登录社区云,与社区用户共同成长
邀请您加入社区
本文档详细记录了在3台虚拟机(2C/4G配置)上搭建Hadoop高可用集群的完整过程,包括基础环境配置、ZooKeeper集群部署和Hadoop HA集群部署。主要内容涵盖:1)主机名、SSH免密、JDK安装等基础配置;2)ZooKeeper集群的安装、配置与启动;3)Hadoop 3.3.5的环境变量设置、关键参数优化及核心配置文件修改。文档特别强调了配置过程中的常见问题与解决方案,如JAVA_
本文详细介绍了Hadoop HDFS的核心参数配置、集群性能优化及故障处理方法。主要内容包括:1)NameNode内存配置与心跳并发优化;2)HDFS集群压测方法,包括读写性能测试;3)集群扩容缩容操作,如白名单/黑名单管理、数据均衡;4)存储优化方案,如纠删码和异构存储技术;5)常见故障排查指南;6)MapReduce性能调优参数;7)小文件处理策略。通过实际案例展示了从1G数据统计词频的完整调
协程是一种可以暂停和恢复执行的函数,它允许在执行过程中临时放弃控制权,稍后从中断点继续执行。与线程不同,协程的切换由程序员显式控制,不涉及操作系统调度,因此开销极小。C++20协程是语言进化的一个重要里程碑,它为异步编程提供了强大的工具。然而,其复杂性也使其成为C++中最难掌握的特性之一。在决定是否使用协程时,开发者需要权衡其优势与实现成本,做出符合项目需求的合理选择。
随着生成式AI的发展,传统模型在维度处理(如文本、图像的高维特征)中面临效率和准确性的瓶颈。本文从数据维度过滤的算法解析出发,逐步构建一个能理解用户习惯、动态调整响应策略的个性化虚拟助手,最终实现从代码到应用的落地。通过将AI的新维度假设转化为可操作的Python代码,并融入用户画像系统,本文演示了如何建立一个具备动态特征调整能力的虚拟助手。print(f原始维度激活值总和:{x.sum():.2
在SIP项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多线程处理模式来分析统计,在我从前写的文章《Tiger Concurrent Practice —日志分析并行分解设计与实现》中有所提到。但是由于统计的内容暂时还是十分简单,所以就采用Memcache作为计数器,结合MySQL就完成了访问控制以及统计的工作。然而未来,对于海量日志分析的工作,还是需要有所准备。现在最火的技术词汇莫
这个atomicAdd操作相当于让每个线程在计算密度场时顺手投票,全局计数器phase_counter每1000步通过cudaMemcpyAsync异步传回主机端,配合Python的matplotlib就能画出动态曲线。把这些技术堆叠起来,模拟页岩油在压裂液驱动下的流动时,能看到明显的指进现象——水相像树根一样在复合材料中蜿蜒前进,而饱和度曲线实时跳动就像流体在显卡里跳踢踏舞。table可以通过C
Spark的三种提交模式:1、standalone模式,基于Spark自己的Master-Worker集群。2、第二种,是基于YARN的yarn-cluster模式。3、第三种,是基于YARN的yarn-client模式。
Yarn资源调度器是Hadoop的核心组件,负责集群资源管理和任务调度。其核心架构包括ResourceManager、NodeManager、ApplicationMaster和Container。Yarn支持三种调度器:FIFO、Capacity和Fair。通过配置yarn-site.xml等文件,可以调整队列资源分配、容器内存等参数。实际案例展示了如何配置多队列资源分配、任务优先级设置以及公平
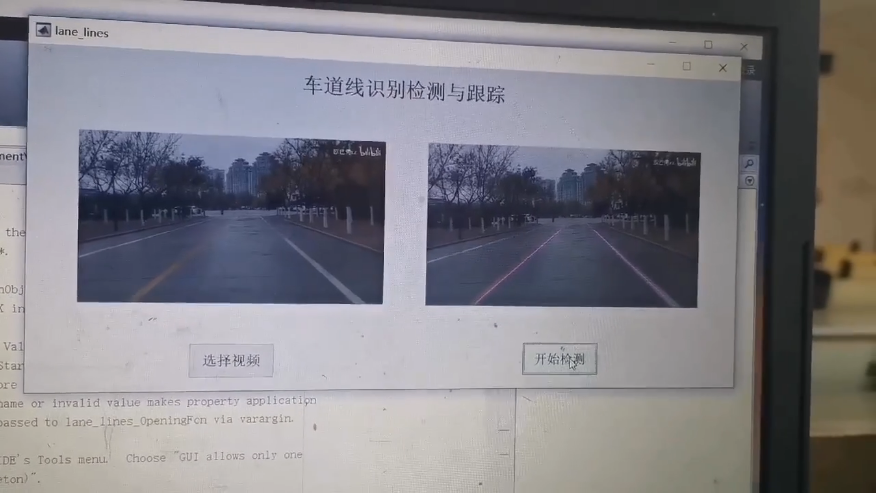
车道线检测matlab工程文件,gui界面,图像处理,图像分割,实时视频检测,霍夫变换,具体效果可看主页演示视频,程序包运行,欢迎打扰。。。最近在研究车道线检测相关的项目,今天就来和大家分享一下基于Matlab实现车道线检测的超酷工程文件,还带GUI界面哦,这一套搞下来,实时视频检测车道线不是梦!
