求场景,MIT 协议可商用二次开发。FrontISTR(开源大规模并行非线性结构有限元程序)开发背景:日本文部科学省下一代 IT 基盘仿真软件项目成果维护主体:FrontISTR Commons 社团MIT 开源许可,个人/商用/二次开发自由超大规模并行、强非线性、超算/集群友好、
TCLB(CUDA Lattice Boltzmann)是一款基于格子玻尔兹曼方法(Lattice Boltzmann Method, LBM)的高性能计算流体动力学(CFD)仿真代码,由华沙理工大学的 Zakład Aerodynamiki 团队主导开发,核心目标是为复杂物理场计算和新模型实现提供高效、灵活的框架。
发起:2001 年,由 Prof. Dhabaleswar K. (DK) Panda 团队主导定位:基于 MPICH 架构(ADI3 通道),专注RDMA 网络 + HPC 场景的高性能 MPI 库BSD 开源许可(商用友好)现状:全球超 3200 家机构、89 个国家使用,大量 TOP500 超算采用MVAPICH 是RDMA 网络 HPC 的性能标杆,在 InfiniBand/GPU 超算场
Georg Hager = HPC性能优化领域的“宗师”他以LIKWID、ECM模型、Node-Level Performance Engineering三大里程碑,定义了现代HPC性能工程的方法论与工具链,是全球超算与科学计算开发者必须了解、学习、致敬的标杆人物。
Spack软件包管理器
HPCToolkit工具使用
DEM商软比较
云上高性能计算满足生命科学对于算力规模、高性能等业务需求,助力其快速发展。
在生物工程领域,搅拌釜生物反应器是细胞培养、发酵工艺开发的核心装备。其内部流场均匀性、氧传递效率及剪切力分布的精准控制,直接关系产物收率与工艺稳定性。然而,传统仿真手段在应对多相流耦合、瞬态动力学分析等高复杂度场景时,常因算力资源不足导致模型简化过度、收敛困难,甚至被迫牺牲仿真精度。
本文从工程痛点出发,深度解构了 SaaS 化通风仿真平台底层的核心计算理论。
将以上所有层次综合起来,我们可以得到一张完整的NVLink/NVSwitch通信协议栈视图。这张图清晰地展示了从最底层的物理连接到最顶层的应用,以及贯穿始终的控制平面,是如何共同构成一个强大、高效的系统的。NVLink/NVSwitch协议栈本质上是一个为AI和高性能计算(HPC)工作负载量身定制的、全栈式协同设计的、高性能互联系统。它通过简化协议、地址直通、网络内计算和强大的软件控制,将成千上万
“风神NF3”数字孪生风洞是神工坊®CAE“基座+应用”生态的里程碑,本文将深度解析其背后的两大核心技术——HSF-SAMR网格自适应与HSF-AI智能求解技术,看它们如何让仿真从“能算”进阶为“智能算”。
IBM Spectrum LSF 是 IBM 旗下的一款分布式集群管理软件,主要是负责资源调度和批处理作业的调度,提供强大的资源管理功能来优化应用程序性能和最大限度提高资源使用率。IBM Spectrum® LSF Suites 提供完全集成的 UI 体验,通过易于使用和简化的操作,提高用户的生产力。该产品旨在提高生产力,为用户提供了更多访问 HPC 资源的方法,包括用于作业监控和通知的移动客户端
离散元法(DEM):模拟大量刚性颗粒之间的接触力、碰撞、摩擦、滚动阻力等。刚体动力学:支持复杂几何体的运动和相互作用。耦合求解器:可与有限元法(FEM)、流体动力学(CFD)耦合(通过LBM等)。自定义材料模型:支持用户定义接触模型(如Hertz-Mindlin、Linear Elastic、Cohesive等)。可视化与后处理:内置OpenGL可视化器,支持导出VTK、CSV等格式。脚本驱动:使
OpenFAST 是一款由美国国家可再生能源实验室(NREL)开发的开源风力涡轮机仿真工具,用于对陆上和海上风力涡轮机进行全系统建模和仿真。
开源 FEM(有限元分析)工程有很多,涵盖结构力学、热传导、电磁场、流体力学等多个领域。这些项目大多托管在 GitHub/GitLab 或自有网站上,可直接下载源码或预编译版本。(C++/自己的脚本语言)
调试 MPI 程序是高性能计算中的关键环节,由于其并行、分布式特性,调试比串行程序更具挑战性。这些工具和方法可显著提升 MPI 程序的开发效率与稳定性。
随着算法的不断优化和创新,GPU算力将在更多未知的领域展现出强大的应用潜力,为人类解决前所未有的复杂问题,创造更多难以想象的价值。它具有较高的时钟频率和复杂的缓存层次结构,能够高效地执行单个线程的指令,对于顺序执行的任务,如操作系统的运行、通用计算中的复杂算法等,表现出色。无论是自然语言处理中的语言模型,还是计算机视觉中的图像识别和目标检测模型,亦或是强化学习中的智能体训练,GPU算力都为其提供了
当我们豪掷千万购置顶级GPU,部署200G超高速网络,却因一个小小的SATA SSD选择,让整个系统的实际性能只剩下理论值的30%——元数据性能,这个最容易被忽视的细节,正在成为医疗超算平台的“阿喀琉斯之踵”。
它由一系列可移植、模块化的 C++ 库组成,适用于使用。:整个框架以库的形式提供,可灵活集成到新项目或已有代码中。:支持与非结构化网格耦合,用于多尺度或多物理场问题。这些求解器均为开源,可直接使用或作为开发模板。:提供从 CAD 几何自动构建计算网格的能力。,使开发者能更专注于物理建模与算法逻辑。(FVM)进行数值模拟的场景,同时。Overture 之上构建了名为。Overture 是一个。
HPC
——HPC
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵





 脑启社区
脑启社区

 AtomGit开源社区
AtomGit开源社区



 AMD开发者中国社区
AMD开发者中国社区




 九章云极普惠算力
九章云极普惠算力





 魔乐社区
魔乐社区



 2048 AI社区
2048 AI社区

 智能体开发者社区
智能体开发者社区