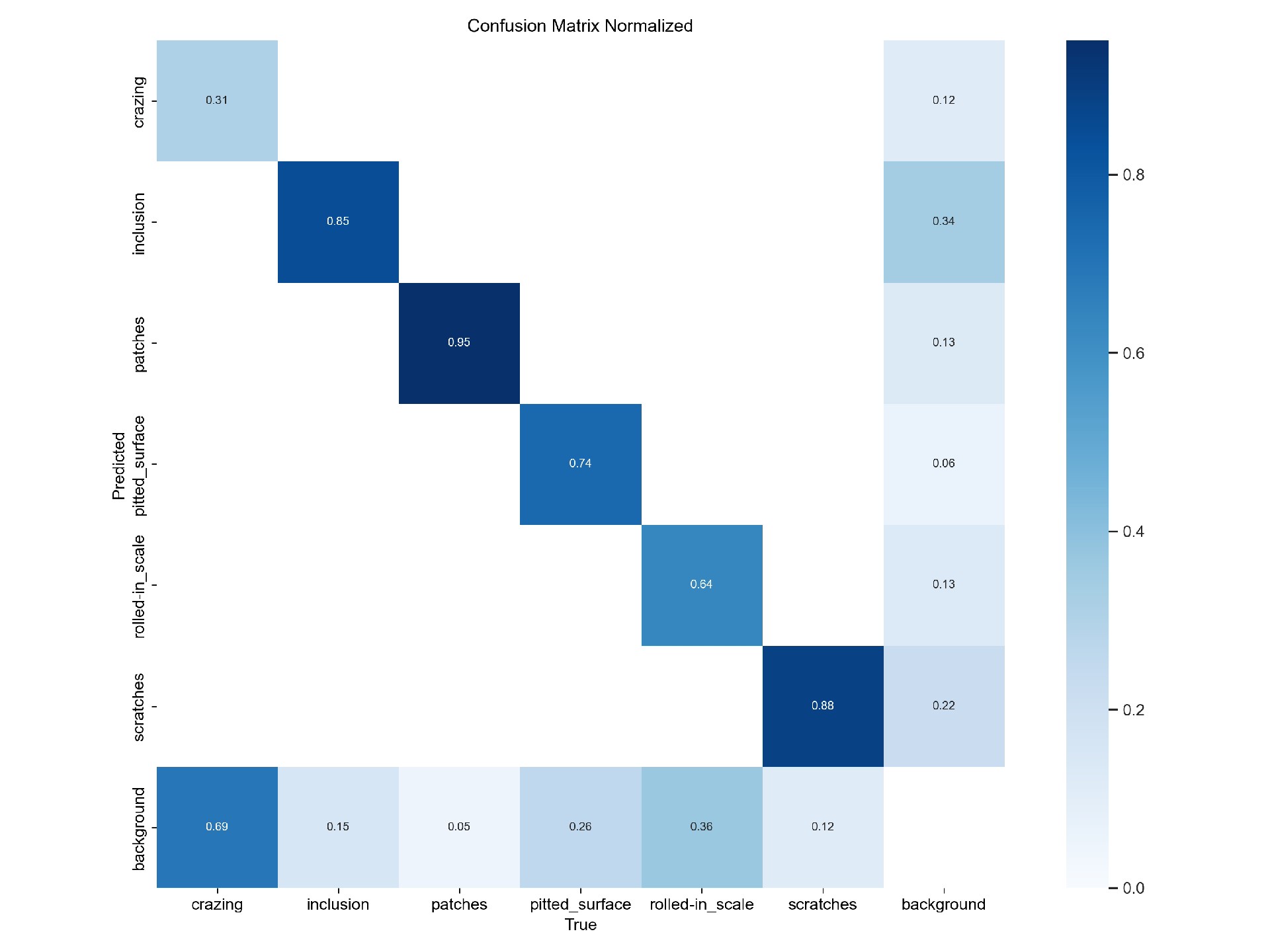
DL00612-基于YOLOv8的钢材表面缺陷检测含数据集处理东北大学(NEU)表面缺陷数据集,收集了热轧带钢6种典型的表面缺陷,即轧内垢(RS)、斑块(Pa)、裂纹(Cr)、点蚀面(PS)、夹杂物(In)和划痕(Sc)。该数据库包括1800张灰度图像:6种不同类型的典型表面缺陷各300个样本。6种典型表面缺陷的样本图像,每张图像的原始分辨率为200×200像素。从图中,我们可以清楚地观察到类内缺
话说回来,他们的深度学习模块训练出来的模型,部署时要注意输入图像的归一化方式,有个学员用OpenCV做预处理结果不准,后来发现海康的归一化是除以255再减0.5,和常规做法不一样。整套资料里最值钱的是那套通讯故障排查手册,像三菱PLC的FX5U偶尔会报"无法建立连接",手册里写着要改GX Works3里的以太网模块参数,把TCP保持连接时间从默认120秒改成0(无限)。所以算法优化真不一定是代码层
19/04/17 02:54:57 ERROR client.TransportClient: Failed to send RPC RPC 7651764253676103503 to /10.169.12.139:45996: java.nio.channels.ClosedChannelExceptionjava.nio.channels.ClosedChannelException...
文章目录Hadoop概述组成1. 分布式存储系统HDFS(Hadoop Distributed File System)2. 资源管理系统YARN3. 分布式计算框架MapReduceHadoop生态圈1. Hive2. pig3. Mahout4. Hbase5. Zookeeper6. Sqoop7. Flume8. OozieHDFS概述1. 设计思想2. 主从架构解析2.1 ==namen
spark常用的启动方式一、Local(本地模式) Spark单机运行,一般用于开发测试。可以通过Local[N]来设置,其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。spark-submit 和 spark-submit --master local 效果是一样的,同理spark-shell 和 spark-shell --..
一、集群规划因为伪分布式集群已经搭建好,所以打算将那个集群改造成ha集群集群规划:节点名称NNJJNDNZKFCZKRMNMhadoop1NameNode...
hadoop集群正常启动,日志无任何错误。而8088端口不能访问。则需要为yarn-site.xml文件添加一下属性。并重新执行start-yarn.sh。修改配置文件---yarn-site.xml,将下列属性添加<property><name>yarn.resourcemanager.address</name>
我们在hadoop集群一般需要在工作台查看日志,但是工作台查看日志一般会出现以下情况:上面的原因是由于yarn的日志监控功能默认是处于关闭状态的,需要我们进行开启,开启步骤如下:一、在yarn-site.xml文件中添加日志监控支持该配置中添加下面的配置:<!-- 开启日志聚合 --><property>...
1、在idea上先写好,自己的代码并进行测试,这里贴一个很简单的统计单词个数的代码package sparkimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]) {/...
两台用的都是ubuntuIP主机名192.168.22.137spark-master192.168.22.150spark-slave1更改主机名确定每个节点的主机名与它在集群中所处的位置相同如果不同,需要修改vi /etc/hostname重启生效可能需要些安装某些工具包更换sources源...
hadoop-3.0.1编译上和原来有不同的地方,部署时,也有一些需要注意的地方。安装部署过程一笔带过:a)设置免秘钥登录。b)设置jdk环境变量。c)配置编译好的hadoop环境变量,HADOOP_HOME,YARN_HOME,HADOOP_CONF_DIR,LD_LIBRARY_PATH,YARN_CONF_DIR。d)配置core-site.xml,hdfs-site.xml,mapred-
额。。。本人菜鸡一只,强行记录点东西,分享一下,也怕自己脑子不好使,忘记了~如果有说错的,还请大家指出批评!!前言:spark的运行模式有很多,通过--master这样的参数来设置的,现在spark已经有2.3.0的版本了,运行模式有mesos,yarn,local,更好的是他可以和多种框架做整合,2.3的版本也新增了Kubernetes。。。言归正传,讲下我所做的测试:测试的代码如下(用的是sp
haoop的起源Hadoop是Apache软件基金会的顶级开源项目,是由原雅虎公司Doug Cutting根据Google发布的学术论文而创建的开源项目。Doug Cutting被称为Hadoop之父,他打造了目前在云计算和大数据领域里如日中天的Hadoop。Hadoop的发音是[hædu:p],Hadoop 这个名字不是一个缩写,而是一个虚构的名字。Doug Cutting解释
1 spark on yarn常用属性介绍属性名默认值属性说明spark.yarn.am.memory512m在客户端模式(client mode)下,yarn应用master使用的内存数。在集群模式(cluster mode)下,使用spark.driver.memory代替。spark.driver.cores1在集群模式(cluster mo
环境:hadoop2.7.4spark2.1.0配置完spark-historyserver和yarn-timelineserver后,启动的时候没有报错,但是在spark用./spark-submit –class org.apache.spark.examples.SparkPi–master yarn–num-executors 3–driver-memo
本篇文章是在Linux上装HDFS最全的教程,适合众多新手和老手学习
问题描述今天在yarn上跑一个hadoop任务时,通过yarn的web管理后台(serveraddress:8088)想查看该任务的的任务时,发现提示如下错误:Java.lang.Exception:Unknown container.Container either has not started or has already completed or doesn;t belong to t
先推荐一个超级棒的教程:厦门大学大数据实验室Hadoop官方文档:Apache Hadoopapark安装和测试:Spark快速入门指南 – Spark安装与基础使用0.cetos6.0安装软件时get-apt命令不可用红帽系列用yum命令安装软件1.在别人之前配置过的机器上重新配置的时候,datanode无法启动(通过jps查看)无法创建datanode这个文件夹,也不生成data
单机上可以本地模式运行单机上伪分布式模式运行集群上standalone模式,spark on yarn模式,spark on mesos模式,这里主要介绍集群前两种。standalone模式类似于单机伪分布式模式,如果是使用spark-shell交互运行spark任务或者使用run-example运行官方示例,driver是运行在master节点上的。如果使用spark-submit进行任务
启动hadoop有两种方式:(1)分别启动HDFS、YARN(2)同时启动HDFS、YARN1.方式一首先启动HDFS:start-dfs.sh(第一次启动时中间过程需要输入yes)然后启动YARN:start-yarn.sh查看启动进程:jps2.方式二启动全部start-all.sh3.关闭hadoopstop-...
WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources执行spark作业在yarn上时,一直提示以上信息,通过yarn RM
spark on yarn +hue搭建
14/04/29 02:45:07 INFO mapreduce.Job: Job job_1398704073313_0021 failed with state FAILED due to: Application application_1398704073313_0021 failed 2 times due to Error launching appattempt_1398704073
Hadoop=HDFS+Yarn+MapReduce+Hbase+Hive+Pig+… 1.HDFS:分布式文件系统,隐藏集群细节,可以看做一块儿超大硬盘 主:namenode,secondarynamenode 从:datanode 2.Yarn:分布式资源管理系统,用于同一管理集群中的资源(内存等) 主:Resourc
zeppelin 官网提供的binary包不支持yarn,需要自己打包。问题zeppelin打包:~/apache-maven-3.3.1/bin/mvn clean install -DskipTests一直build failure:[ERROR] Failed to execute goal com.github.eirslett:frontend-maven-plugin:0.0.2
搭建一个分布式的hadoop集群环境,下面是详细步骤,使用cdh5 。提示:如果还不了解Hadoop的,可以下查看这篇文章Hadoop生态系统,通过这篇文章,我们可以首先大致了解Hadoop及Hadoop的生态系统中的工具的使用场景。一、硬件准备基本配置:操作系统64位CPU(英特尔)Intel(R) I3处理器内存8.00 GB ( 1600 MHz)硬盘剩余空间50G流畅配置:操作系统64位
今天看了spark的yarn配置,本来想着spark在hadoop集群上启动之后,还需要配置spark才能让yarn来管理和调度spark的资源,原来启动master和worker之后就会让yarn来原理spark的资源,因为我使用了spark和hadoop集群的高可用,可能是不是这个问题呢,还不太清楚,暂且记住,等我再研究研究因为我使用zookeeper集群来进行管理,所以我提交任务
在Yarn上运行spark-shell和spark-sql命令行
执行语句:sudo spark-submit --master yarn--driver-memory 7G --executor-memory 5G --executor-cores 24 --num-executors 4--class spark.init.InitSpark /home/hxf/gogo.jar>/home/hxf/dddd.txt2>&1;执行过程:
hadoop2.2.0 centos 编译安装详解(参考网上别人的改造下)1、安装JDK(没写自己参考百度) a.在/etc/profile.d/建立一个文件java.sh内容如下:#set java environmentJAVA_HOME=/usr/java/jdk1.7.0_60CLASSPATH=.:$JAVA_HOME/lib.to
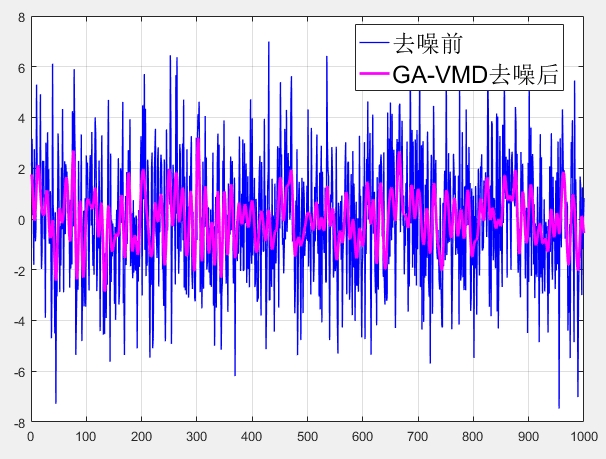
这次实验发现,用样本熵和信噪比构建双目标适应度函数,能比常规方法提升3-6dB的信噪比。这种方法的优势在于:通过样本熵抑制无效模态,避免将噪声成分误判为有效信号;同时信噪比指标确保整体去噪效果。这里采用信噪比(反映去噪效果)与样本熵倒数(表征模态复杂度)的组合指标。样本熵值越小,说明信号越规则,噪声成分越少。遗留问题:当强噪声导致原始信噪比低于5dB时,算法稳定性下降。下一步计划引入峭度指标构建三
Mac使用yarn+vite+ts实现前端、capacitor实现android、iOS跨平台开发
使用脚本实现hadoop-yarn-flink自动化部署
关于yarn的一切都在这里!
这是由于本机访问raw.githubusercontent.com网址有问题,需要定位一下网站ip然后修改hosts文件
【代码】记录一次yarn安装的时候报error Command failed.
今天要用mapreduce的wordcount时,yarn配置好了之后,要运行hadoop jar命令报出Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : 错误: 找不到或无法加
docker部署hadoop集群;通过Dockerfile方式构建hadoop容器;hadoop职责划分为NameNode、DataNode、NodeManager、ResourceNode、2NN;HDFS、MapReduce、Yarn测试。
解决 JCE cannot authenticate the provider BC
yarn
——yarn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



 AI Agent技术社区
AI Agent技术社区


 DAMO开发者矩阵
DAMO开发者矩阵
 MCP技术社区
MCP技术社区

 全球具身智能开发者社区
全球具身智能开发者社区
 AtomGit开源社区
AtomGit开源社区

 腾讯云开发者社区
腾讯云开发者社区